-
-
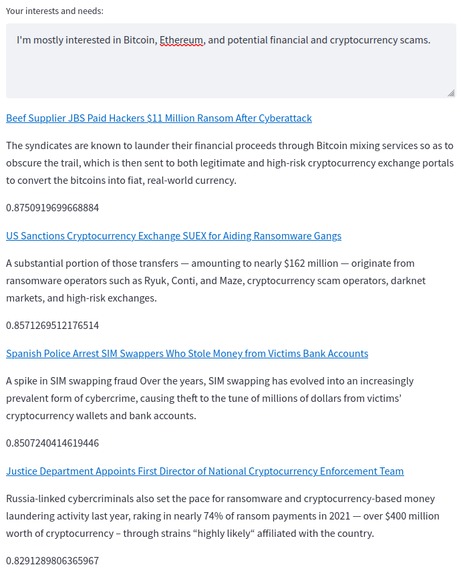
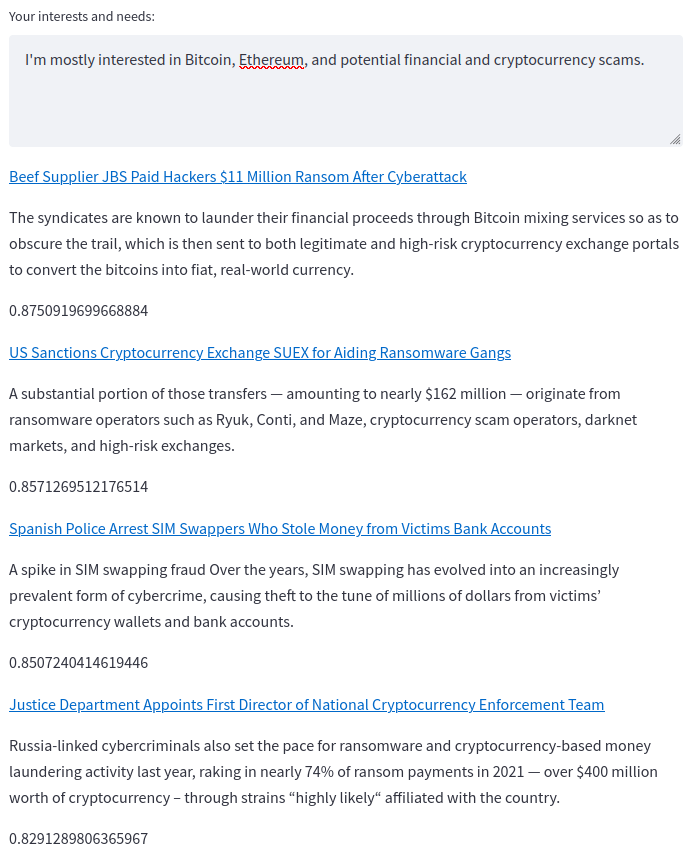
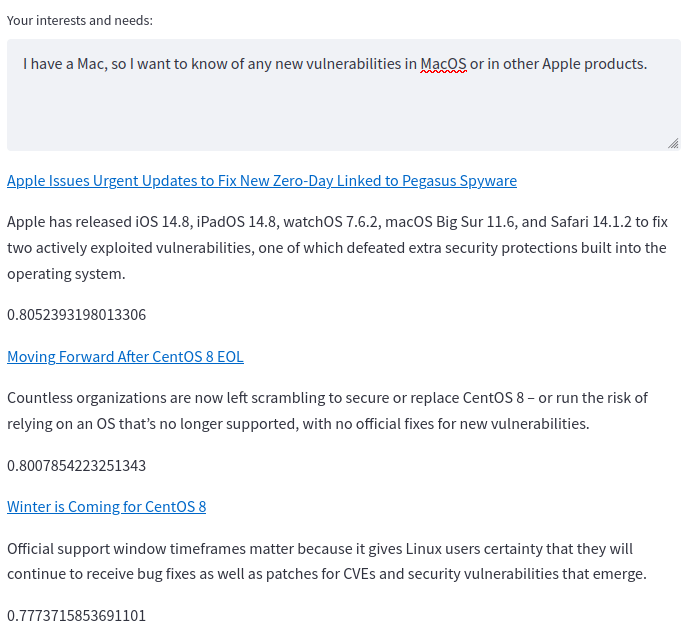
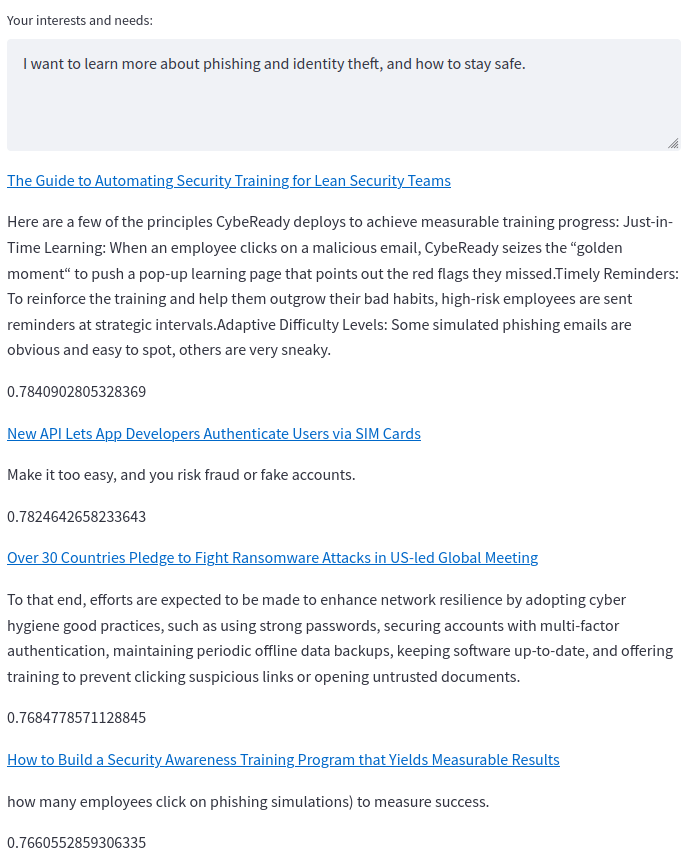
The real strength of this approach can be seen here; a keyword search would find any one of those articles, but we find all four.
-
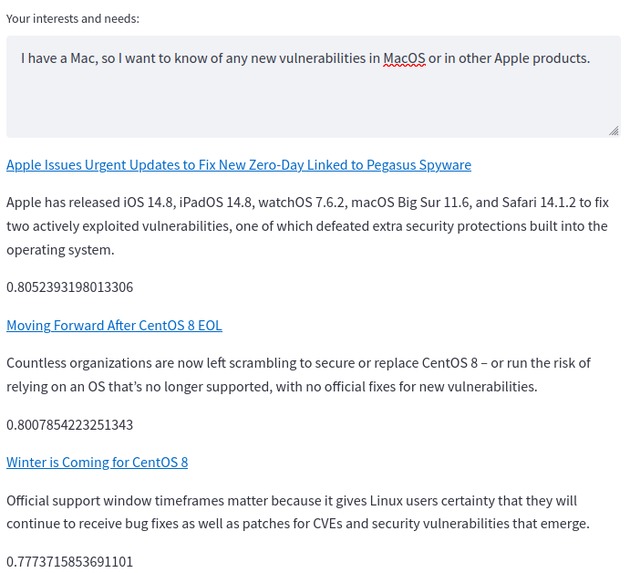
Notably, it's not perfect: operating systems are sometimes confused for one another.
-
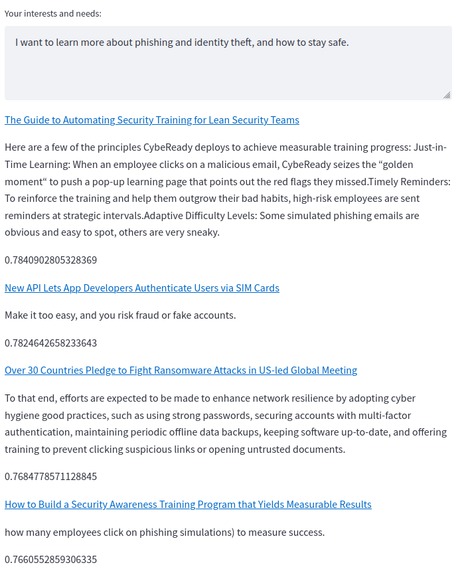
Something we'd love to do: clean up the article excerpts a bit. The selection's good here, but the formatting's a mess.
Inspiration
Christine
As this article puts it:
Cybersecurity teams sometimes see threat intelligence as the quick fix that will protect them from hackers and scammers. This expectation is largely overinflated. The fact is, there is no such thing as one-size-fits-all threat intelligence...A financial services company, for example, probably wants to pay close attention to website forgery and malicious contact forms aimed at deceiving targets into revealing their credit card and bank account numbers.
I work in cybersecurity, and all the feeds out there currently contain a lot of information that is not relevant. Do a Google News search for "cybersecurity" and you'll see what I mean; as of an hour before the deadline (I'm a Drexel alumna, doing everything an hour before the deadline is normal), the top headlines were:
NIKE IS OPENING A 'TECHNOLOGY CENTER' IN ATLANTA NEXT YEAR
HEALTHCARE TO INCREASE TECH SPENDING FOR CYBERSECURITY, MARKETING, AND AI
GOVERNEMNT OFFICIALS: AI THREAT DETECTION STILL NEEDS HUMANS
CORO BANKS $60 MILLION TO BRING AI-BASED CYBERSECURITY TO SMBs
FDA RAMPS UP CYBERSECURITY EFFORTS WITH STRICTER GUIDANCE FOR DEVICEMAKERS
Each of those headlines is potentially relevant to you, depending on who you are and what you're doing. If you're a small business owner in Atlanta, Nike opening a tech center might mean more business or a change in traffic patterns. If you're an investor, you might reevaluate Coro based on its latest purchase. If you're in the medical field, you need to know what new FDA regulations are coming down the pike. None of these articles are bad. But there are very few people for whom all five of those headlines are immediately relevant and useful. I think we can do better.
David
Unlike Christine, I'm not a cybersecurity professional, and everything I know about cybersecurity is what I've picked up through osmosis from having friends in the field and seeing the occasional relevant article. Which is to say, I know just enough to know how huge the field is, and not much more, and given that I don't even own a smartphone, my personal need for up-do-date information is probably less than most people in the tech field. However, I have worked with word vectorization quite a bit, and when Christine pitched the idea of using it to better understand cybersecurity, it was far too good an idea to pass up.
What it Does
Put simply, it attempts to solve the problem of too much information in the news by filtering out irrelevant news. Type in a brief description of what you want, or what you do, and it returns the articles which are semantically closest to your description, not just articles which happen to share the same keywords.
How It Works
Scraping the Web
Any NLP project, anywhere, needs text and lots of it. For this, we scraped 9,800 articles dating back almost 12 years from TheHackerNews.com, using Mathematica's XMLObject[] parsing capabilities to extract only the parts of the article we needed and discard the rest. With this, we gathered roughly 5.3 million words, which was (in Big Data terms) just barely enough to work with.
Vectorizing Words
word2vec is a technique for natural language processing which does not learn what words mean, but does learn what words are used similarly in sentences. By assuming that words used in the same context or in similar contexts likely mean similar things, word2vec trains a neural network to turn each word in its training data into a vector (a 500-dimensional vector, in our case). The angle between the vector indicates how similar the words are to each other; for instance, "Hello" and "Hi" would be very close together and have a very low angle (and very high similarity), while "Hello" and "Apricity" would have a very far apart and have a very high angle (and very low similarity).
Deploying
streamlit is an API and hosting service which allows for python code to be rendered as a GUI and launched natively to the web. It can run projects from a host computer or from GitHub, and since we wanted to have our project on GitHub anyway, streamlit was the natural choice.
Challenges we ran into
As with all projects, the Pareto Principle applies: 80% of the pain and headache was caused by 20% of the code. Getting word2vec working was seamless, as was deploying a fully functional webapp in Python with Streamlit and scraping thousands of articles from the web. What really caused us trouble was getting similarity between one sentence and another - not because the document similarity was so much more difficult to calculate, but because we were using the wrong functions, and effectively searching for articles with the worst matches rather than the best ones. It's the sort of bug that would have been easy to see without time pressure, but time pressure and the added difficulty it brings is what makes contests like these so much fun.
Accomplishments that we're proud of
- Writing not one but three separate web scrapers, with three different APIs and parsers, just in case the one wasn't good enough and didn't pick up enough articles.
- Getting a live python webapp working for the first time; neither of us knew about
streamlitbefore we started the project, but it's an incredibly useful tool, both for local testing and for global deployment. - Not giving up after hours of frustrating and fruitless debugging, figuring out the semantic similarity bug at the last possible moment, and actually having a finished project to upload and present.
What we learned
There's an extension to word2vec called doc2vec, which we naturally tried to use for our semantic similarity function. As it turned out, on the sizes of documents we had and on the size of our corpus, doc2vec was actually worse than just averaging the vectors for each word in a sentence, and computing the distance between pairs of averages. What we learned from this? Don't make things more complicated than they need to be.
-- Christine
At first, we tried taking the similarity between the user's input text and an entire article, but ran into a problem: the matches just weren't very good. The best articles were often long and detailed, and as a result, adding together all of the sentences inside had much the same effect as mixing every single color from every crayon in the box: you get an off-shade of green that's not useful for much. Instead, we had to go with a more complex solution, of calculating the similarity between the input vector and each sentence in an article, and then picking the articles with the most relevant sentences. What we learned from this? Don't make things less complicated than they need to be. -- David
What's next for IntelDragon
Having spent three days now working with streamlit, I can safely say that there's a lot more we can do with it. I would love to show more about how word2vec works, maybe by using PCA to turn the 500-dimensional vector down to 2D or 3D and then plotting where different words are in relation to each other. word2vec has been an interest of mine for years, and I'd love to do the opposite of what Christine wants to do; I'd love to start with a useful Internet dashboard, and then use it to teach not just cybersecurity but NLP as well.
-- David
There's a lot more we'd like to do to make this a useful product for professionals. Right now, we're caching a year's worth of articles from just one website - TheHackerNews.com - and using that for the news articles. This is fine for a demo, but to be really useful we'd need to pull in articles from all over the Internet, and automatically retrain the model on a regular basis (maybe daily) with those new articles, so that new keywords could be picked up and vectorized.
Also, the video demo hadn't finished uploading to YouTube at deadline, but it will hopefully finish uploading by the time you read this, so you can see it in my channel. -- Christine
Built With
- gensim
- mathematica
- python
- streamlit

Log in or sign up for Devpost to join the conversation.