-
-
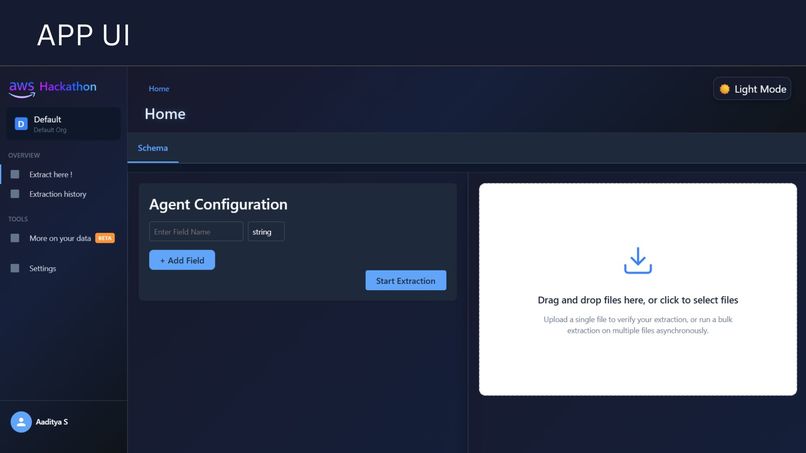
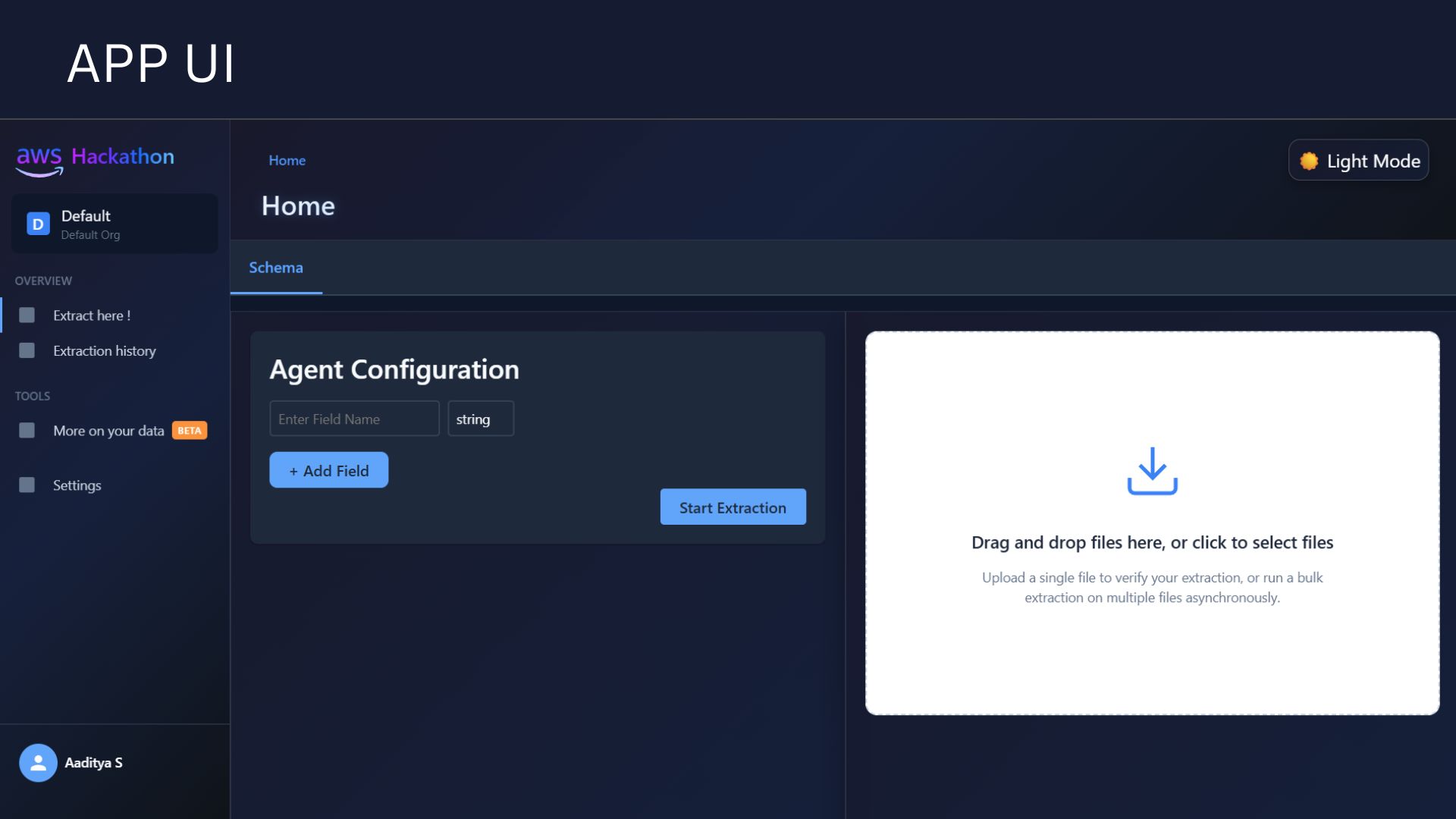
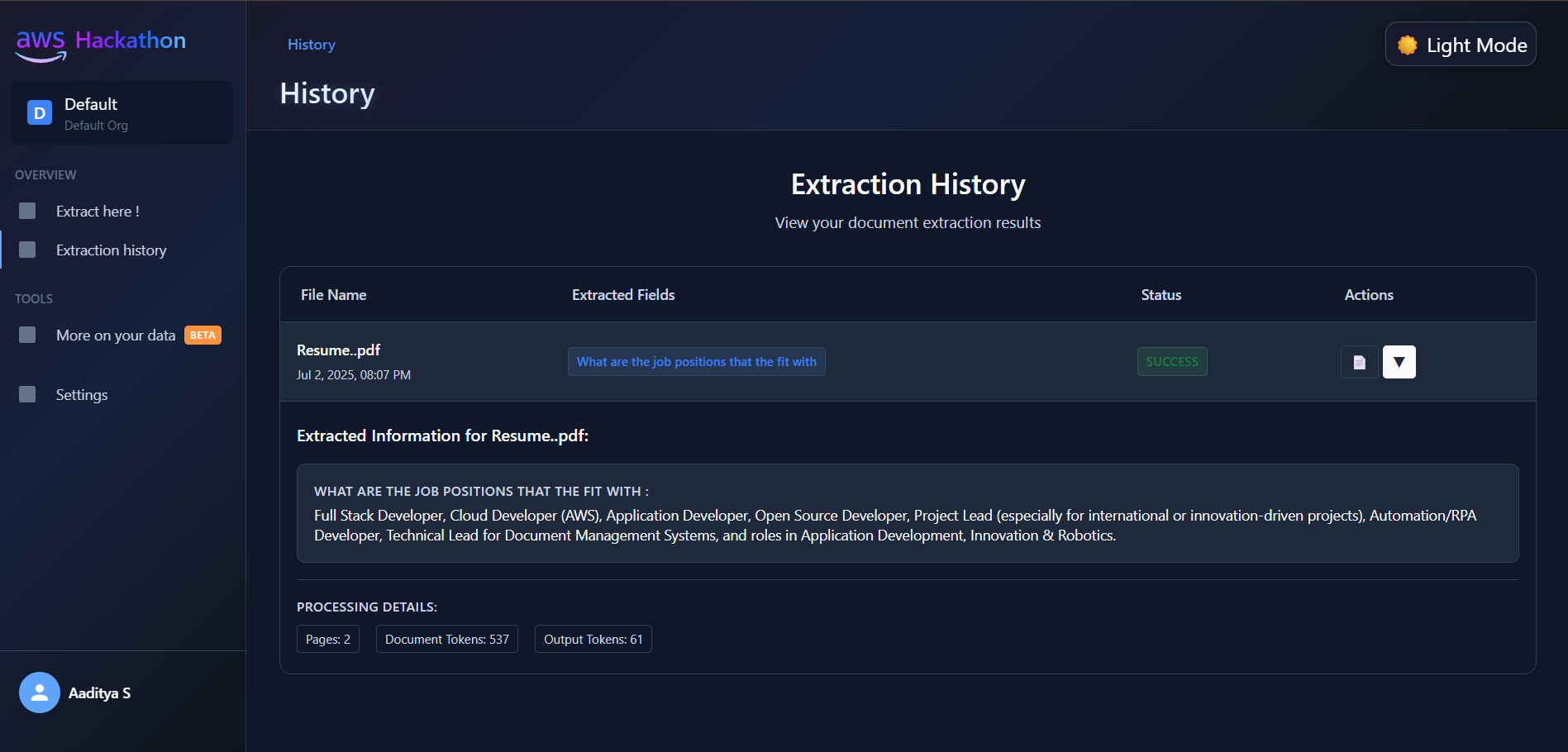
Extarction Page [ICR]
-
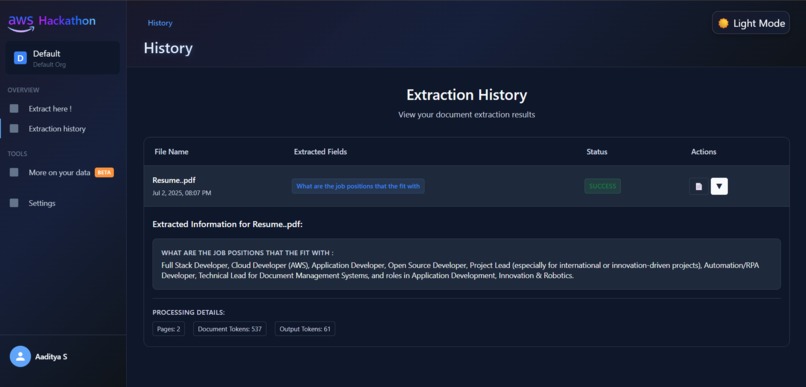
User ExtarctionHistory
-
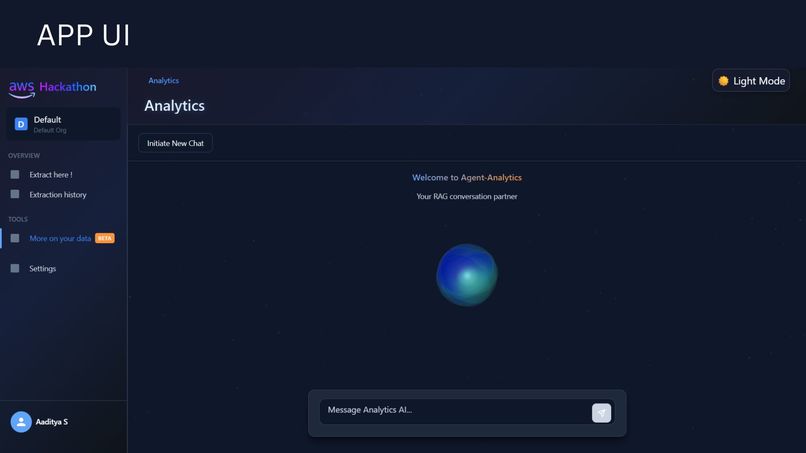
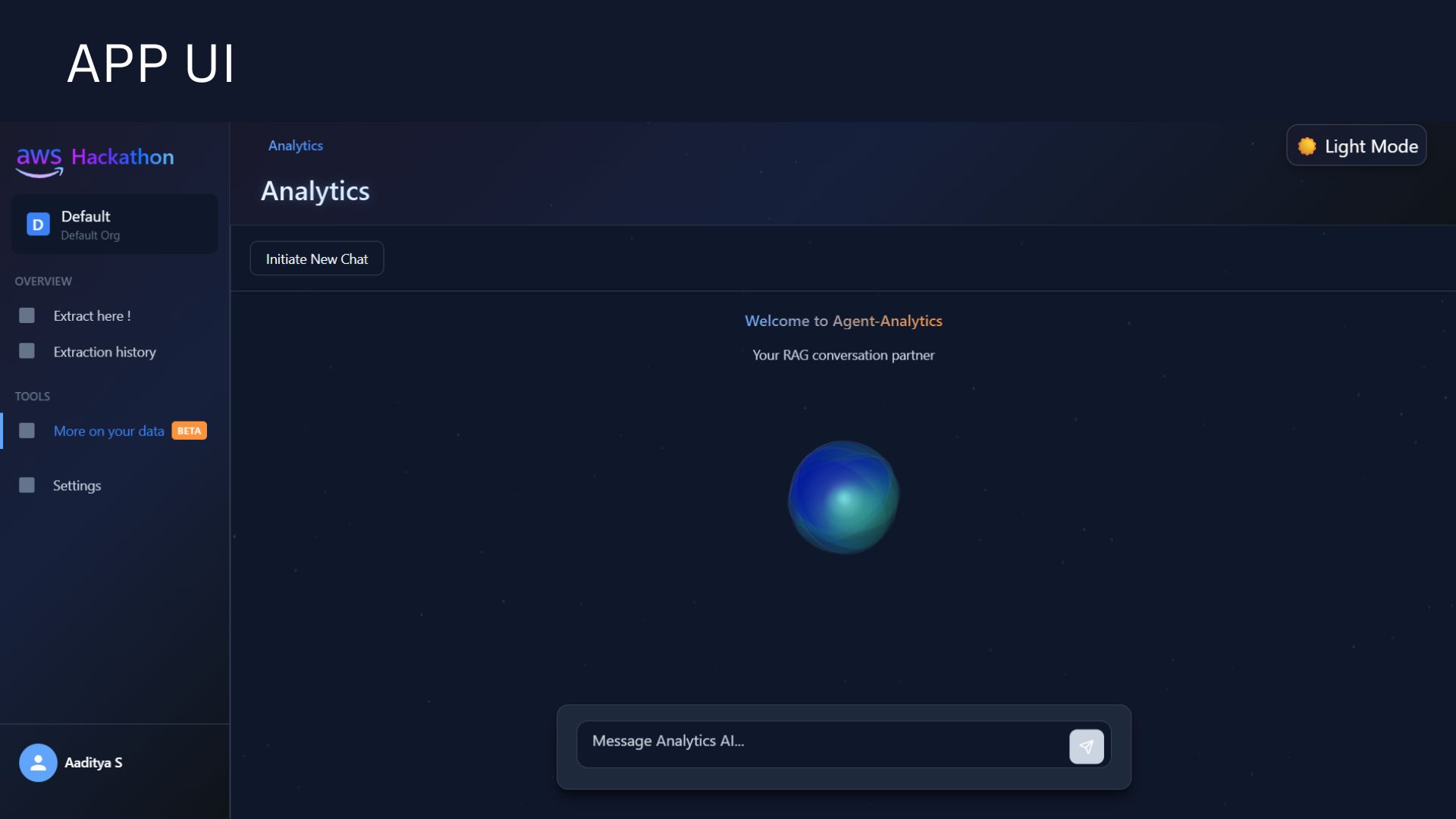
RAG Based Chat Interface
-
APP Settings
-

Purpose of the Solution
-
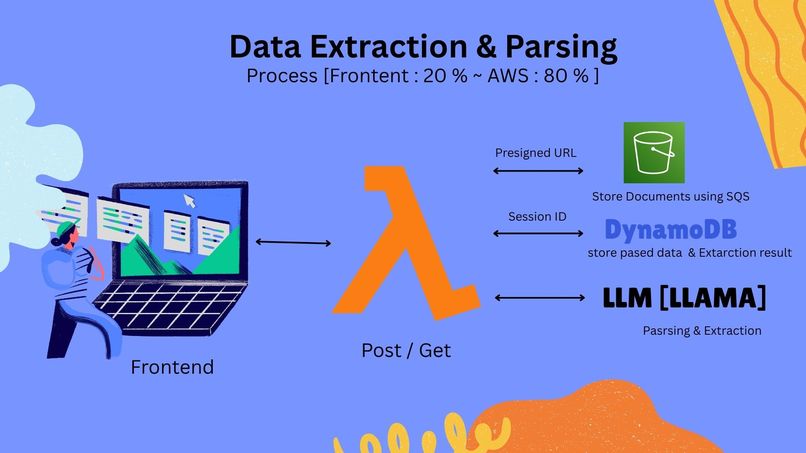
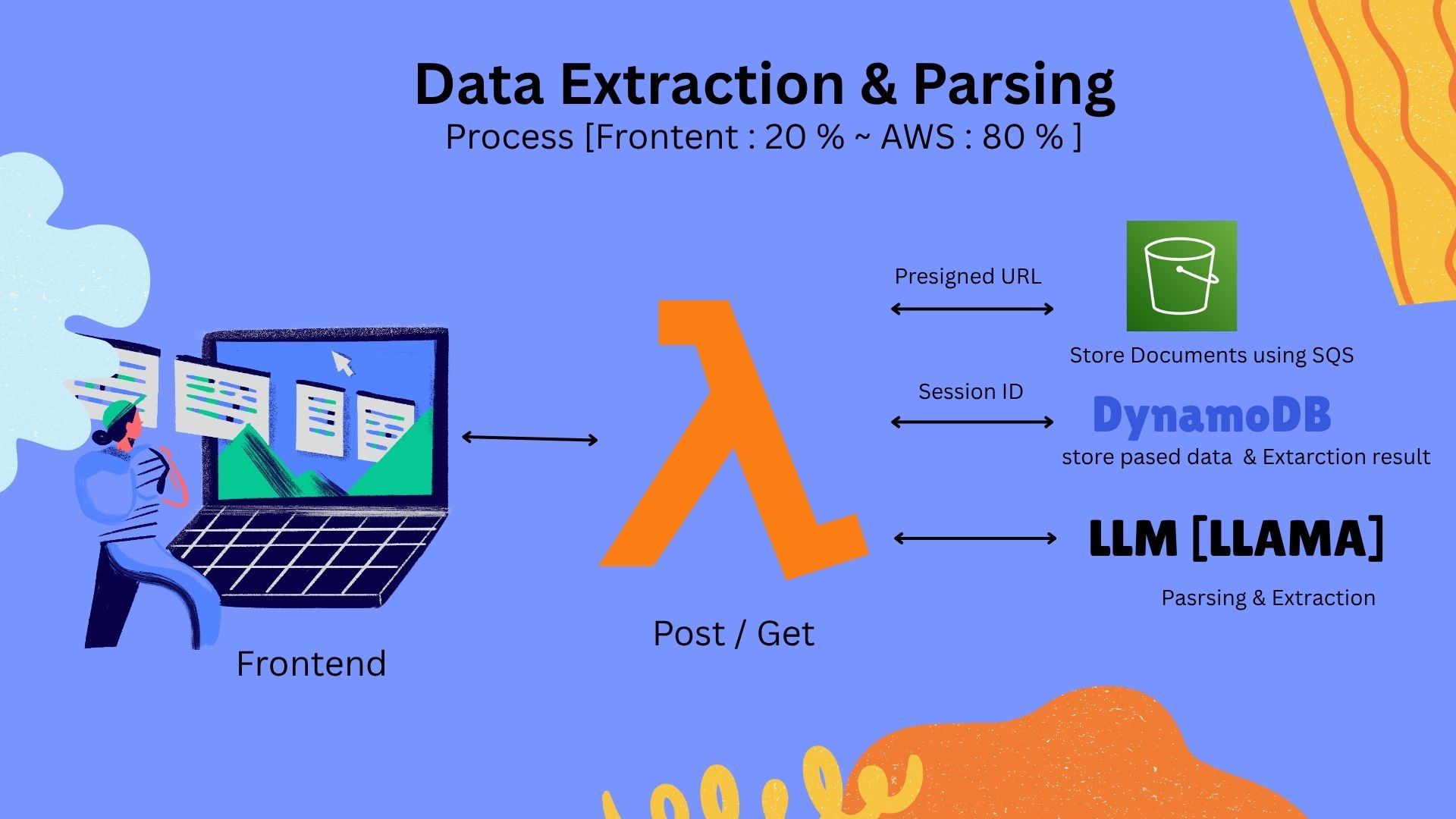
Split 1 : Workflow [Frontend to Lambda]
-
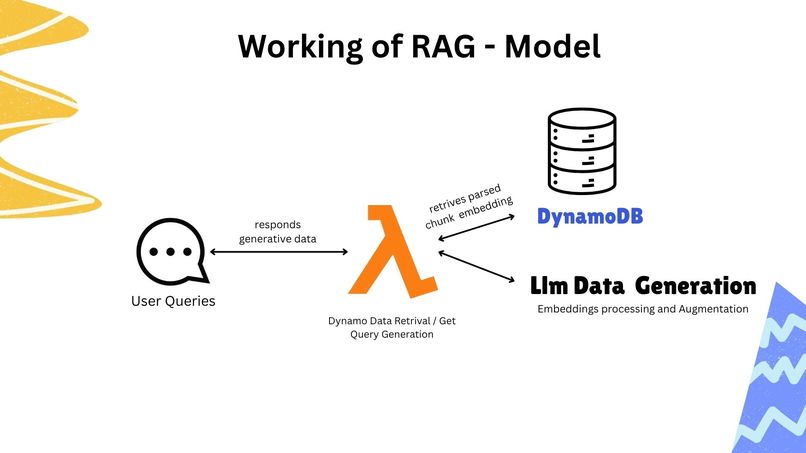
Split 2 : Workflow [Lambda to other services ]
-
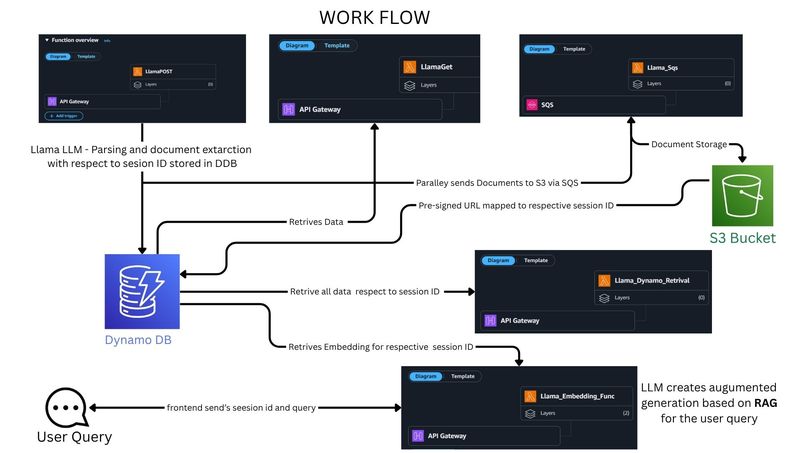
Full Workflow : Truely serverless

AWS Hackathon: Smart Document Intelligence [# Freedom for Data]
What Inspired Me
Document digitization crisis in corporate environments. Companies process 100+ daily documents (invoices, POs, GARs, LRs, e-way bills, agreements, expenses) requiring unique binding numbers that vary per company , also continue to grapple with inefficient workflows, rising operational costs, and poor decision-making because data trapped in documents isn’t accessible or usable.Traditional OCR systems fail because:
- Static technology - no learning capability from processed data
- Complex layout handling failure - struggles with diverse document structures
- Multi-sector terminology confusion - same concepts labeled differently across industries
- Manual verification bottleneck - unreliable extraction requires human intervention
What I Learned
From the above Problem : The digitization crisis isn’t about simply moving paper to digital. It’s about transforming how businesses capture, process and to resource in any form from the data locked in documents. As AI continue to evolve, they offer a promising solution to overcome the limitations of traditional OCR systems.
Full-stack AI architecture implementation:
- ICR with RAG model integration - architecting intelligent character recognition with retrieval-augmented generation
- Local LLM optimization - LLAMA model fine-tuning for document parsing and embedding generation
- AWS serverless ecosystem mastery - DynamoDB session management, S3-SQS integration via Lambda functions
- Frontend development - React with Three.js for interactive document interface
- Containerization expertise - Docker deployment, EC2 integration, Lambda layers management
Technical Architecture & Workflow
Core Components:
- Frontend (20%) - React interface with Three.js
- AWS Backend (80%) - Lambda, S3, DynamoDB, SQS, API Gateway
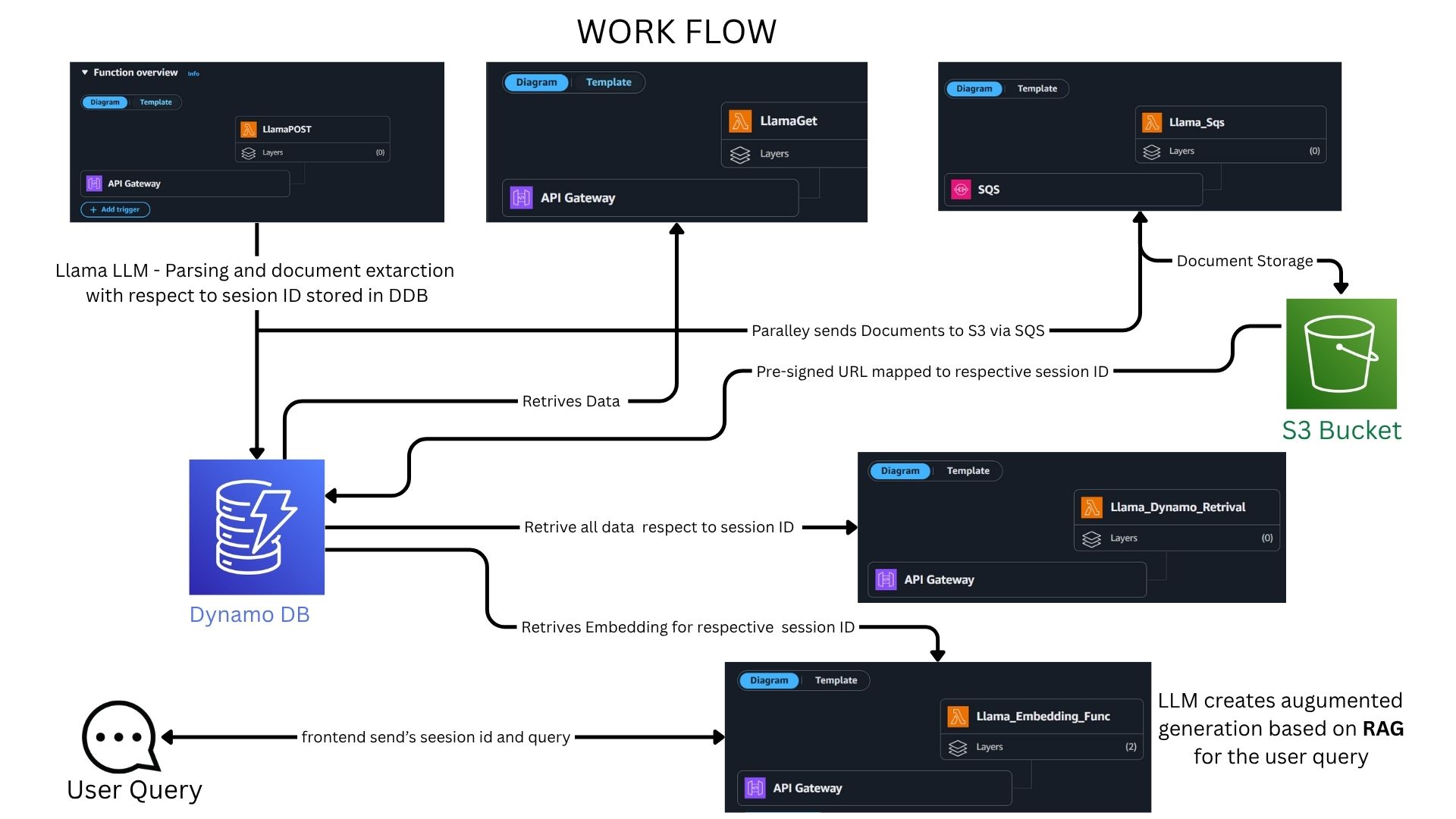
AWS Architecture Workflow (80% Backend - 100% under Free tire limitation):
Document Processing Pipeline:
- Frontend (20%) → Post/Get requests to AWS Lambda via API Gateway
- Session Management → DynamoDB stores session ID with document metadata
- Document Storage → Presigned URLs enable direct S3 upload via SQS queuing
- LLAMA LLM Processing → Parsing and document extraction mapped to session ID
- Data Persistence → Parsed data and extraction results stored in DynamoDB along parsed embeddings
Complete AWS Service Integration:
- API Gateway → Routes frontend requests to Lambda functions
- Lambda Functions → Handle LlamaGet, Llama_Sqs, Llama_Dynamic_Retrival, Llama_Embedding_Func
- DynamoDB → Session-based data storage and retrieval
- S3 Bucket → Document storage with presigned URL access
- SQS → Parallel document processing queue management
- AWS Billing → Zero Budget Limitation
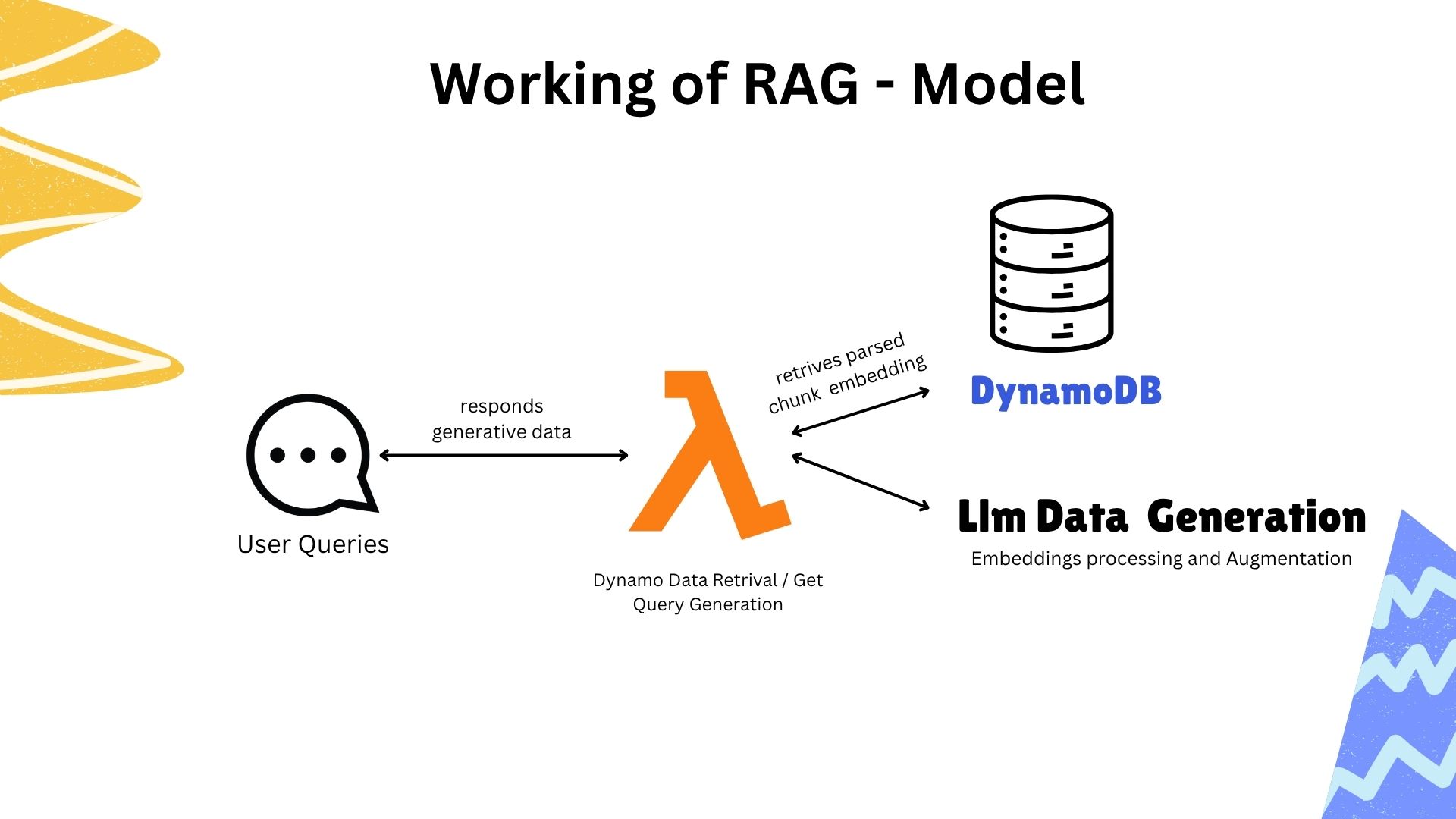
RAG Model Implementation:
User Query (Frontend) → API Gateway → Lambda (Llama_Dynamic_Retrival) →
DynamoDB (Retrieve Session Data) → Lambda (Llama_Embedding_Func) →
Embedding Processing → LLM Augmented Generation → Response with Parsed Chunks
RAG Processing Details:
- User Queries → Frontend sends session ID and query
- Dynamo Data Retrieval → Gets parsed chunks and embeddings for session
- LLM Data Generation → Embeddings processing and augmentation
- Response Generation → Contextual answers based on document content
Key Challenges Faced
Primary Technical Challenge: Running LLM through Docker containers and deploying to EC2 while maintaining AWS free-tier limits.
Specific Issues:
- Container optimization - Pushing LLAMA model via Docker to EC2
- Lambda layer management - Image container integration for LLM processing
- Resource constraints - Bringing LLM functionality within free-tier architecture
- Performance optimization - Balancing accuracy with processing speed without auto scaling and cold start issues caused by llms
Market Impact & Corporate Applications
Target Market: Corporations across multiple sectors handling extensive paperwork workflows.
Key Value Propositions:
- Precise extraction accuracy vs traditional OCR failure rates
- Intelligent prompting - extract specific data requirements through natural language
- Session-based storage - all extracted data preserved for future reference
- Natural language queries - clarify extracted content through chat interface
- Workflow automation - replace manual verification with AI-powered processing
Use Cases:
- Financial documents - Invoice processing, PO matching, expense management
- Legal documentation - Agreement processing, contract analysis
- Supply chain - GAR documents, LR processing, e-way bill management
- Cross-sector adaptation - handles varying terminologies and formats
Competitive Advantage
ICR vs OCR Enhancement:
- Adaptive learning - improves with processed data
- Context understanding - handles complex layouts and multi-sector terminology
- Prompt-based extraction - users specify exactly what data to extract
- RAG-powered queries - natural language interaction with extracted data
- Serverless scalability - AWS architecture handles variable document volumes


Log in or sign up for Devpost to join the conversation.