-
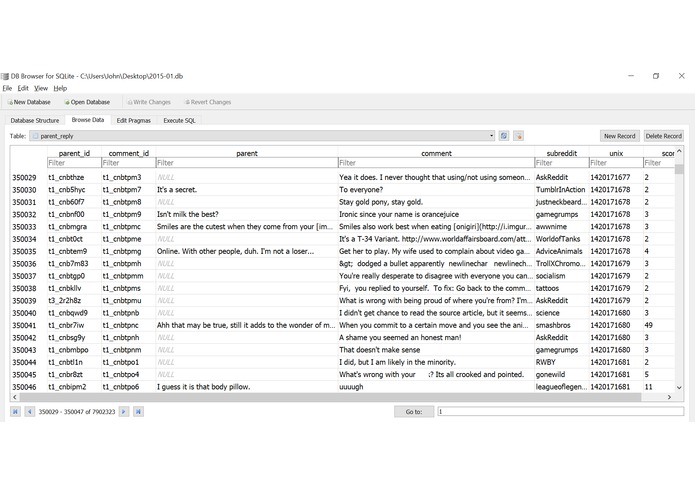
Database of clean and processed data used to train the model
Inspiration
I was very interested in creating a Chatbot that would have witty humor but at the same time be intelligent enough to provide logical answers to questions.
What it does
The idea is very simple. It is a Python CLI that takes in a input message from the user and performs softmax regression to match it up with the best answer from data in a database
Construction and Built
My part of this project was more related to the data science aspect - Filtering the data and manipulating the data from a bz2 file and storing the clean data in a database, ready to be used.
Cleaning the data
Creating the Table for Clean Data
CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT
Checking if the data is valid
I needed to make sure that all the data was valid in the sense that it hasn't been deleted, isn't too lengthy, or isn't too short. This was a simple function to implement.
def isAcceptable(data):
if(len(data.split(' ')) > 50 or len(data.split(' '))<1): #If data length is too large or too small, reject it;
return False
elif (len(data) > 1000):
return False
elif data == '[deleted]' or data =='[removed]':
return False
return True
Prioritizing Comments Based on Upvotes
I didn't want the Chatbot giving unintelligent answers that Reddit users simply write on a post. I wanted it to return the comment that had the most upvotes. I implemented the logic that did this
def find_comment_score(parentId):
try:
sql = "SELECT score FROM parent_reply WHERE parent_id = '{}' LIMIT 1".format(parentId)
c.execute(sql)
result = c.fetchone() #run query
if(result != None):
return result [0]
except Exception as e:
return False
Bulking CRUD operations in a transaction
def transaction(sql):
global sqlTransaction
sqlTransaction.append(sql)
if(len(sqlTransaction) > 1000):
c.execute('BEGIN TRANSACTION') #starts transaction
for s in sqlTransaction:
try:
c.execute(s)
except:
pass
connection.commit() #Ends transaction
sqlTransaction= [] #Clears transaction item queue
Main Program Logic
The main program had a very simple logic. For each row in the data, I would parse the data as JSON, and populate the database after cleaning the data.
if __name__ == "__main__":
create_table()
row_counter = 0
paired_rows = 0
with bz2.open("C:/Users/John/Downloads/RC_{}.bz2".format( FILENAME_OF_DATA)) as f:
for row in f:
row_counter += 1
row = json.loads(row)
parent_id = row['parent_id']
body = format_data(row['body'])
created_utc = row['created_utc']
score = row['score']
comment_id = row['name']
subreddit = row['subreddit']
parent_data = find_parent(parent_id)
if(acceptable(body)):
if score >= 2:
existing_comment_score = find_existing_score(parent_id) #Gets the score of the current most popular reply stored in the database to the question with the parent ID defined by pid
if existing_comment_score:
if score>existing_comment_score: #If the current comment is more popular than the one we have stored, we will update it
sql_insert_replace_comment(comment_id, parent_id, parent_data, body, subreddit, created_utc, score)
else:
if parent_data:
sql_insert_has_parent(comment_id, parent_id, parent_data, body, subreddit, created_utc, score)
else:
sql_insert_no_parent(comment_id, parent_id, body, subreddit, created_utc, score)
Creating a Train/Test Split
The logic for creating the train/test split was implemented with Pandas. I read the data from the database 5000 rows at a time and store 100,000 rows of the data for the test.
import sqlite3
import pandas as pd
FILENAME_OF_DATA= '2015-01'
#Connect to sql database
connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()
limit = 5000 #Analyzes 5000 rows at a time
last_unix = 0 #Keeps track of the LAST unix timestamp that we read up to
cur_length = limit #Ensures that we still have data to read and analyze by checking size of data
counter = 0
test_done = False
numOfRowsWrittenToTest = 0; #Keeps track of the number of rows written to the test data
while cur_length >= limit:
query = "SELECT * FROM parent_reply WHERE unix > {} AND parent NOT NULL AND score > 0 ORDER BY unix ASC LIMIT {}".format(last_unix,limit)
df = pd.read_sql(query, connection)
if(df.empty):
break
last_unix = df.tail(1)['unix'].iloc[-1] #Grabs last UNIX timestamp
cur_length = df.size/float(7) #Since there are 7 columns for each row
if not test_done: #Writing to Test Data
with open("test.from", "a", encoding="utf8") as f:
for content in df['parent'].values:
f.write(content+'\n')
with open("test.to", "a", encoding="utf8") as f:
for content in df['comment'].values:
f.write(content+'\n')
numOfRowsWrittenToTest += limit
if(numOfRowsWrittenToTest >= numOfRowsWrittenToTest*20): #Stop writing to test data if 100,000 rows have been written
test_done = True
else: #Writing to Train Data
with open("train.from", "a", encoding="utf8") as f:
for content in df['parent'].values:
f.write(content+'\n')
with open("train.to", "a", encoding="utf8") as f:
for content in df['comment'].values:
f.write(content+'\n')
Model
For the model, I applied modifications to an existing model created by Daniel Kukieła, that can be found on his Github. Due to the model originally being his intellectual property, I will not post the code for the model.
Softmax regression was used to determine the question that fit the message that the user provided, and the database was then queried for the corresponding comment.
Extensions and Future Improvements
Obviously, the model was only trained on 5.5 GB of data which is about a month's worth of data from 2015, and would perform vastly better if it was trained on the large and complete ~300 GB data-set provided here

Log in or sign up for Devpost to join the conversation.