Inspiration
Palantir has recently released a language model-based platform that aids governments in their defense operations. We are currently experiencing an explosion of startups using language models for a diverse array of applications. We need assurances that language models arrive at their conclusions in safe manner that's aligned with human values. But, how can we reliably assert such assurances? Simply put, we don't know. We lack the foundational techniques necessary to asserting crucial assurances. My project attempts at both developing and applying techniques in mechanistic interpretability to understand how a language model generates text. One of the many assurances we want is that the language model is not making racially colored decisions when it would be harmful to. My project focuses on how language models generate text when the prompt involve race to move closer to providing this sort of assurance.
What it does
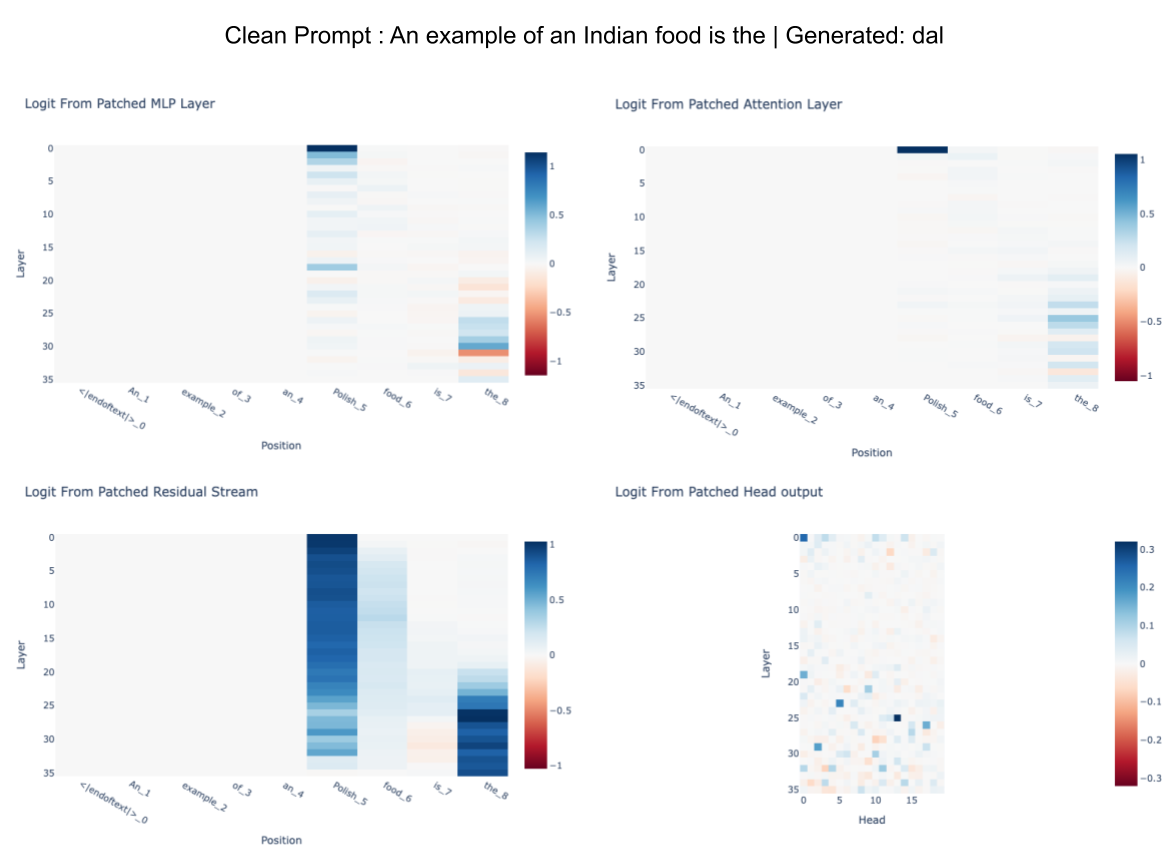
My project identifies specific components in the 700M parameter language model gpt2-large that are causally linked to the generation of select facts involving race. For example, I observed that a layer 18 MLP in gpt2-large strongly determines the generation of facts associated with "Indian." It then makes a basic attempt at linking these identified components to the decision-making process the language model takes when faced with a prompt involving race.
How we built it
I analyze the pertained model gpt2-large in a Google Colab environment. The primary tools I use are PyTorch and a mechanistic interpretability library called TransformerLens.
Challenges we ran into
- Implementing and figuring out how attribution patching works
- Putting "interpreting facts involving race" into the attribution patching framework
- Finding simple prompts involving race that a gpt2 model is capable of expressing explicit facts for
- Memory management when handling a 700M parameter model in Google Colab
What we learned
- How to use TransformerLens
- How Attribution Patching works and how to apply it
- Memory management in PyTorch and Google Colab - moving between CPU and GPU, scope, avoiding references
- Hands-on understanding of relation between model size and capabilities

Log in or sign up for Devpost to join the conversation.