Inspiration
I wanted my readers to be able to provide more value to the readers of my book (Angular Cookbook). And to make my book's website more interactive.
What it does
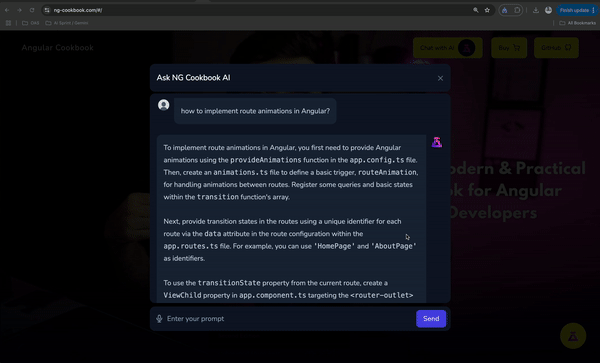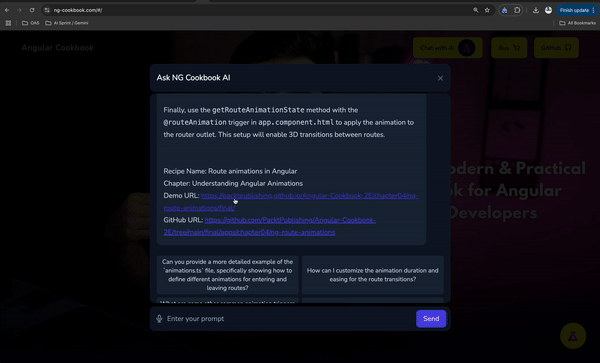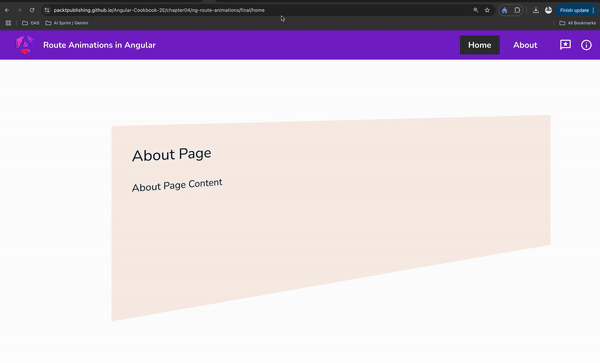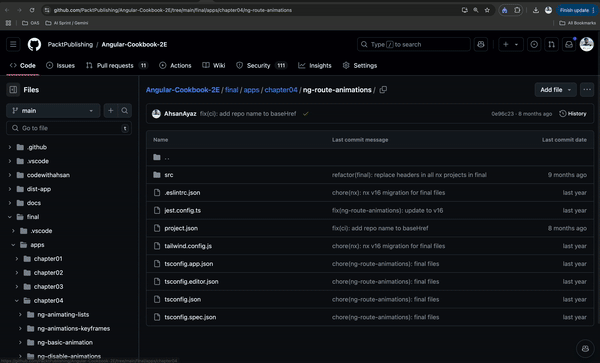
The website https://ng-cookbook.com now has "NG Cookbook AI". It is an AI chat bot which users can ask any questions about the Angular Cookbook. They can ask about Angular Signals, Unit Testing in Angular, End to End tests, Performance Optimization, and what not. It gives the readers the ability to follow up on their reading, or ask potentially any errors they're facing. When a user asks about a generic question about Angular which the book doesn't talk about, the chat bot responds with the knowledge from Google Gemini 1.5 Pro model. If the asked topic is covered by the book, the book not only gives a generic (detailed) answer, but also the following:
- Link to the demo URL of the project (deployed on GitHub pages)
- Link to the exact folder in the GitHub repo for the project
How we built it
I used Google Gemini 1.5 Pro as the LLM, the text-embedding-004 model for creating vector embeddings from the context data, LLamaIndex for implementing RAG (Retrieval Augmented Generation), and Python & Fast API for the backend APIs and using the models and RAG.
For the frontend, I used Angular, and for the backend, I started with the python project from LlamaIndex.
I provided the PDF version of my book to the data folder of the project and it was able to generate the Vector Embeddings pretty nicely. However, for the links, and the URLs, I had to go a bit above and beyond. I created a JSON file containing an array of the mappings of every recipe (project) in my Angular Cookbook with its demo URL, and the source code's link on my GitHub repo.
Challenges we ran into
Being an AI and python newbie, it was quite tough for me to get everything set up. The first challenge was just getting started in general. I was fortunate to stumble upon LlamaIndex to be able to come up with a plan to use RAG with Google Gemini 1.5 Pro. The next challenge was to understand the LlamaIndex's python project to see how RAG is implemented in there. Once I explored the codebase, and tried and failed a few times, I was able to understand how everything worked. However, the main struggle became getting the right Demo URL and GitHub source code URL for a particular topic the user is asking about. At first, I thought that JSON doesn't work with the data folder where I had my book's PDF. So I used the JsonReader from LlamaIndex, that improved the results. But my lack of knowledge about factors like TopP, and TopK was the issue. I was using a very low value (3), where the TopK chunks were just being returned probably from the book and the json wasn't taken into account (most of the time). I ended up using 50 (after some research) which works just perfect.
But how did I create a json of 96+ projects with their demo link and github link? Manually? Thank goodness, nope!
Thank you Google for having the AI Studio. I uploaded my book's PDF there and used structured responses and a bit of prompt engineering to have the whole JSON generated.
Accomplishments that we're proud of
- Providing more value to my readers
- Getting started correctly with RAG
- Having this deployed and working in production
What we learned
- TopK, temperature, TopP, and other factors that affect an LLMs response
- RAG and its use cases
- It takes much more time in trying, failing, and reiterating than the initial plan :) Almost always.
What's next for Interactive Content: AI-Powered Q&A for My Angular Book
- Ability for readers to provide feedback on specific recipe (projects) of my book
- People to participate in raffles using the chat bot in the conferences I'm speaking at to win a free copy of the book (already planned )
Built With
- angular.js
- gemini
- google-ai-studio
- llamaindex
- python
- rag







Log in or sign up for Devpost to join the conversation.