-
-
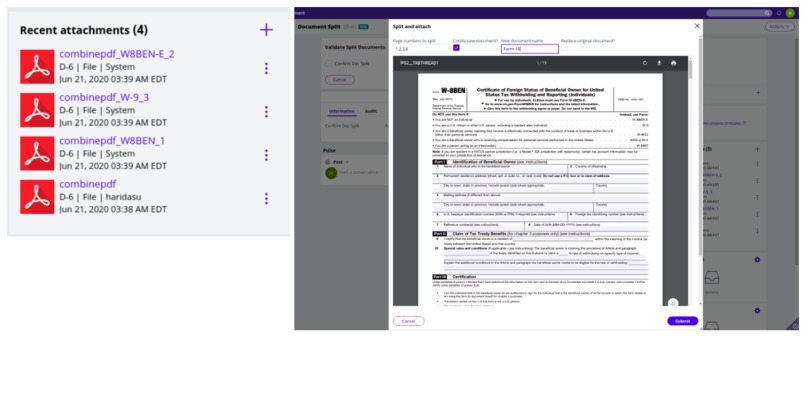
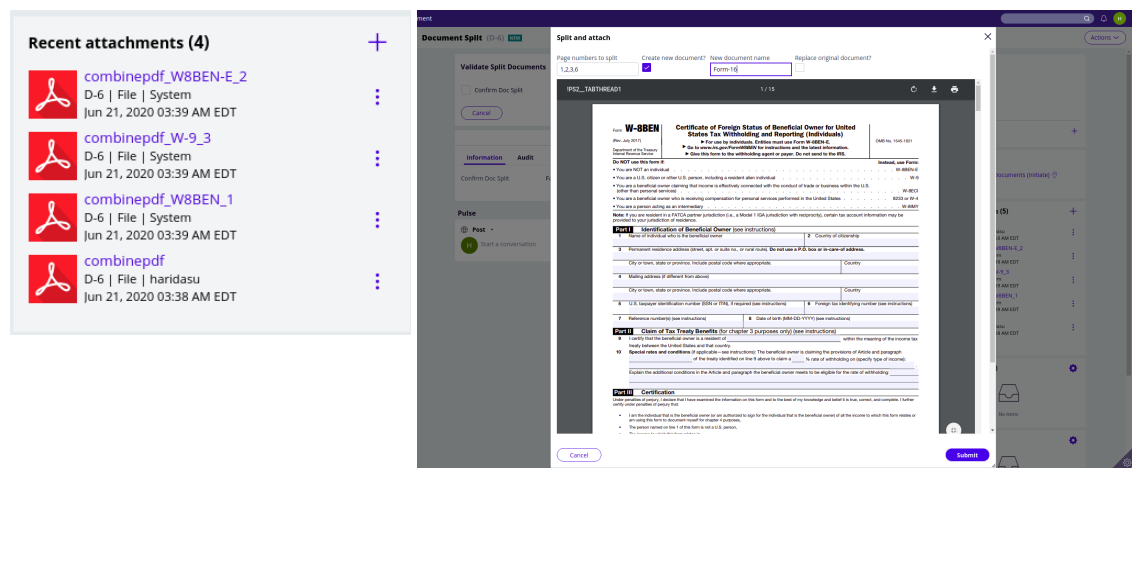
Auto splitter and splitter UI
Inspiration
The business problem we are trying to solve here is with managing consolidated documents. Let's take a scenario where a user has to deal with a huge consolidated document attached to a Pega case. Business frequently come across such scenarios and finding relevant information from a consolidated document is often time consuming.
Users might also have to rely on some third party software, to split the consolidated document, to pass on to other applications for further processing. This manual process is often time consuming and prone to errors.
What it does
Our component focuses on introducing great efficiency in this managing process. With this users only have to validate the documents and action on exceptions, thereby reducing lot of time, effort and cost.
Our component helps users by intelligently splitting a consolidated document, by using state of the art template matching algorithm, from Open C V., It recognises the type of each page, in a consolidated document, by using some predefined templates.
How I built it
Built on top of Pega, Python, Open C V, PDF Box and Ghost Script. Here our Pega component is responsible to invoke the python script, which does all the heavy lifting in the background. Python script makes use of Ghost Script, to convert any pdf document either scanned, or textual, into images and then hands it over to Open C V, which does the template matching. PDF Box component is useful in manually splitting the PDF document, in case of exceptions in automated processing.
Challenges I ran into
=> Acquiring knowledge of ML => Using OpenCV to perform template matching => Understaneding how image processing takes place => Using PDFBox to build an intituite UI => Calling python script from pega
Accomplishments that I'm proud of
=> Implemented image recognition => Implemented an intuitive UI to handle exception scenarios
What I learned
=> Learnt how OpenCV perform image recognition => Usage of ghostscript to convert any pdf document to a set of images => Usage of PDFBox to split PDF's => Calling third party libraries from Pega compoent
What's next for Intelligent document splitter and manager
Future scope of this component, is to introduce some feed forward mechanism, to automate the training of the image recognition algorithm.









Log in or sign up for Devpost to join the conversation.