-
-
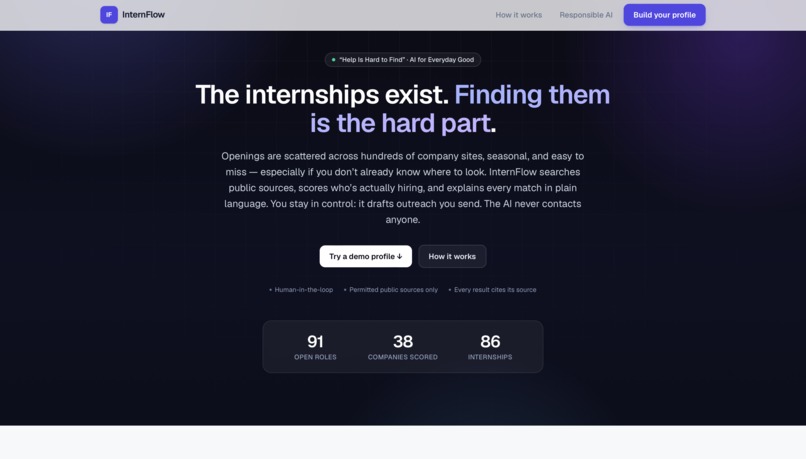
Homepage — Help is hard to find: internships are scattered and hidden. InternFlow finds them.
-
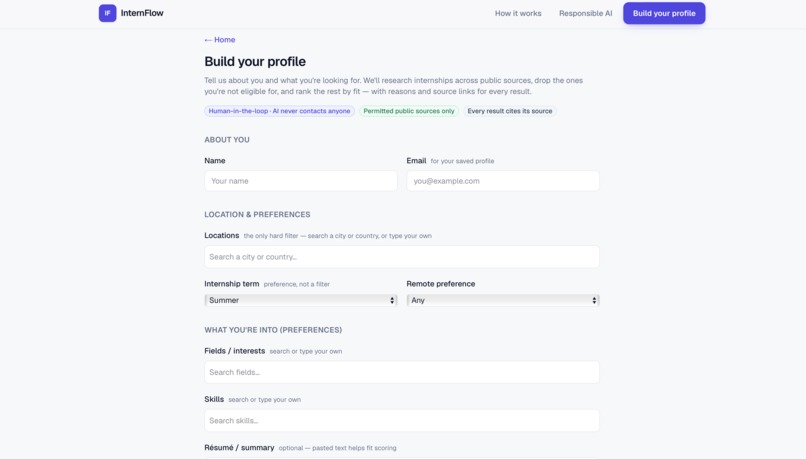
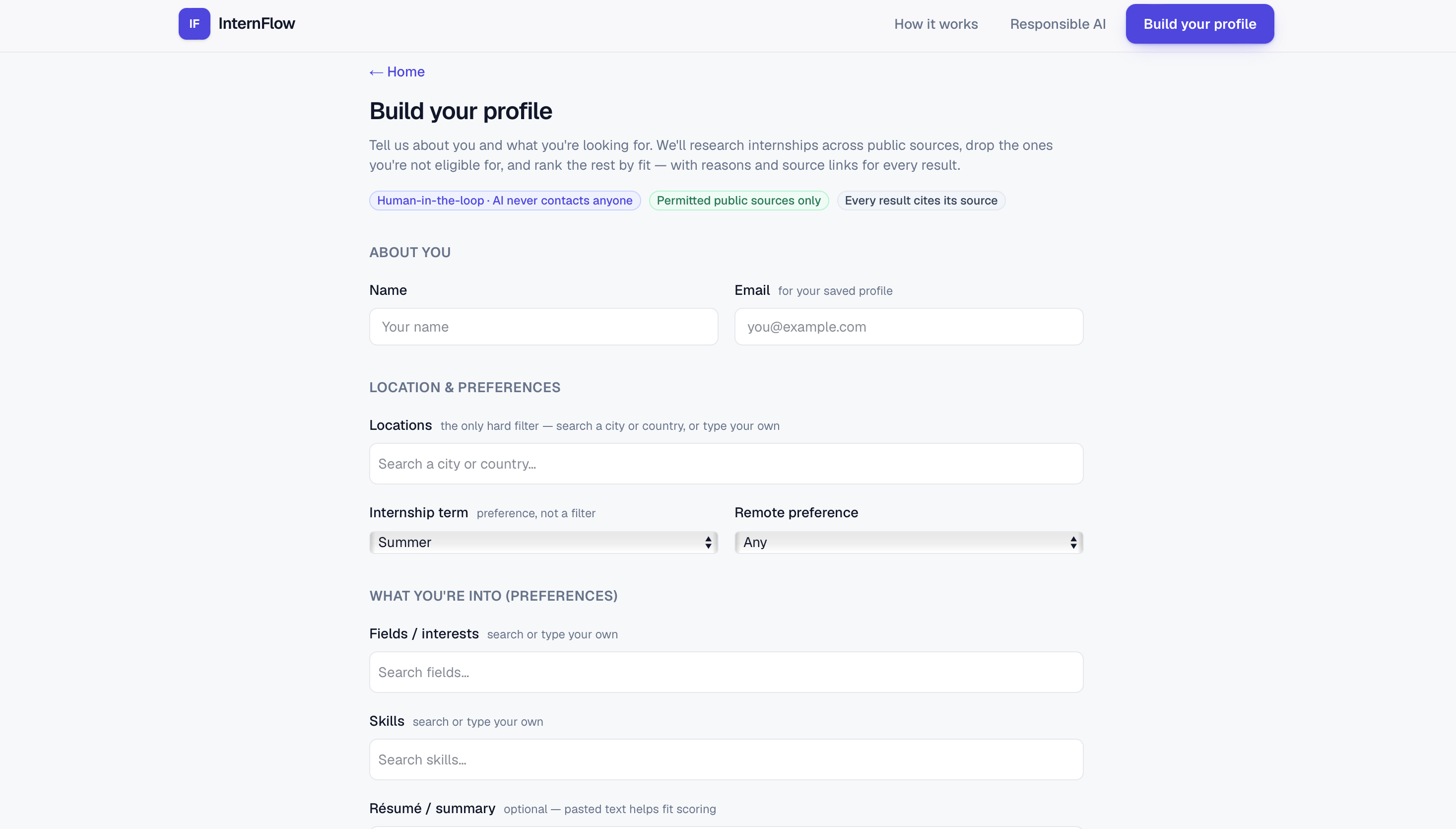
Build your profile — Tell InternFlow about you; it researches and ranks the rest.
-
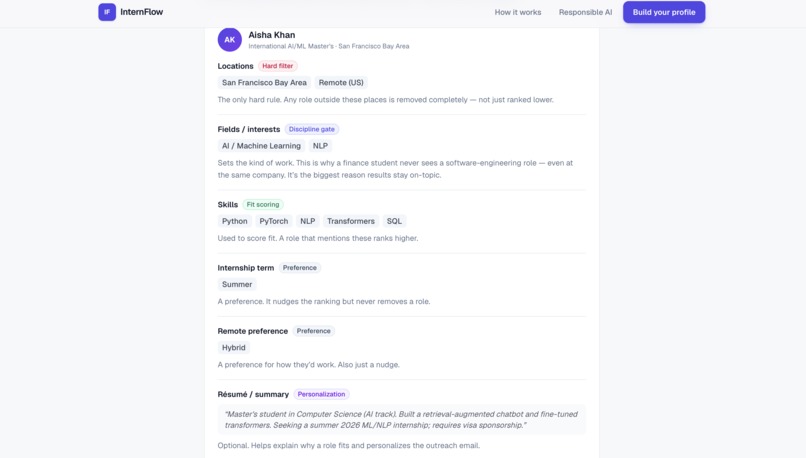
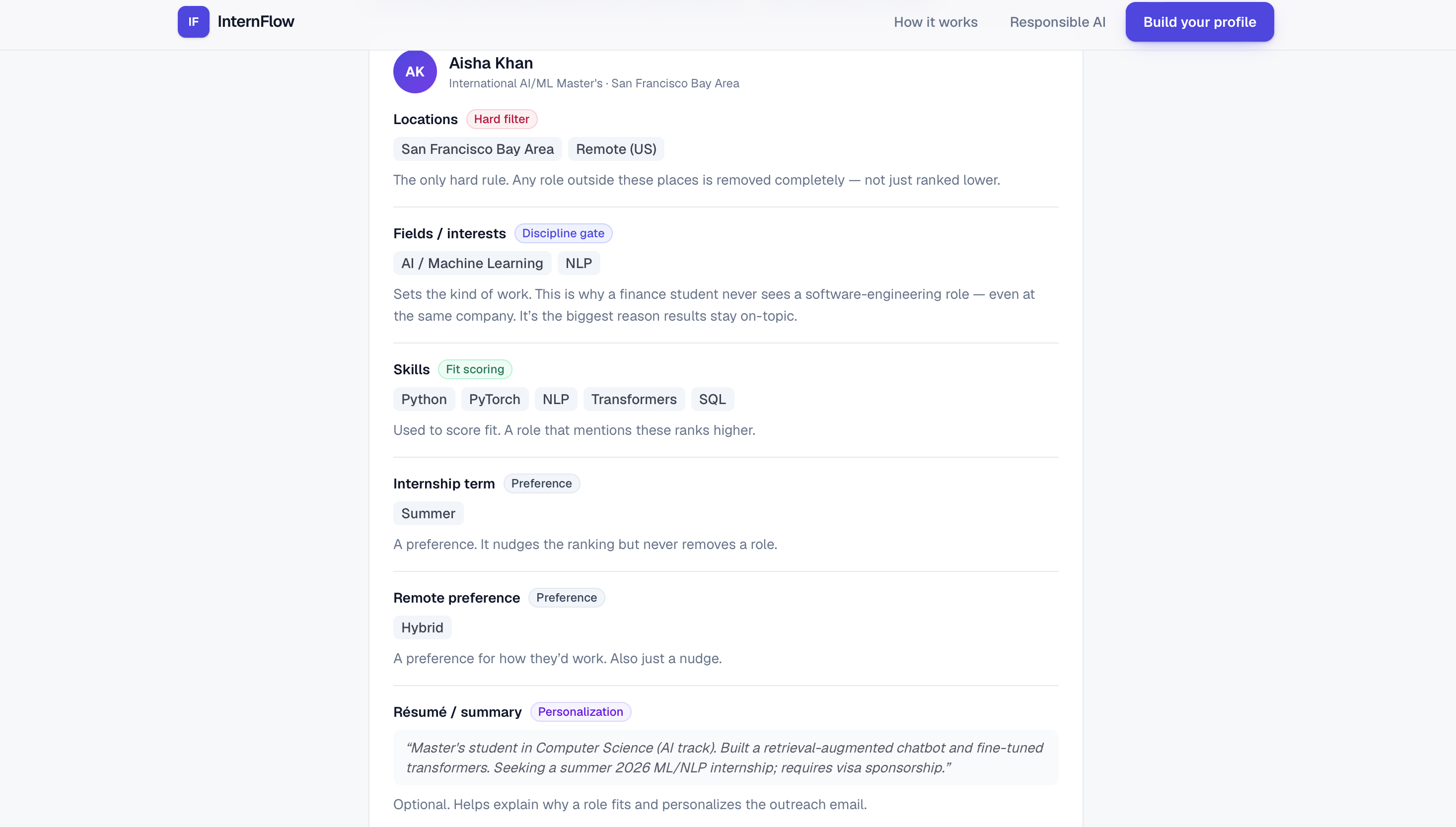
Profile breakdown — Hard filters vs. preferences — exactly how each answer shapes your results.
-
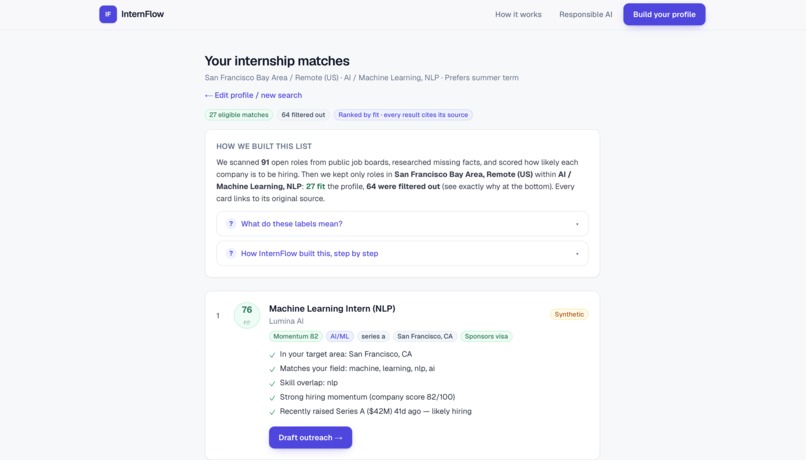
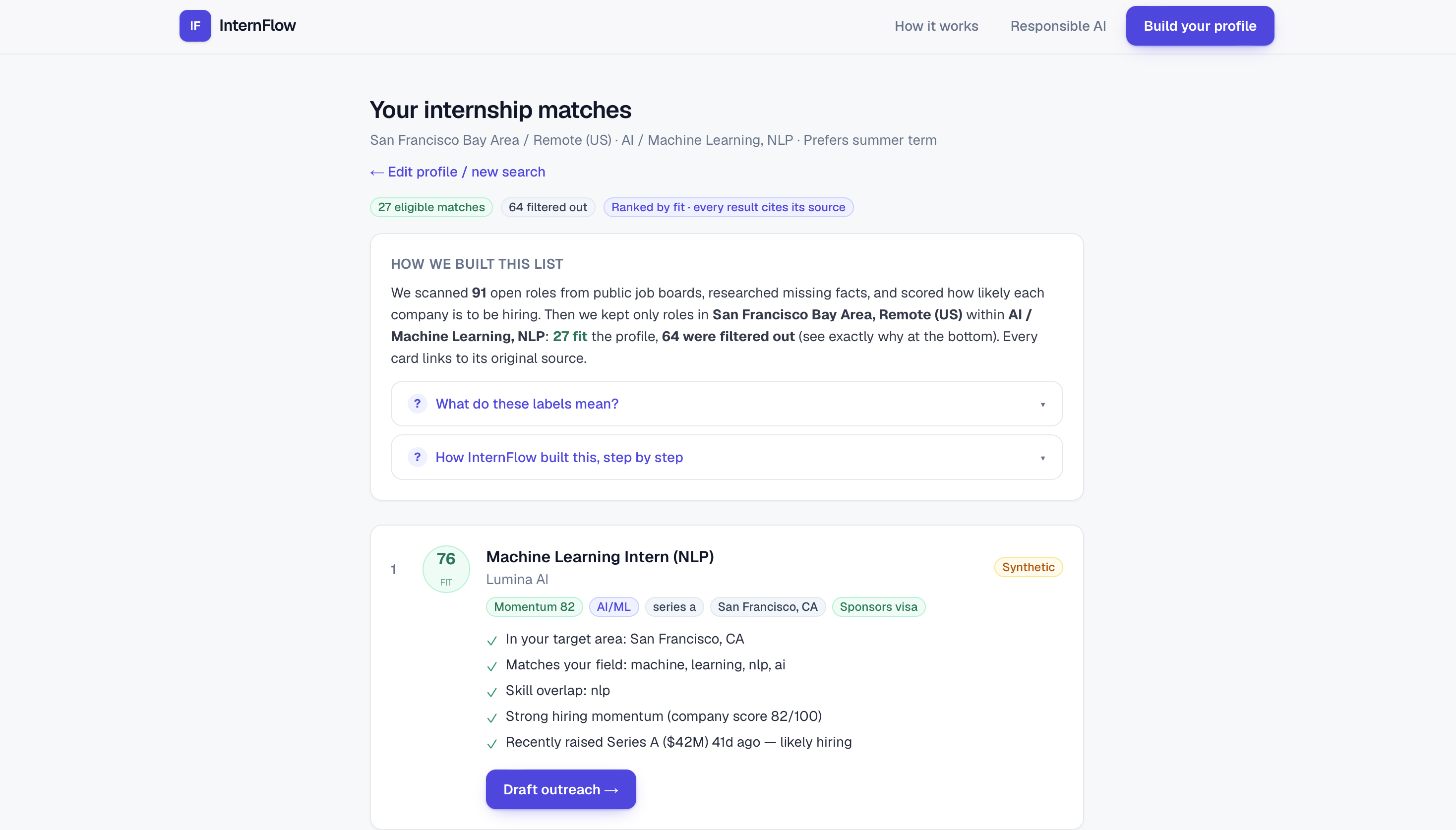
Matches — Ranked by fit, with every result explained and sourced.
-
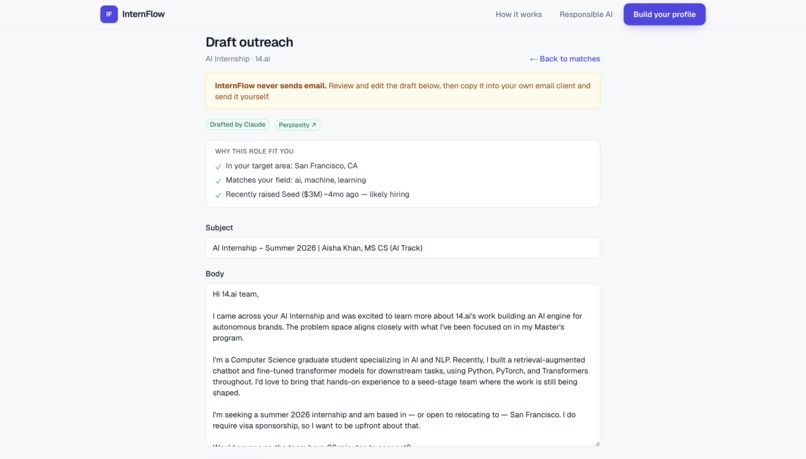
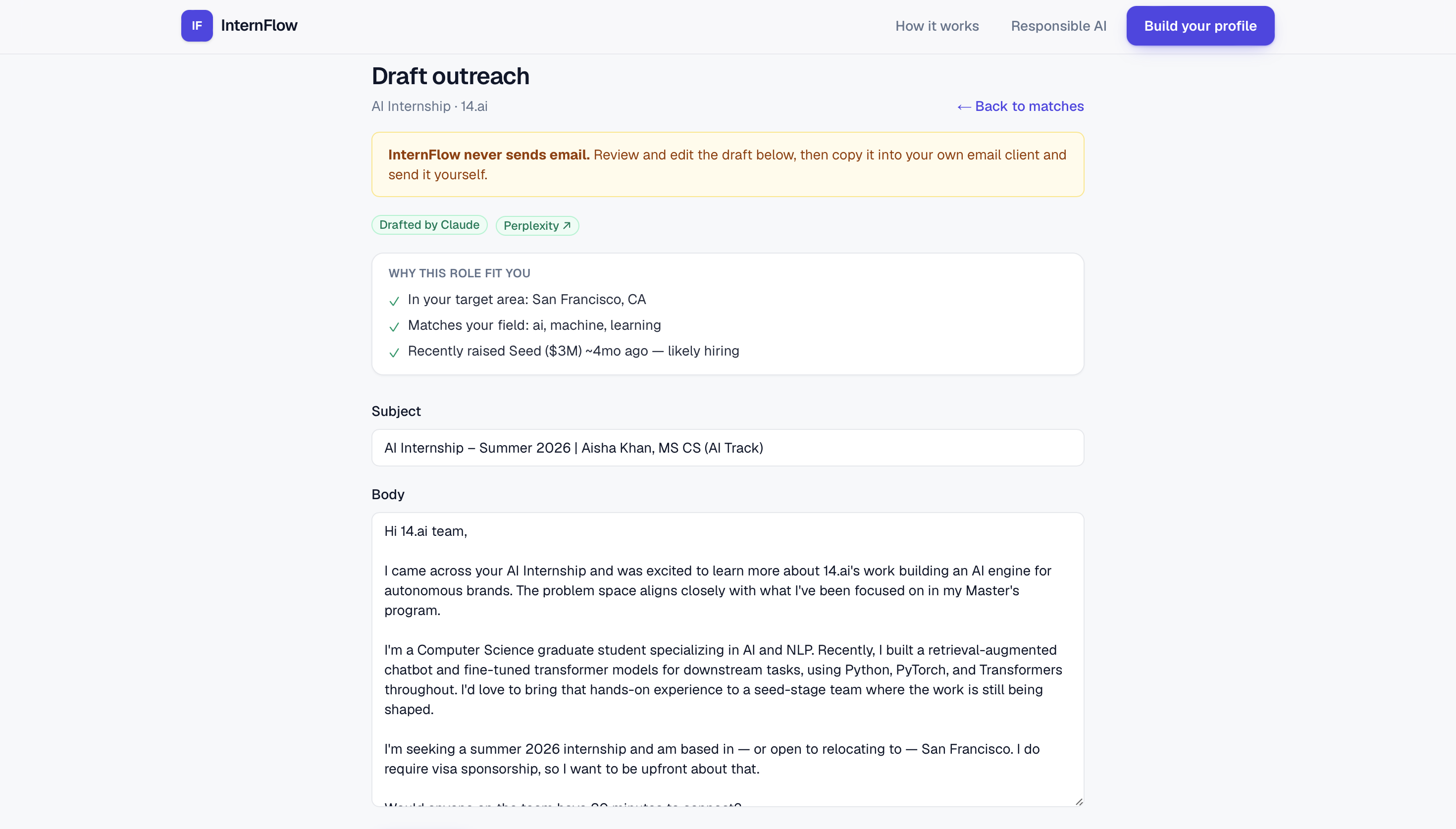
Outreach draft — Outreach to a funded startup InternFlow discovered — drafted by AI, sent by you.
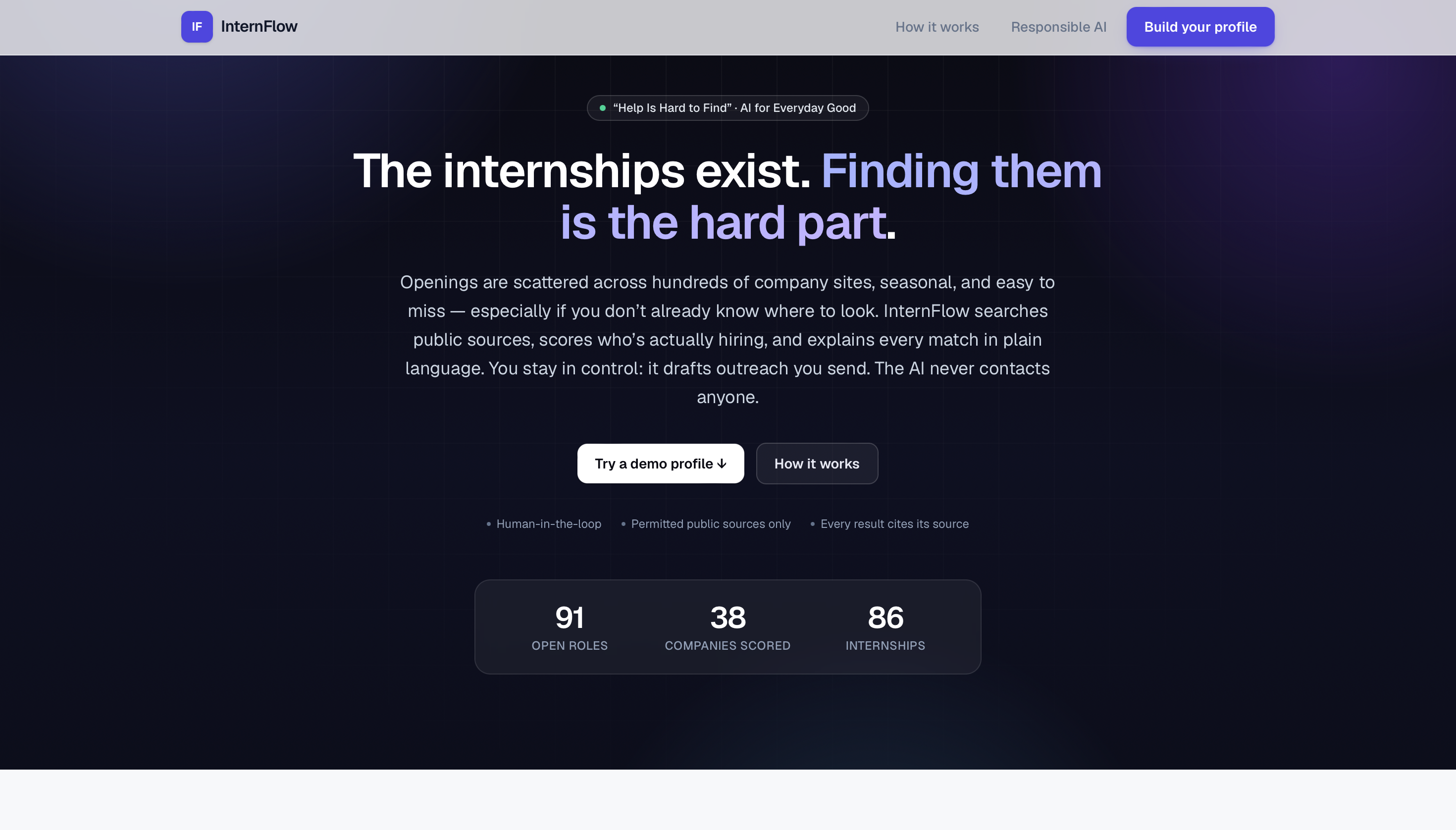
Inspiration: Every year students miss internships they'd have been perfect for — not because they aren't qualified, but because the opportunities are hard to find: scattered across hundreds of company job boards, hidden at startups that just raised money and haven't posted yet, and gone before anyone hears about them. A Google search returns ten generic links — it can't tell you who's actually hiring or why a role fits. That's the "Help Is Hard to Find" problem, so we built an agent to solve it.
What it does: InternFlow is an AI research agent that finds internships for a student and explains every result. Researches across sources — pulls live roles from public job boards, then does web research to surface companies that aren't on any job board yet. Scores who's actually hiring — a 0–100 hiring-likelihood score from public signals like recent funding. Matches and ranks, with receipts — drops roles you're not eligible for, ranks the rest by fit, and shows a reason and a source link on every result. Drafts outreach you control — writes a personalized intro email from your résumé; you review, edit, and send it yourself. The AI never contacts anyone.
How we built it: Next.js on Vercel, with a Turso (libSQL) database split into a shared public-data cache and private per-user profiles. Live roles come from public job-board endpoints (Greenhouse, Lever); a web-grounded research model (Perplexity Sonar via OpenRouter) enriches and discovers off-board companies; funding signals draw on public sources like SEC EDGAR; and Claude generates the match reasons and outreach drafts. Every researched fact stores a citation.
Challenges we ran into: Honest discovery — off-board companies are labelled "likely hiring — check careers page" with a real source, never a fabricated listing. Cost-safety — research runs as a backend step with a cache and a kill-switch, not on every request. Freshness — stale postings ("~26 months old — almost certainly filled") are filtered, not shown as open. Scope — going deep on one working flow instead of wide on many.
Accomplishments that we're proud of: A live, working pipeline — not a mockup. Off-board discovery of recently-funded startups with citations (something a scraper can't do), full explainability (why each match ranked, why each filtered role was removed), and a personalized outreach draft with the human kept in control.
What we learned: Why an agent beats a scraper: a scraper lists what's already posted; an agent reasons across sources, scores hiring intent, finds what isn't listed, and explains itself. And that Responsible AI is a design choice — human-in-the-loop, cited sources, and labelled data shaped every feature.
What's next for InternFlow: Tune the hiring score so funded startups rank as highly as they deserve, verify discovered postings against live listings, broaden sources, and sharpen accessibility for the students who need this help most.
Built With
- anthropic-claude
- greenhouse-api
- libsql
- next.js
- node.js
- openrouter
- perplexity
- react
- sec-edgar
- sqlite
- tailwindcss
- turso
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.