-
-

1. Knowledge Map on Scientific Papers - Connected by similar topics
-
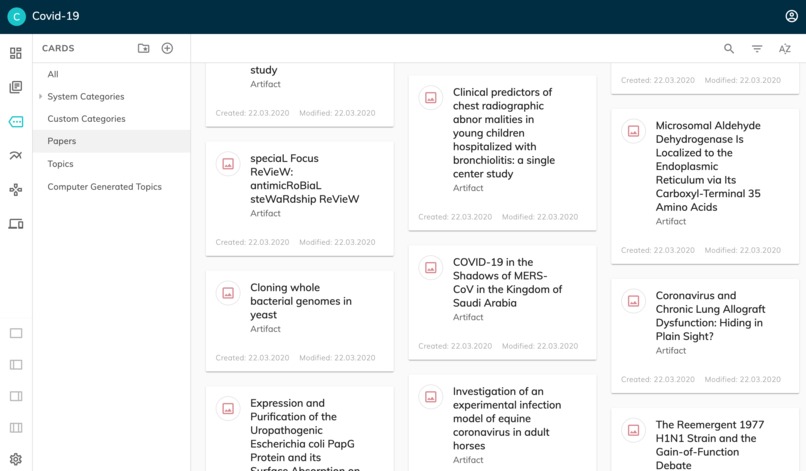
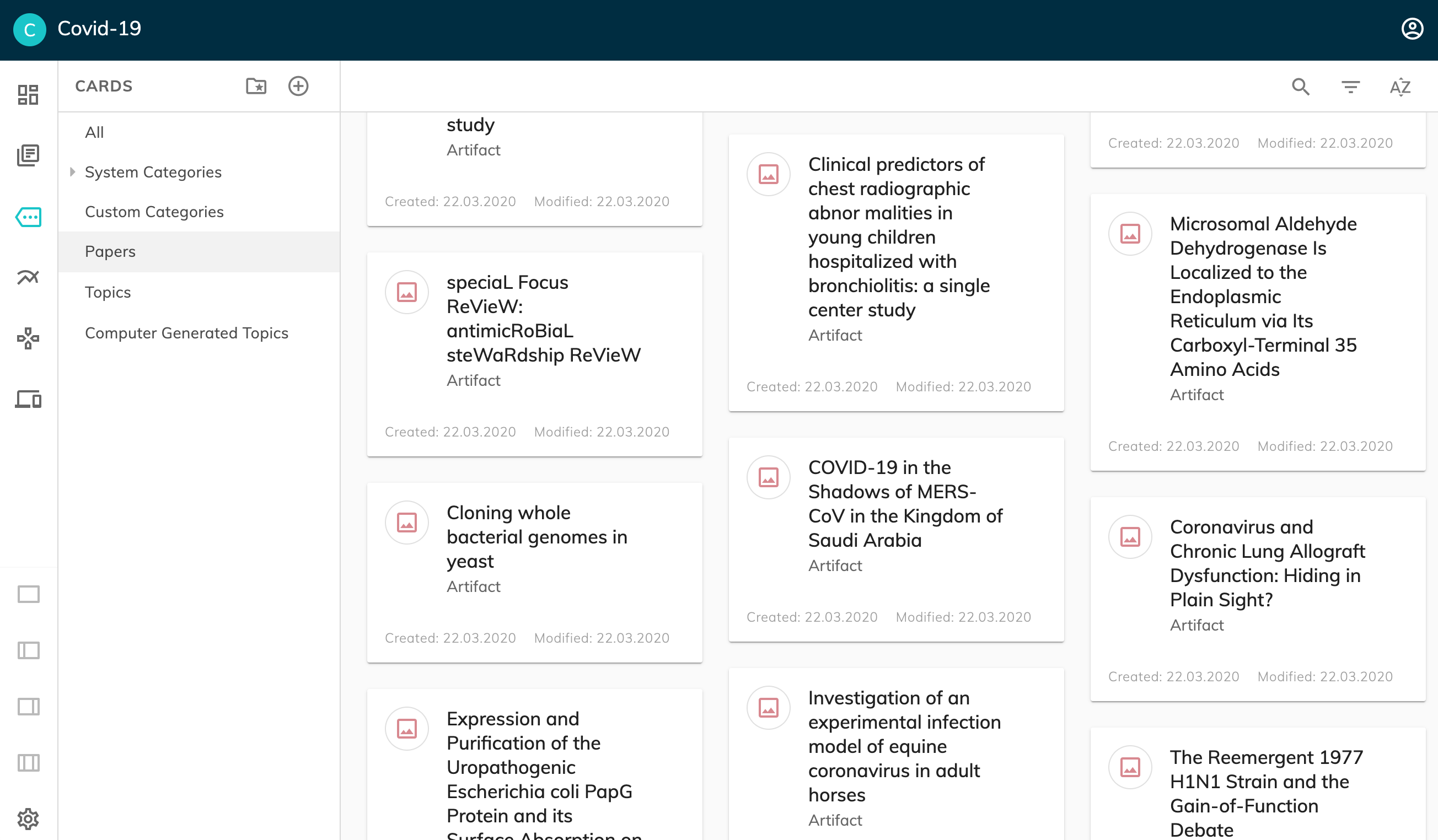
2. Access to Papers
-

3. Computer Generated Topic
-
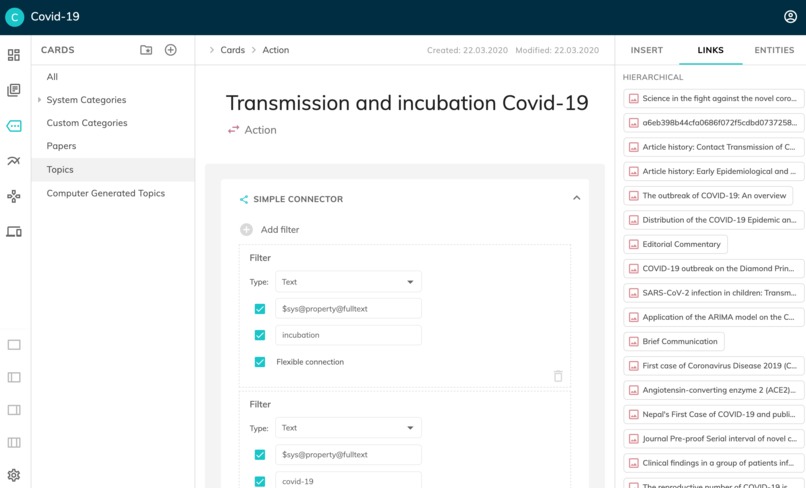
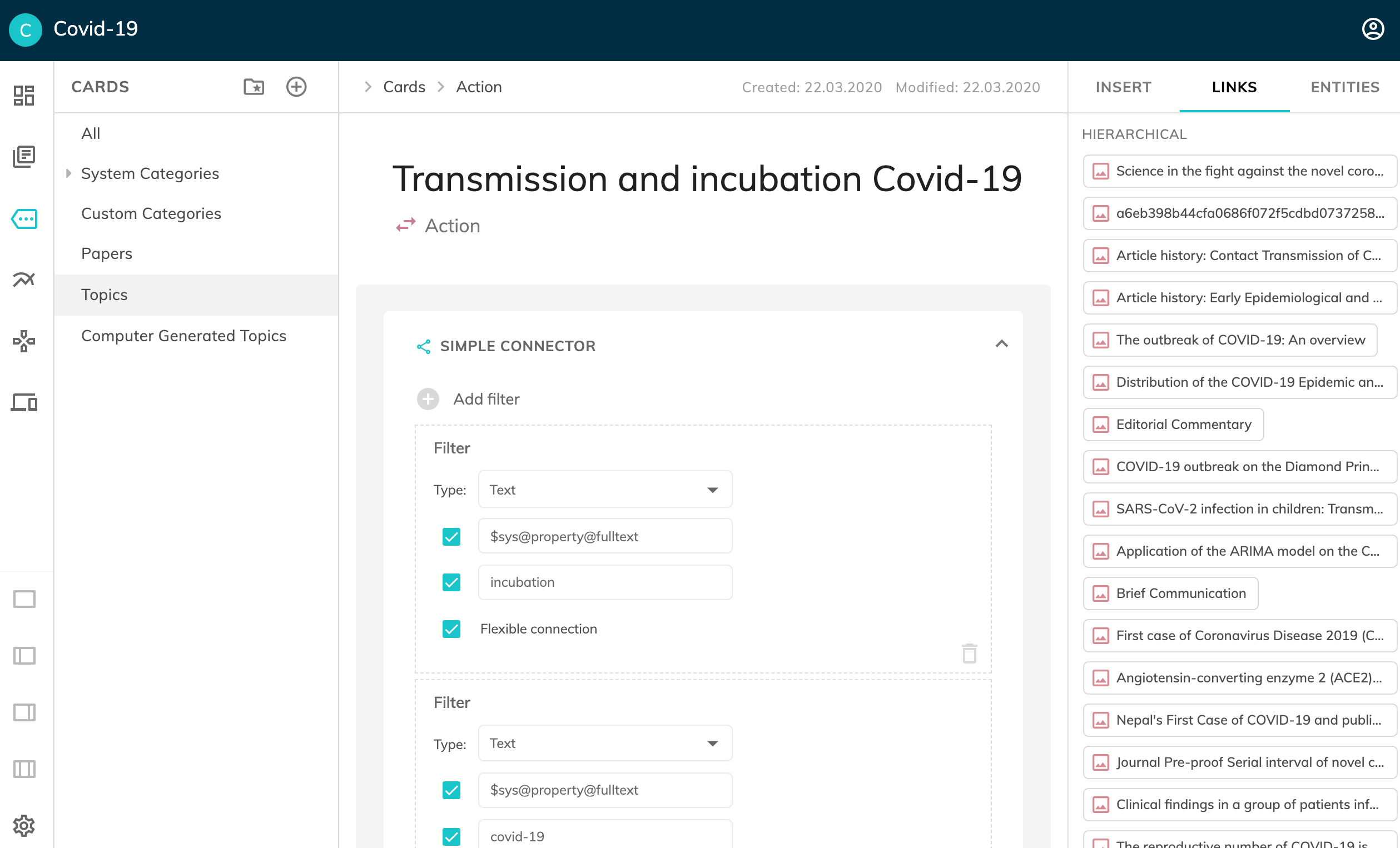
4. User Defined Topic


Inspiration
Contributing to find a solution to this enormous challenge is our inspiration and motivation!
We've been developing a data-driven platform for the cultural sector in order to support curators and educators of cultural institutions to understand and acquire insights from digital collections. Because of the urgency concerning the current situation with the COVID-19, we have decided to take part in the hackathon and repurpose our platform to help researchers to find hidden patterns in the scientific literature. Also, especially for this hackathon, we have worked on a little API that uses unsupervised ML in order to cluster papers based on sets of co-occurrent terms. We're making the code available on GitHub.
Problem & Solution
There are approximately 2.5 million new scientific papers being published each year. Some of these papers might be key to solve critical problems we face, such as the COVID-19. When the human brain start having difficulties in keeping up with amount of information, AI can provide a helping hand! Our goal here is to enhance scientific work by utilizing AI as an assistant to cluster and sort literature.
The Nitty-Gritty
We have used a subset of 13k papers from the CORD-19 (https://pages.semanticscholar.org/coronavirus-research).
With the algorithm published on GitHub (https://github.com/leonardomra/topic-modelling), we have identified 50 topics that segregate the scientific material.
Not only the results obtained from the model were imported into our platform, but the papers as well (see slideshow pic. #2 - computer generated topic).
Topics created by the AI are defined by a set of terms. For example, "Topic4" is defined by the keywords: "gene", "virus", "mutation", "sequence", "genome", "variant", "host", "region", "strain" (see slideshow pic. #3 - computer generated topic). Based on the keywords found, the platform then filters the papers that fit the criteria.
Users are also able to set their own topics. For instance, we have created a topic named: "vaccine for covid-19" and defined "vaccine" and "covid-19" as filters. Every new paper inserted into the platform that contain both terms is automatically linked to this topic. Other topics were also created: "transmission and incubation of covid-19", "risk factors for influenza pandemic", "medical care in case of covid-19", etc. (see slidehow pic. #4 - user defined topic).
An overview of the connections among the publications and topics can be seen by generating a Knowledge Map (see slidehow pic. #1).
Next Steps
As a future step, we will implement an API service that can be integrated in different platforms.
The further improvement of the model is also expected. The right evaluation on the quality of the results should come from experts from the field. Therefore, help on that is welcome!
We will enrich further the metadata on the papers. We consider the extraction of metadata on e.g. locations to be relevant, since pandemics have a close relationship with the space where they spread. In this sense, other kinds of visualizations and insights would be enabled.
Other kinds of strategies can be also used in order to enhance the quality and interoperability of the dataset, such as Ontology Linking based on extracted terms.
Finally, before we open up the API services to everyone, we need to make sure we have adequate infrastructure. We're looking into that. For immediate access, please send me a msg!





Log in or sign up for Devpost to join the conversation.