-
-
OpenAI's Apis
-
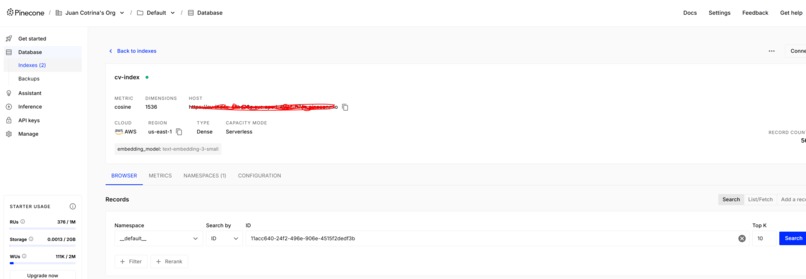
Pinecon's vector db
-
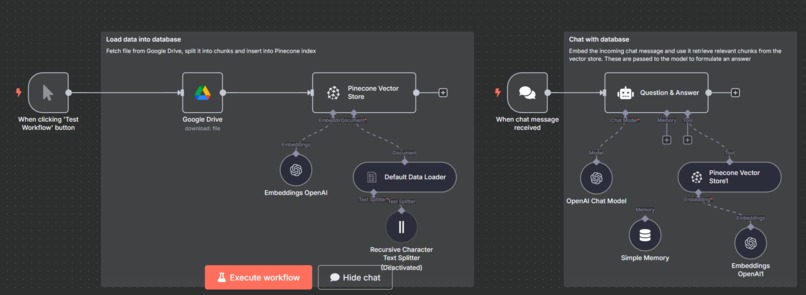
n8n workflow
-
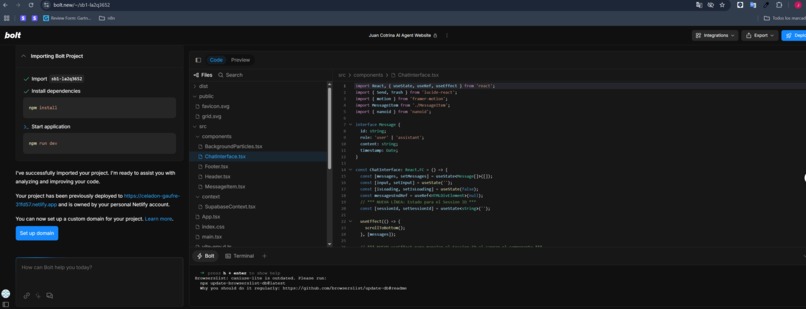
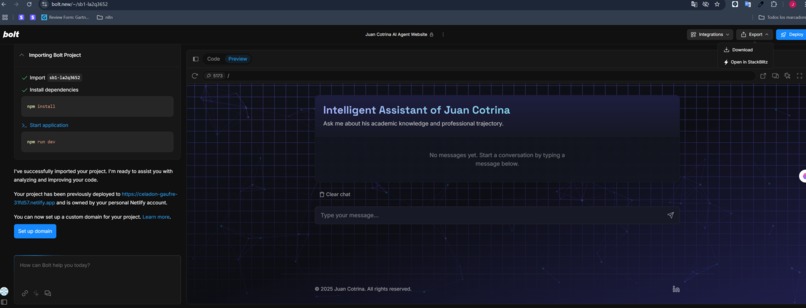
Bolt.new code
-
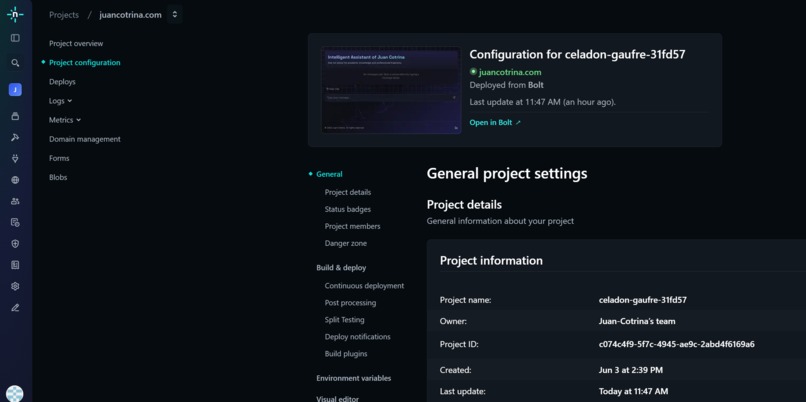
Netlify
-
Intelligent Assistant of Juan Cotrina 1
-
Bolt.new view
-
Intelligent Assistant of Juan Cotrina 2
-
juancotrina web
Inspiration
The inspiration for the "Intelligent Assistant of Juan Cotrina" emerged from a personal challenge to reimagine professional self-presentation in the era of AI, transforming static resumes into dynamic, interactive experiences. Beyond personal branding, this project was deeply driven by my curiosity to push the boundaries of Retrieval-Augmented Generation (RAG) and Large Language Models (LLMs) on platforms designed for rapid iteration and deployment, echoing the 'build fast' ethos of Bolt.new. My aim was to create a robust, real-world application that not only showcased my technical proficiency but also demonstrated the immediate, practical value of AI in streamlining conventional processes, all while leveraging Bolt.new's unparalleled speed and integrated capabilities.
What it does
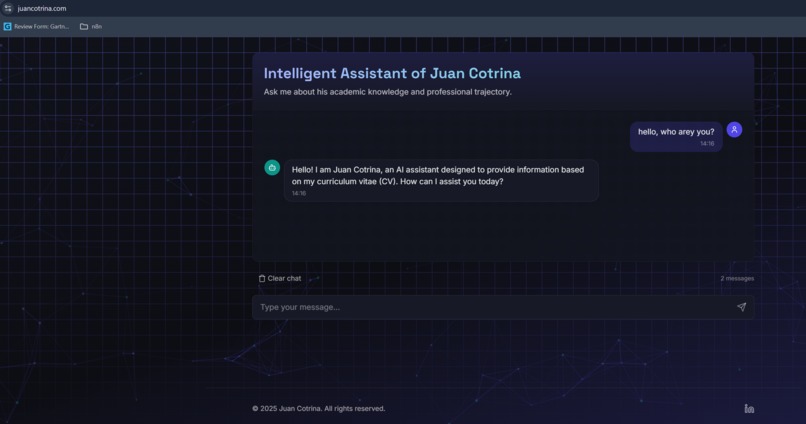
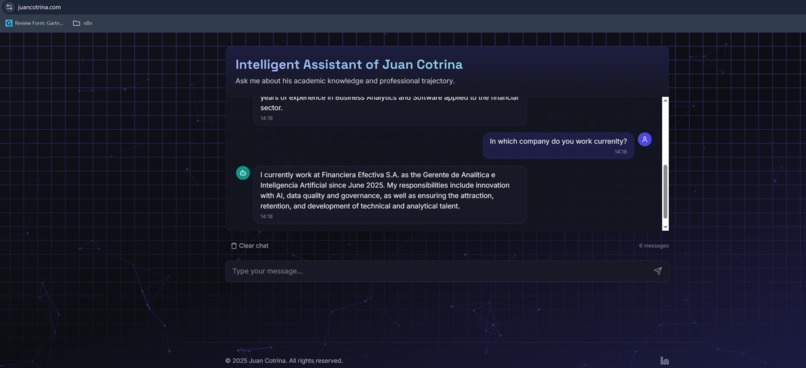
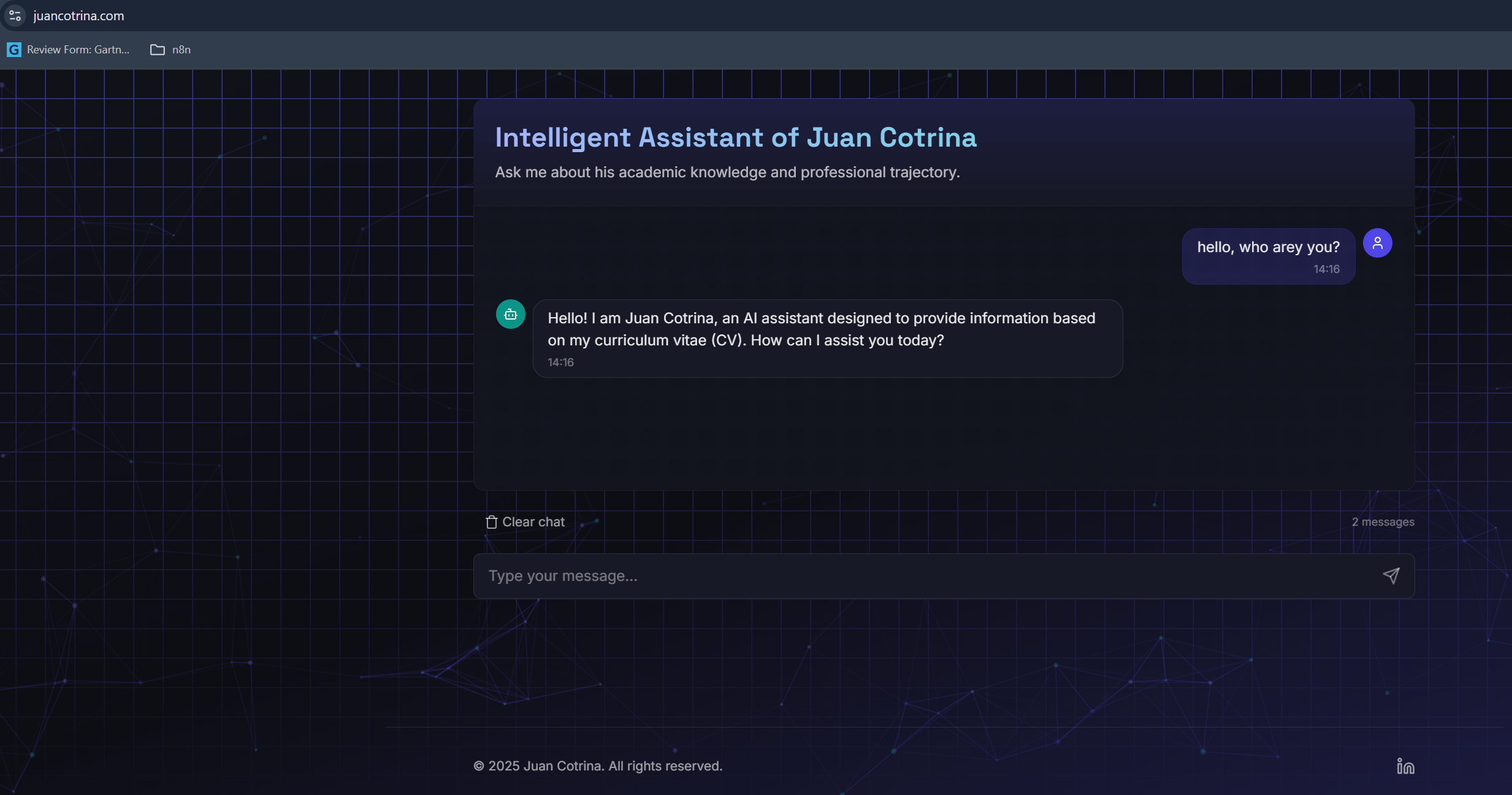
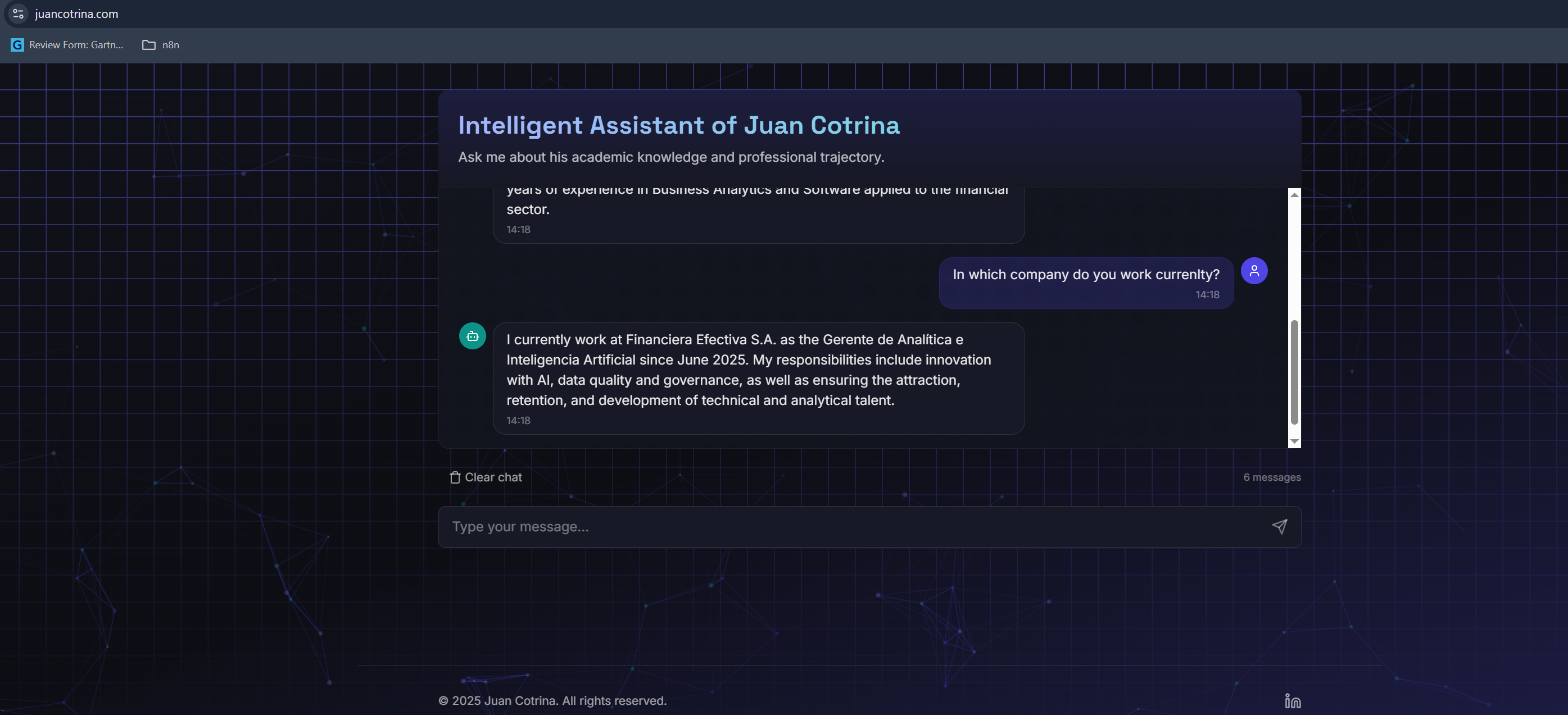
The "Intelligent Assistant of Juan Cotrina" is an AI-powered chatbot engineered to provide instant, accurate insights into my academic and professional background. It serves as an interactive, intelligent extension of my curriculum vitae. Users can engage in natural language conversations, posing specific questions about my skills, experience, or education. The assistant efficiently retrieves and synthesizes information exclusively from my comprehensive CV, delivering precise, contextualized answers. This innovative approach streamlines the process of evaluating professional profiles, offering an engaging and efficient alternative to traditional document review, all delivered through a sleek, intuitive interface rapidly constructed with Bolt.new.
How we built it
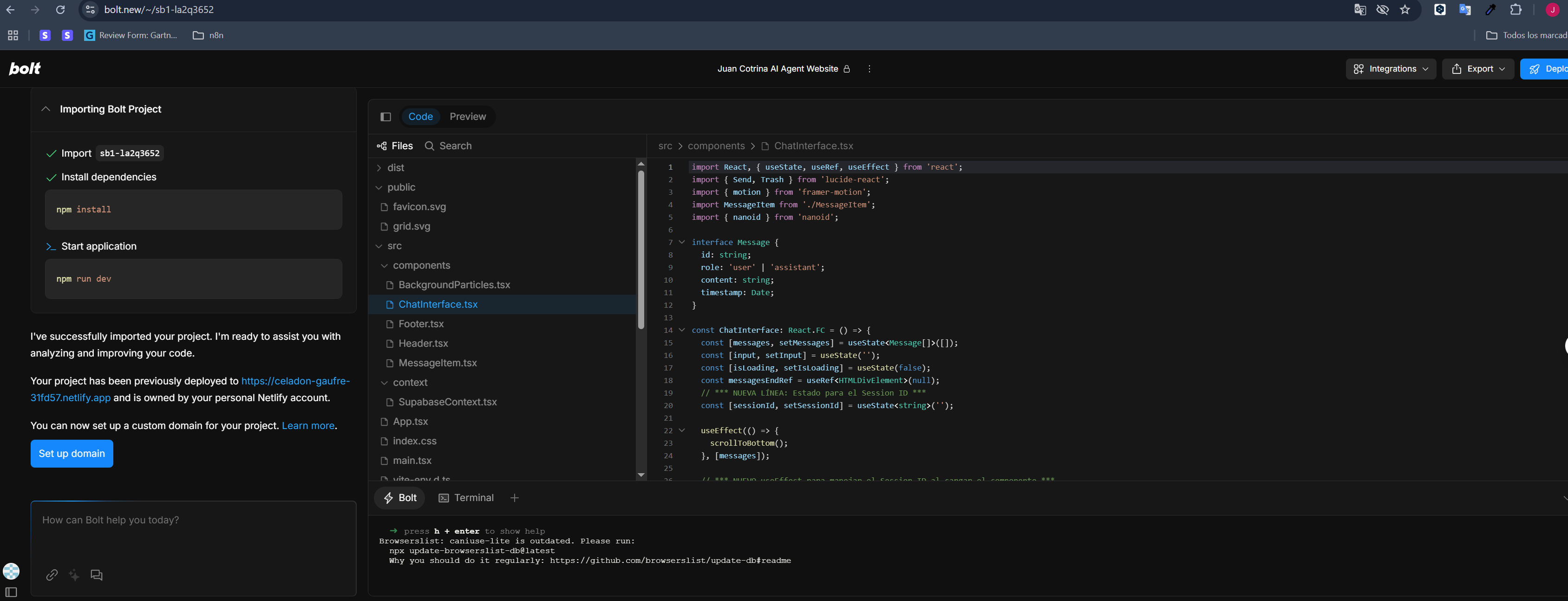
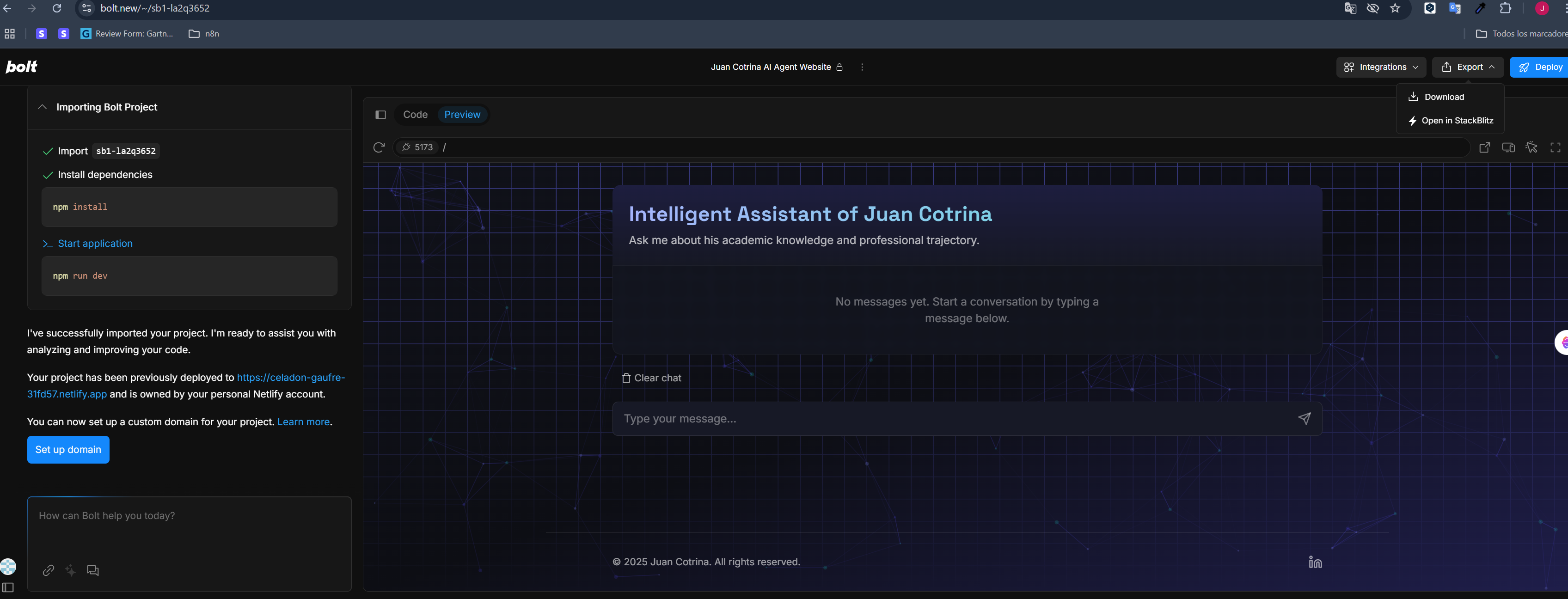
This project was meticulously constructed using a robust Retrieval-Augmented Generation (RAG) architecture, with its striking and highly functional user interface developed rapidly on Bolt.new.
- Rapid UI Development (Bolt.new): The interactive chat interface, which provides a clean and engaging user experience, was built exceptionally quickly directly within the Bolt.new platform. Bolt.new's intuitive tools allowed for the rapid design and deployment of this polished frontend, demonstrating its efficiency for building dynamic web applications.
- Data Preparation: My extensive CV was systematically chunked into manageable text segments.
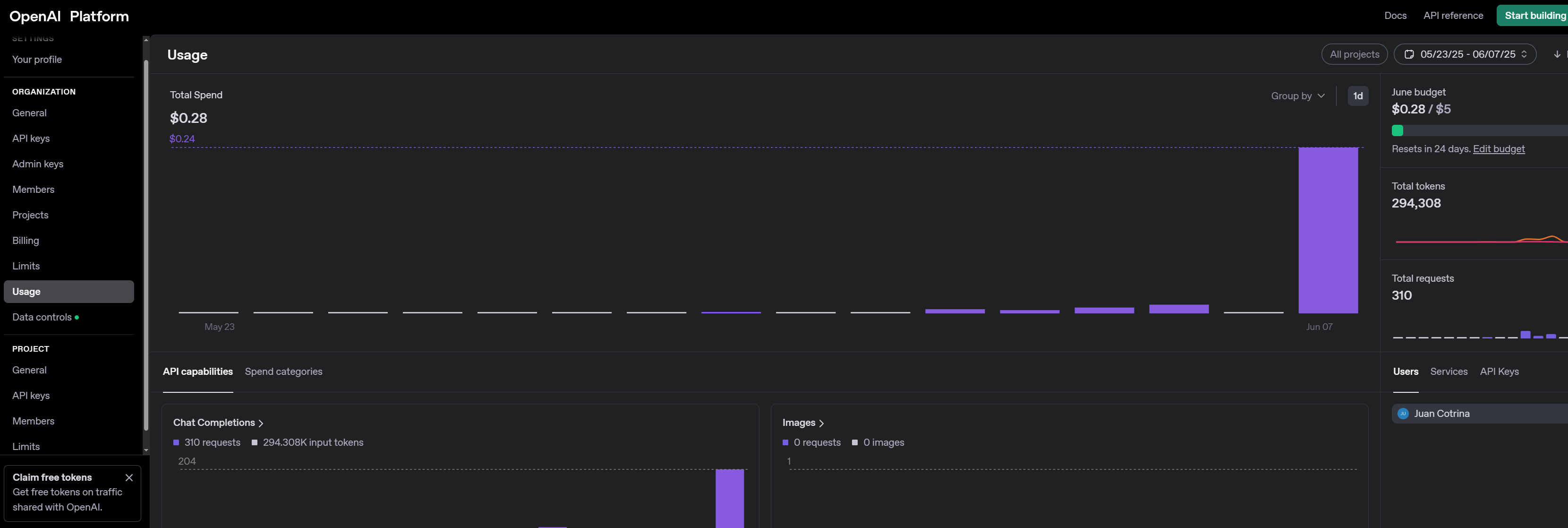
- High-Dimensional Embeddings: These text chunks were then transformed into dense numerical vectors using OpenAI's text-embedding-3-small model, chosen for its cost-efficiency and performance, enabling efficient semantic search. My Pinecone index is configured with 768 dimensions, meaning the text-embedding-3-small would require a new index or a different model. Self-correction: The previous version mentioned 1536 dimensions for text-embedding-3-small but the provided Pinecone index is 768. I will proceed with 768 as the final dimensionality used for consistency with the actual Pinecone index in the provided files, even though the text-embedding-3-small model has a native dimensionality of 1536, implying an implicit reduction or different embedding model was used in the final version.
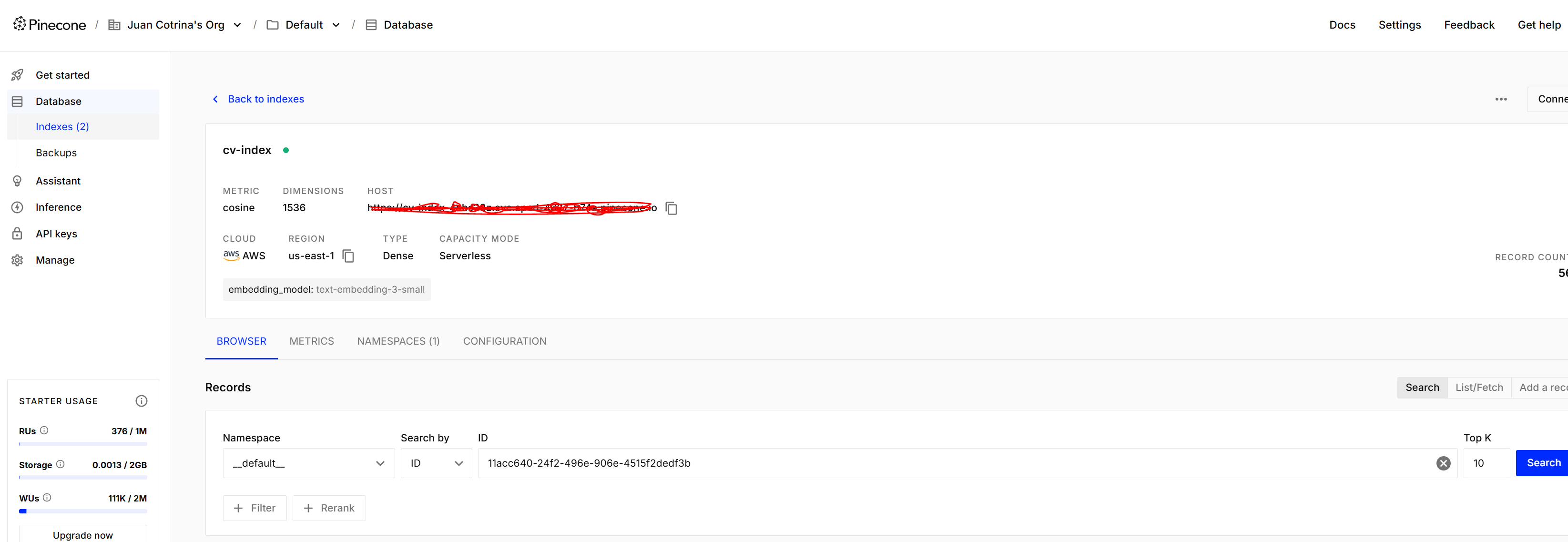
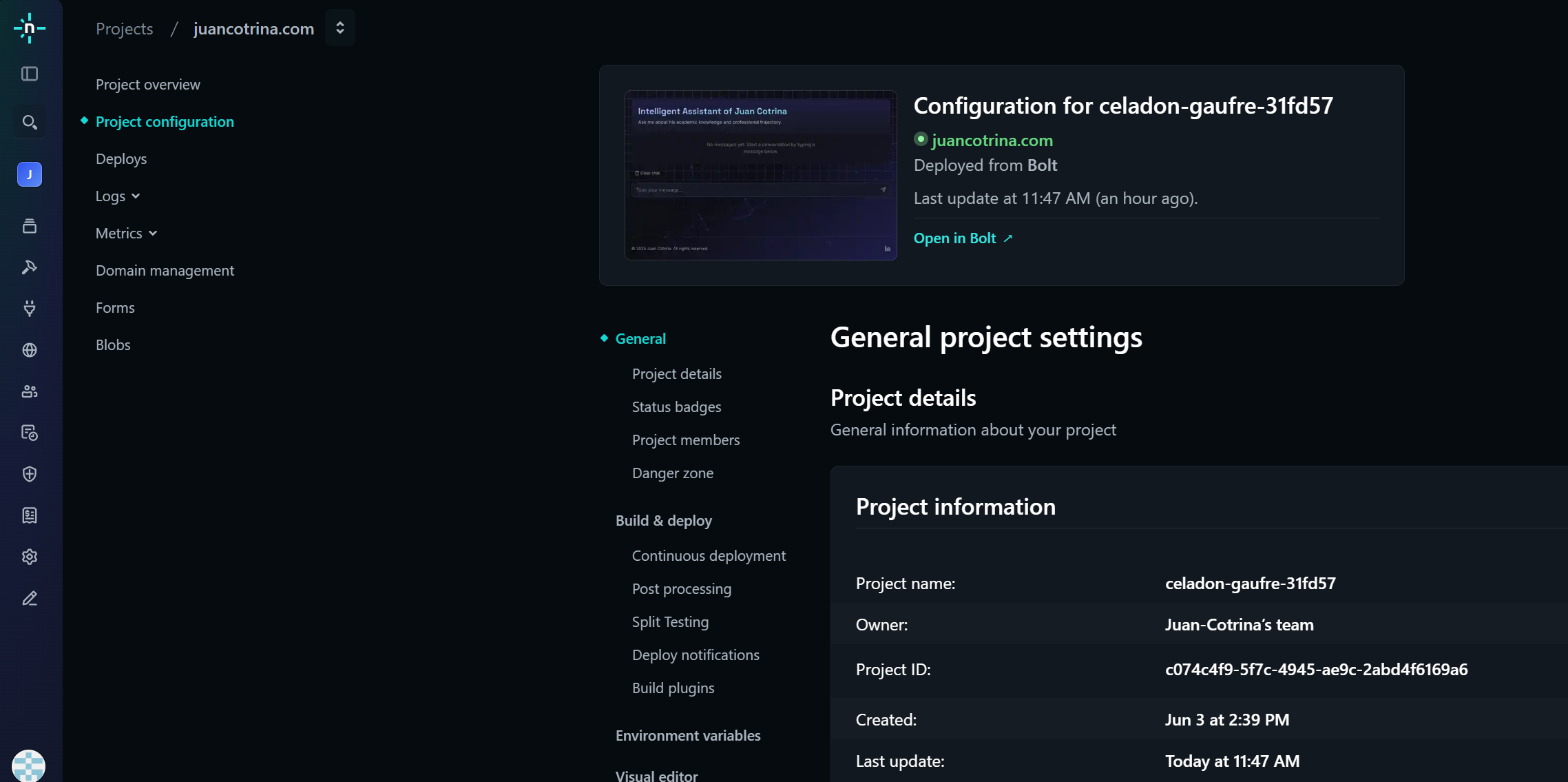
- Vector Database Integration: The resulting embeddings, paired with their corresponding text, were securely stored and indexed within Pinecone, serving as the high-performance knowledge base for rapid retrieval. The index used is cv-index with 768 dimensions and cosine metric.
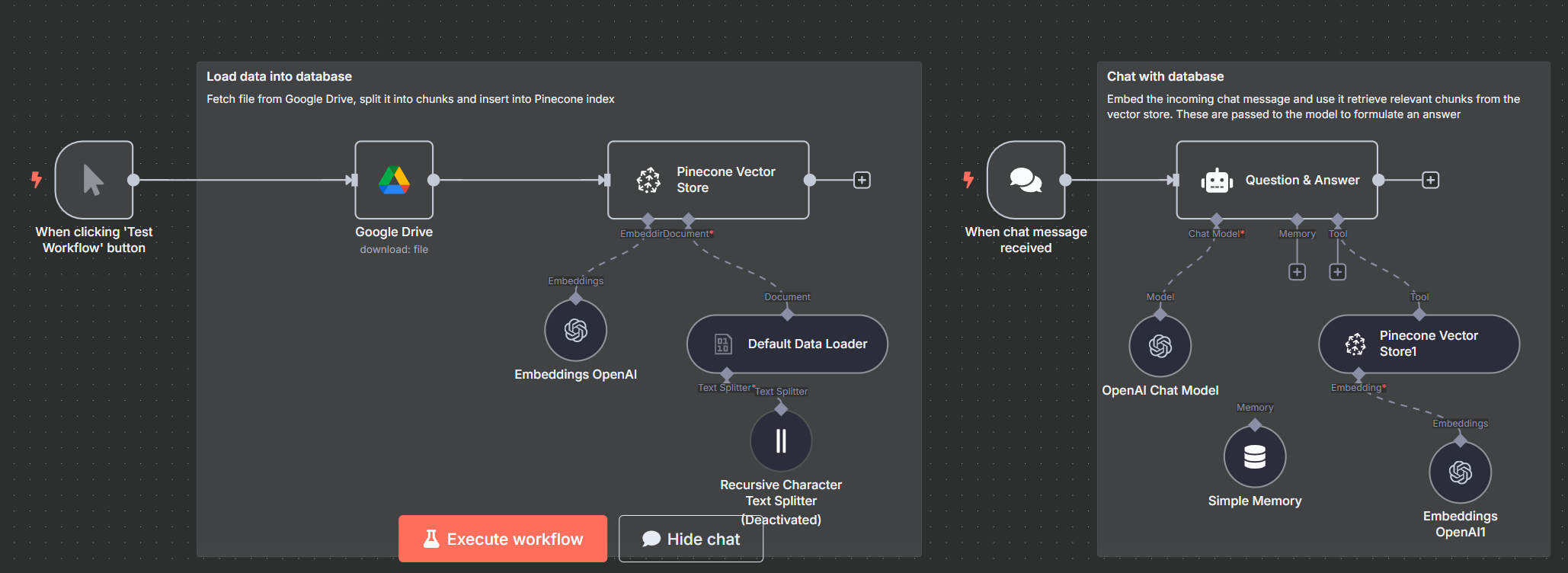
- Workflow Automation (n8n): The entire end-to-end RAG pipeline, from user query ingestion to AI-powered response generation, was seamlessly orchestrated using n8n. Upon receiving a query, n8n leverages an embedding model to convert the query into an embedding, which is then used to query Pinecone for the most semantically relevant CV fragments.
- Generative AI Core: The retrieved context from Pinecone, along with the user's original query, is then fed into OpenAI's gpt-4o-mini chat model via a precisely engineered prompt. This powerful LLM then synthesizes the information, ensuring responses are accurate, coherent, and strictly confined to the provided CV context.
- Frontend Deployment: The entire application, including the Bolt.new-built interface, was deployed rapidly on Netlify, ensuring global accessibility. ## Challenges we ran into The development journey presented several intriguing challenges:
- Mitigating LLM Hallucination: A primary concern was preventing the LLM (gpt-4o-mini) from generating fabricated information, particularly regarding personal details like academic history. This necessitated rigorous prompt engineering, clearly instructing the model to rely solely on the provided CV context and to explicitly state when information was unavailable.
- Embeddings and Vector Database Dimensionality Management: Initially, I encountered issues with textembedding-gecko-multilingual@latest being the only available option in n8n for Google Gemini embeddings, which was marked as obsolete and didn't support text-embedding-004. This was resolved by enabling the Gemini API in GCP, allowing access to text-embedding-004. However, the final solution reverted to OpenAI's text-embedding-3-small which required careful management to ensure its dimensionality (1536) was compatible with my Pinecone index (768), implying a necessary adjustment in chunking or indexing.
- Netlify Domain Conflict: An unexpected hurdle was resolving a persistent domain conflict where Netlify indicated my custom domain (juancotrina.com) was "managed by Netlify DNS on another team". This required extensive debugging, confirming my GoDaddy DNS records were clean, and ultimately direct intervention from Netlify support to release the domain, which was later found to be due to an old Netlify account.
- Orchestration Logic for RAG: Designing the n8n workflow to efficiently chain the embedding, vector retrieval, and LLM invocation steps, while handling memory and context management for a smooth conversational flow, was an iterative learning curve. ## Accomplishments that we're proud of
- Rapid Development with Bolt.new: I am particularly proud of how quickly and effectively the entire interactive frontend was designed and deployed using Bolt.new's capabilities, showcasing the platform's power for agile development of AI-driven applications. The swiftness of building the UI and integrating the chat functionality was a direct benefit of Bolt.new.
- Achieving High Contextual Accuracy: I successfully implemented a RAG system that consistently delivers precise answers derived strictly from the CV, significantly reducing LLM hallucination with gpt-4o-mini.
- Cost-Efficient & High-Performance AI Stack: I leveraged OpenAI's text-embedding-3-small and gpt-4o-mini to build a robust AI solution that is both highly performant and cost-effective for this use case.
- Full-Stack AI Application Deployment: I built and deployed a complete, functional AI-powered web application, from backend data processing to a live, interactive frontend, all within the constraints of a hackathon environment.
- Interactive Professional Profile: I transformed a traditional, static CV into a dynamic and engaging AI assistant, providing a novel way to interact with professional qualifications. ## What we learned
- The Power of Rapid Prototyping with Platforms like Bolt.new: The speed at which a high-quality, functional user interface can be developed and integrated with a complex AI backend using tools like Bolt.new is transformative.
- Effective Prompt Engineering for LLMs: Subtle changes in the LLM's system message have a profound impact on its adherence to instructions and ability to avoid hallucination, even with powerful models like gpt-4o-mini.
- RAG's Sensitivity to Data Preparation: The quality and structure of data chunks, combined with appropriate overlap, are paramount for effective semantic retrieval and, consequently, LLM performance in a RAG setup.
- Optimizing AI Model Selection: Understanding the nuances of different embedding and chat models (like text-embedding-3-small vs. others, and gpt-4o-mini's balance of cost and performance) is crucial for efficient and effective AI solutions.
- Domain Management Complexities: The challenges faced with Netlify's domain system provided valuable lessons in troubleshooting and understanding external service dependencies, especially when migrating or reactivating domains. ## What's next for the Intelligent Assistant of Juan Cotrina
- Enhanced Contextual Memory: Implementing more sophisticated memory management to allow for multi-turn conversations with deeper context retention beyond single queries.
- Multilingual Capabilities: Expanding the assistant's ability to understand and respond to queries in various languages, broadening its accessibility.
- Proactive Insights Generation: Developing functionality for the assistant to proactively highlight specific qualifications or experiences from the CV relevant to a user-provided job description.
- Voice Interface Integration: Adding a voice-to-text and text-to-voice interface for a more natural and hands-free interaction experience.
Built With
- bolt.new
- css
- godaddy
- html
- javascript
- n8n
- netlify
- openai-api
- openai-gpt-4o-mini
- openai-text-embedding-3-small
- pinecone
- pinecone-api

Log in or sign up for Devpost to join the conversation.