

Inspiration
As companies scale and employees come and go, important knowledge is spread across different sources (Email, Notion, Slack, Jira, etc) and difficult to find and synthesize. InternalAI seeks to solve this problem.
ChatGPT has proven to be a popular interface for interacting with large language models. However, while ChatGPT is great for general purpose text generation via natural conversation, it is not great for interacting with specific or private data. Common techniques like passing data as context to the LLM break down as the specific data you want to ask about scales, since LLM "memory" is limited (around 4k-8k tokens).
ChatGPT on its own would therefore be useless for the actual business problem of internal knowledge fragmentation.
What it does
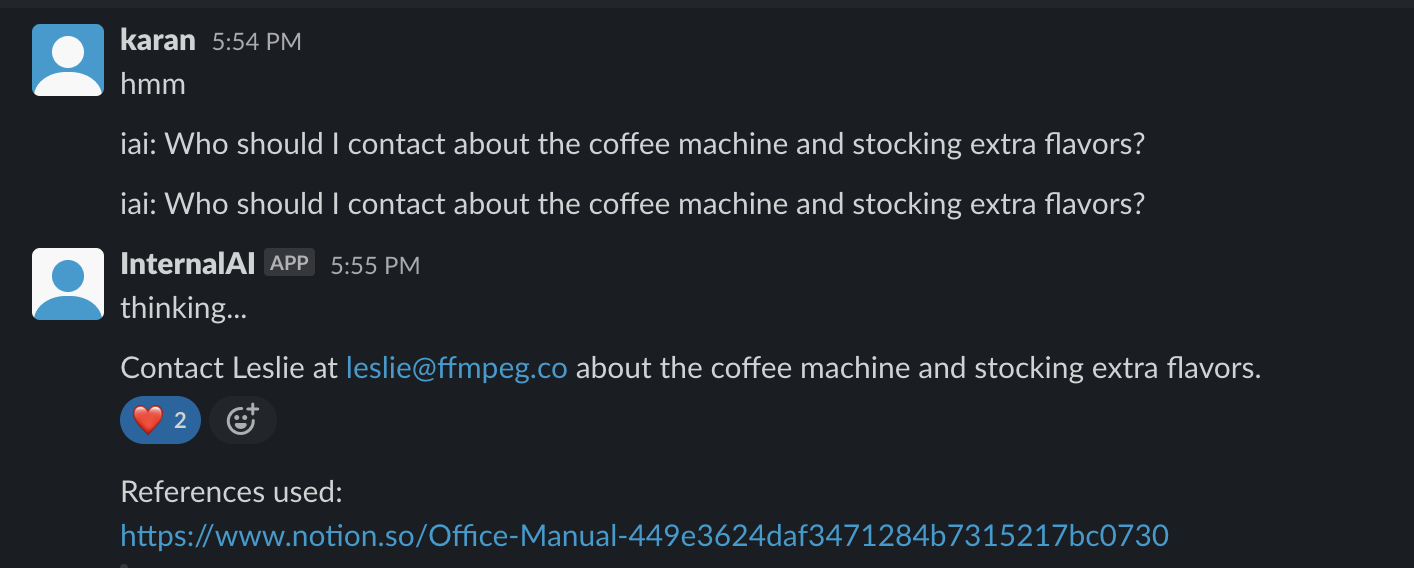
InternalAI is an internal business intelligence tool that gathers information across all sources of knowledge at a company (Notion, Slack, etc) and lets employees easily ask for answers. First, it syncs all your internal knowledge data via integrations. Then, through a chatbot interface, any employee can ask InternalAI questions about anything related to the company (company policies, business metrics, etc). InternalAI will then synthesize an answer to the question even if the knowledge is spread across different documents.
How we built it
Data ingestion: We first retrieve all company documents via various APIs (i.e Notion API). Then, we create embeddings of these documents via the OpenAI Embedding API. Once we have the embeddings, we can make our vector database. We use Facebook's FAISS library to cluster the embedding vectors together and create the vector database. We also separately make an in-memory database of documents (content and metadata).
Question-answer step: When a user asks a question, we first make an embedding of the question via the OpenAI Embedding API. Then, we use a extremely fast similarity search on our vector database to give us the documents most relevant to answering the question. Once we have the most relevant documents, we use a prompting technique similar to map-reduce. For each relevant document, we ask GPT3 to retain specific information that could be relevant to answering the original question. Then, we combine those intermediate answers, and ask GPT3 to synthesize a final answer (with sources).
Challenges we ran into
A big challenge for us was helping GPT-3 understand context outside of the small chunks of relevant information it was pulling from each document. This led to situations where searching for "How much am I allowed to expense for dinner in the office?" pulled up "Dinner - $100" from an expense document on Notion, but missed the context right above that which noted "The following expense caps are for events". By changing to our own content-combo prompting which not only pulls relevant information but also summarizes the entire document, we were able to significantly increase accuracy on these edge cases. Therefore in our final combo prompt, GPT-3 would have the context that a particular number referred to expensing for events, while a different document showed the total expenses allowed for dinners in the office.
Accomplishments that we're proud of
Our team had minimal experience with GPT-3 (and LLMs in general) and were pretty frustrated at first when realizing that re-training on a large corpus of documents wasn't possible to build out our idea, and the limited number of tokens in prompts limited our input sizing. In just two days, with close to zero prior knowledge, we were able to learn about a variety of interesting ways to leverage those documents, build out a working demo, and even improve upon some of the solutions we'd seen used with our content-combo prompting.
What we learned
We learned quite a bit about the cost/accuracy balance across many different LLMs. Since we actually prompt GPT3 multiple times for the same question, (First for context & summarization, and then for building the final answer) we spend quite a lot of tokens to answer one question. Embeddings are also expensive to create across a large amount of documents. We experimented with multiple text and embedding models (Cohere, OpenAI ada/babbage, and more), but either performance decreased significantly or there were token limits. So we ended up using OpenAI embeddings and text-davinci-003, which are both quite expensive but product results of significantly higher quality.
What's next for InternalAI ⏩
While powerful as-is, there are couple considerations to make for us outside of just adding more simple integrations.
- Employee permissions on documents (certain employees can access only certain information).
- Trust based document ranking (there's often conflicting information across knowledge sources, how do we rely on the best available data).
- Increase speed (a good start might be caching summaries of often referenced documents).

Log in or sign up for Devpost to join the conversation.