-
-

It can create workouts from complex natural language where some reasoning is involved.
-
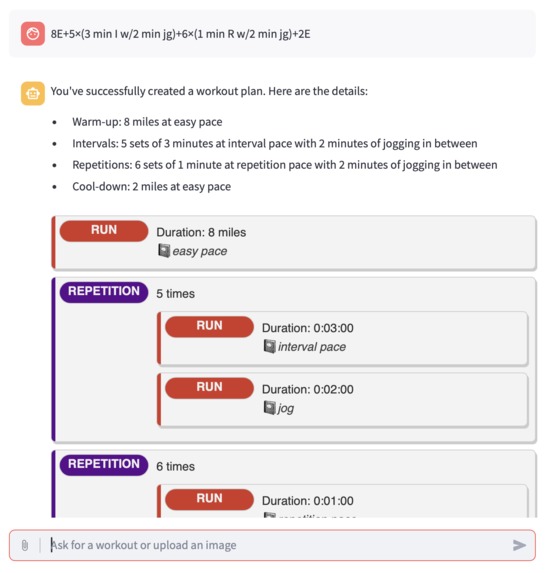
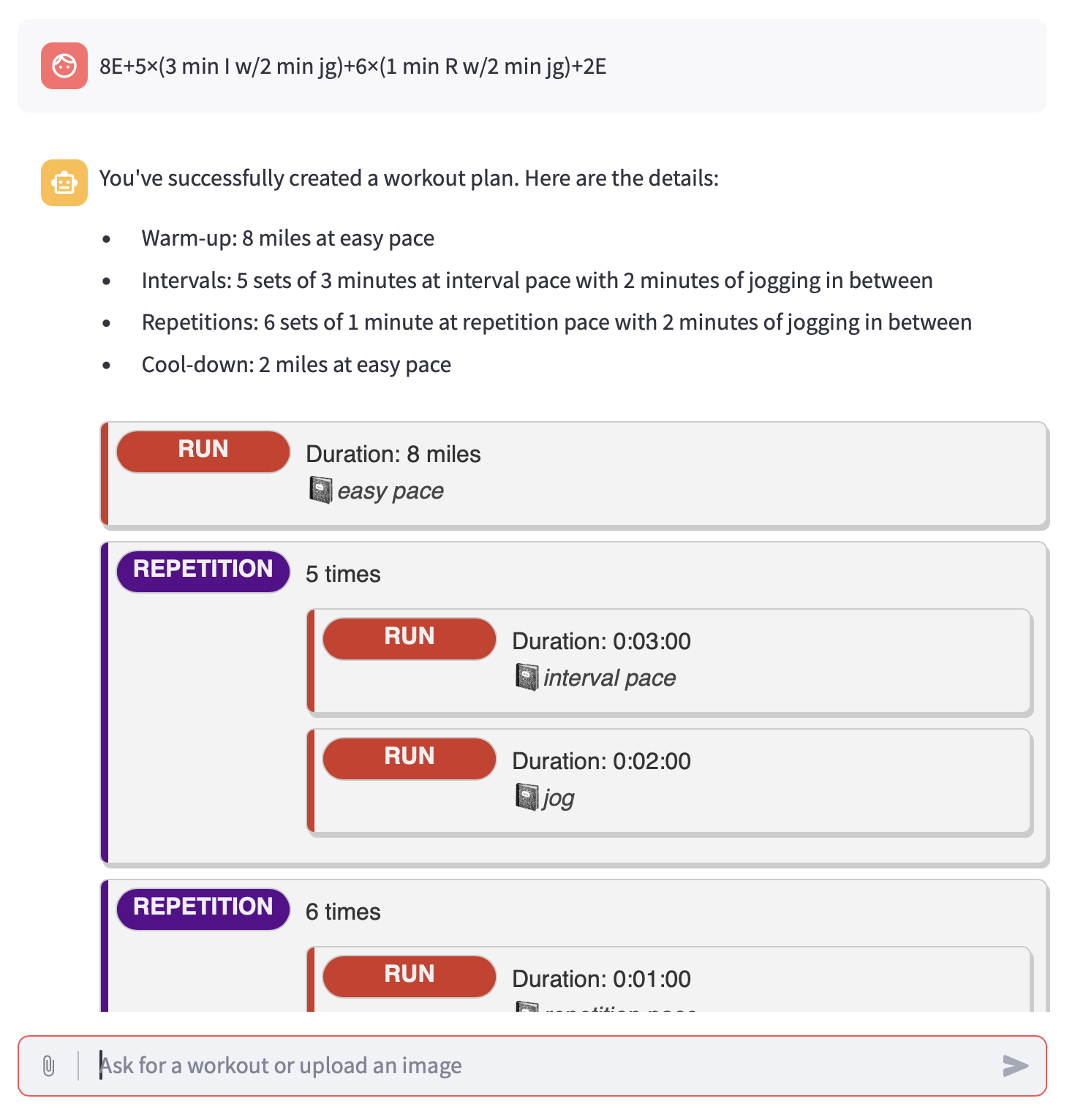
Shorthand, such as used by Jack Daniels, is also usable.

Inspiration
Structured workouts with many steps, such as track or interval days, are a core component of any endurance athlete's schedule. These can be simple intervals or complex, layered workouts.
While modern watches, such as a Garmin Forerunner, Apple Watch, or Google Pixel Watch, can easily track these steps and provide the wearer with the interval data, constructing these workouts remains incredibly constrained and complicated. This project eliminates much of that pain point by using NLP to quickly convert workouts specified in natural language into a structured format intelligible to a smartwatch.
What it does
This project takes a description of a workout expressed in natural language, either as text or from a photo, and converts it into a validated, machine-intelligible representation. This representation can then be used to generate the files that a watch understands, such as Garmin .fit, integrated into an iOS or AppleWatch app, or Google/Fitbit format. While this step is beyond the scope of this Hackathon and project, it is straightforward to go from the validated, machine-intelligible intermediate representation into any vendor-specific formats or code.
How I built it
This project is built primarily in Python 3 using LangChain (and LangGraph) calling various Meta Llama models hosted on SambaNova's fast cloud.
For interactions with the user, the project relies on LangGraph to safely constrain the system so that the user cannot perform arbitrary prompts. This enforces the rule that the LLM does not provide advice or answer general questions, which it otherwise happily would. The project uses Llama-70B-instruct to call into tools and provide natural responses to the user.
The project uses the much larger Llama-405B-instruct model to handle the actual construction of the workout from a natural language description. Smaller models adequately handle complicated, albeit straightforward, queries, such as:
Do a 5 minute warm-up. Try to keep the heart rate as low as possible and breathe easily. Follow this with 10 400s fast. Keep the turnover up, but don't stress it too much. Target 70 to 80s per lap. Float 200 meters between reps. Cool down with a 2 mile easy run. This should be as relaxed as you possibly can run it.
However, the Llama-405B-instruct model is generally able to understand and handle difficult queries such as:
Do a 5 mile warmup, then alternate between 800m at MP and 800m easy for 5 miles, finishing at the normal long run pace.
In the latter query, the system must understand that the combined 800m at MP and 800m at easy roughly equates to a 1 mile (1609.34m). It then has to use that information to create the repetition and set the number equal to 5.
The system for converting images into workouts uses Llama-90B-vision-instruct to find and extract as text possible workout plans inside a photo. Once the model returns an array of candidates, each candidate is passed to the Llama-405B-instruct model described above to handle the parsing.
Regardless of the source, the JSON output from the LLM cannot be directly used with a watch. There are several reasons for this:
I have purposefully allowed for more flexible representations that any of the current watch vendors support. The idea behind this is to mirror the user's intent closely. An excellent example is allowing for multiple sets, each of which may have a nested repetition. This structure can easily be flattened in software but better matches the user's mental model.
The JSON from the LLM may be invalid or may have invented keys.
The user may not have properly specified a workout or the workout may be missing critical values. In this case, an intermediate representation can hold the incomplete workout while the user is queried to supply the missing values. Sadly, this part of the process is still being developed.
Because of these reasons, the JSON from the LLM is passed into a JSON decoder (validation) to construct an intermediate representation using native Python objects. These objects can then be validated and manipulated to generate a file that actually can be handed off to the watch.
Challenges I ran into
Building a prompt that allows for flexibility and shorthand was challenging and required significant trial and error. While using a temperature of 0 is the standard advice for code generation and parsing, of which the primary extraction tools are a type, I have set the model to a slightly higher temperature to allow for summarization. This is necessary to properly handle the complex query, such as imputing the number of repetitions of the alternating 800m steps above. Queries of this variety require asking the model to perform some "logic," which is aking to summarization and thus requires that the model be able to diverge a bit from a strict interpretation. At the same time, setting the value too high will cause the model to take too many liberties, generating invalid JSON, hallucinating steps in the workout, or otherwise misbehaving.
I also encountered difficulty in the construction of different tool calling prompts because it is a challenge to restrict the model to mostly call tools yet be able to include a history for a more natural chat style.
The "agentic" component is less developed than I'd have liked because I'm just starting to understand how to work with tool calling and history in a constrained, multi-agent system. I separated the JSON parsing calls from the primary agent to keep things safe and the prompt reasonable, but unfortunately, this means that calls into the history, such as "Can you make that 10 reps instead of 5?" do not currently work. Right now, the modifications available are quite simple, such as requesting and changing the name of the current workout. With more development, additional tools can easily be added.
Accomplishments that I'm proud of
The parsing part generally works surprisingly well! Generating the prompt rules for converting ambiguously described workouts, often loaded with jargon and abbreviations, into a respectable abstract tree is pretty amazing. Is it perfect? Nope. But it is amazingly fast compared to manually entering the steps on Garmin Connect. (Nothing against Garmin; I love my watch. It's just a consequence of the visual programming approach).
I am particularly impressed by the model's (and prompt's) ability to handle rather difficult imputation problems, such as the alternating sequence described above. It also beautifully handles ladders, such as "200m to 1600m by 200m", which is ordinarily tedious. The ability to understand sets also makes this far faster than any manual counterpart, even if they supported copy/paste, which none do, for some odd reason.
What I learned
This is my first time interacting directly with the LangChain and Llama system, and I'm quite impressed. I still don't trust the LLM to "do the right thing," but it is far more interesting and fun to interact with than I initially anticipated. While I'm still figuring out the right way to interact with tools, history, and prompts, it has given me a lot to consider for potential future projects.
What's next for Intelligent Workout Editor
The next step is to work on generating more agentic manipulation and be able to generate the actual files. I'd like to develop the system more into something resembling production-grade code so that I can finally stop manually entering my workouts in Garmin Connect.
Built With
- langchain
- llama
- python
- sambanova

Log in or sign up for Devpost to join the conversation.