-
Main Page
-
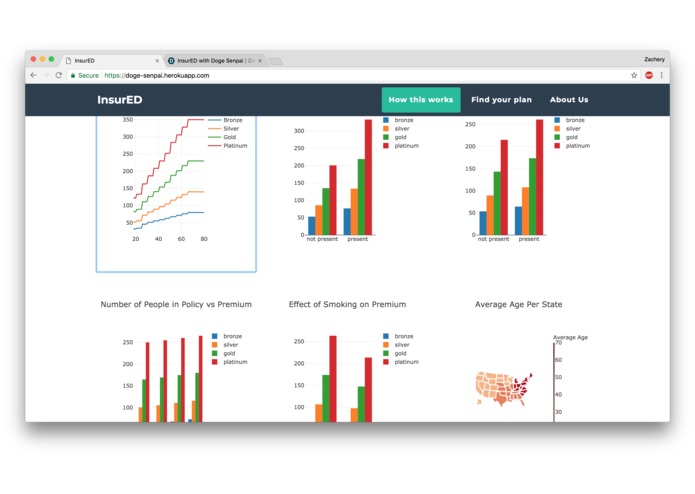
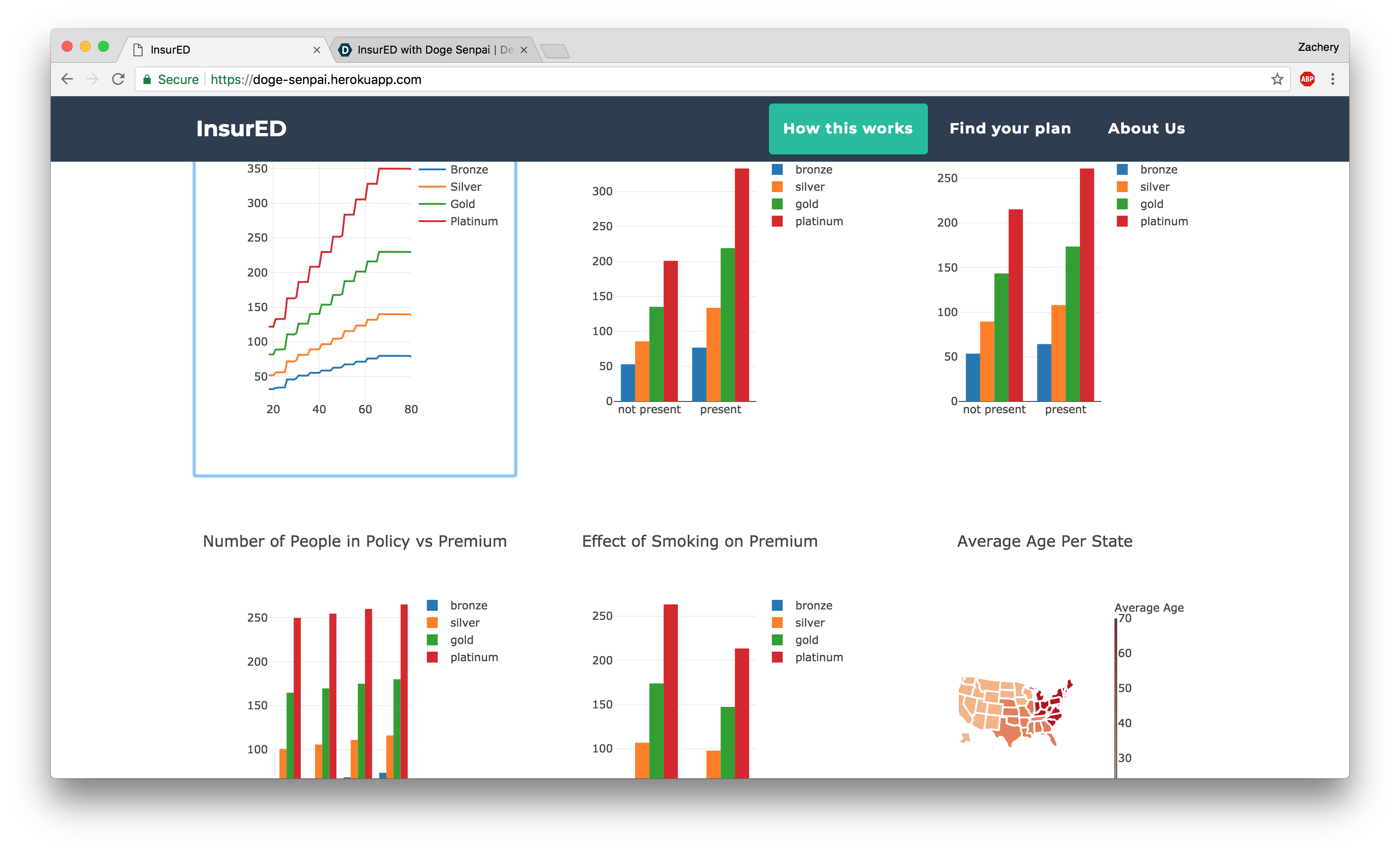
Graphs
-
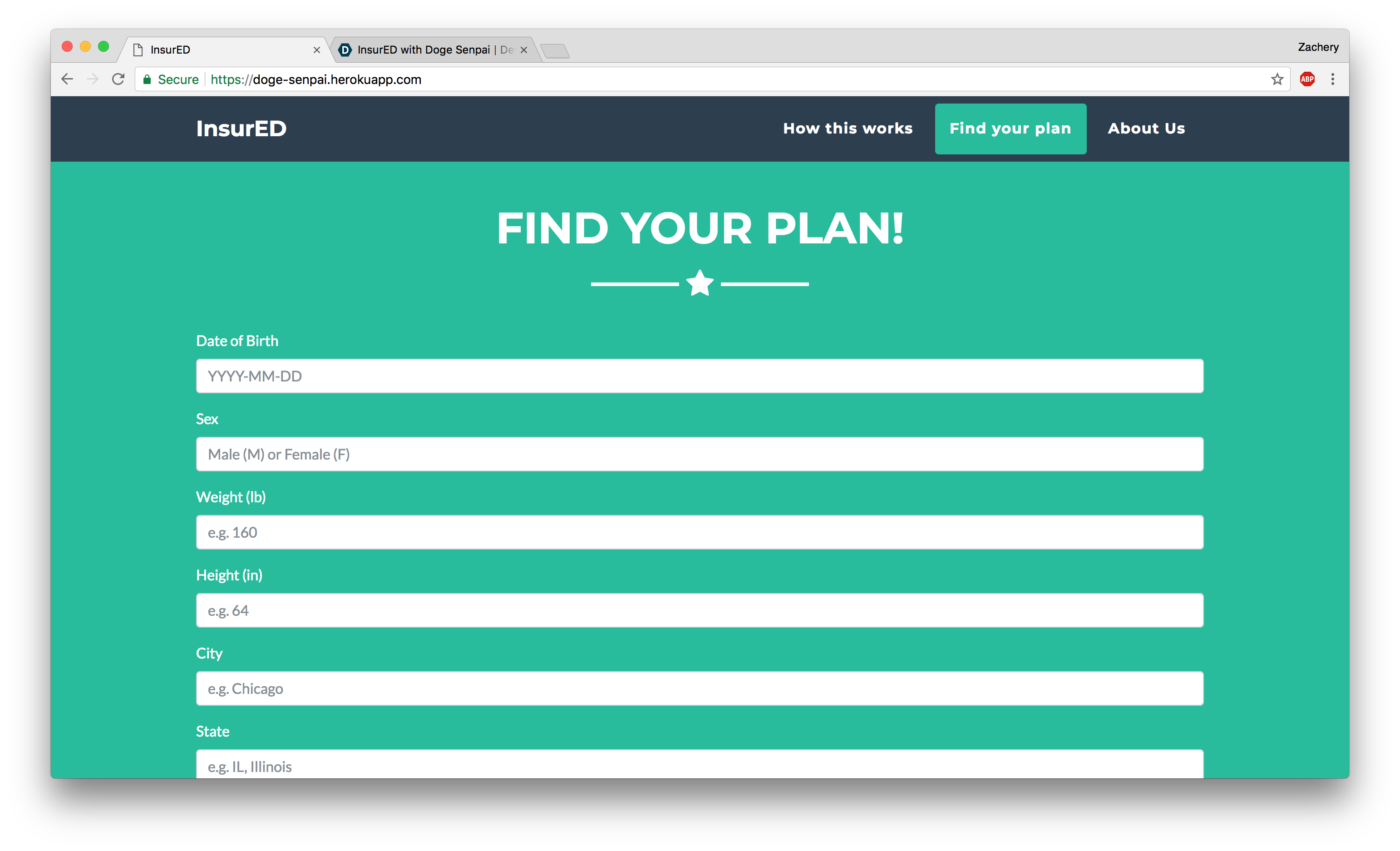
Plan Premium Predictor Form
Inspiration
We didn't understand insurance and realized most people don't.
What it does
InsurED with Doge Senpai aims to educate about health insurance and the factors influencing premium costs. We broke the problem into two core goals:
- Training an accurate machine learning model to gain insights to the data we were provided
- Explaining and visualizing those insights in a clear and approachable manner Check out how these came together at doge-senpai.herokuapp.com
How we built it
We downloaded all of the data, which were 4 data sets (of which 3 were important). Then we manually joined the data to create a 1.7GB data set. We noticed that the preconditions were lists stored as strings so we collected all possible categories and encoded each of the conditions as a binary vector. Next we normalized all of the data to be in the range of -1 and 1 (by taking the min and max for each parameter) so that our machine learning algorithms could perform well on the data. The data was segmented into a training set of 1M examples and a test set of 480k examples.
Now with a normalized data set, we were ready to learn! Our goal was to learn a regression model for each of the premiums. First we experimented with linear classifiers with decent results. We used a linear classifier with LASSO regularization in order to find the most meaningful features. Then we tried an SVM with RBF kernel but we had too much data for it to finish learning. Finally we experimented with deep learning. After messing around with multiple models, we settled on a one layer network with 300 units and ReLu activation using squared error loss. This yielded a regression model with 99.6% accuracy on the test set.
Meanwhile, we were playing with the data in Tableau and making graphs to gain more insight from the data. Many of the insights matched what we learned from the weights in LASSO.
Last of all we made the classifier as a web service and made a Flask web app to display our results.
Challenges we ran into
- FORMS
- data not appearing in D3
- slow wifi
- everything taking a long time because of the massive size of the data set
- not including smoking as a feature at first by accident and having the neural network have 10% less accuracy than we could have had... oops
Accomplishments that we're proud of
- successfully using machine learning :flushed:
- successfully counted 18 preconditions :thinking:
- plotting graphs finally
- getting an ML model with 99% accuracy and hosted online for prediction
- key insights from the data
What we learned
- a lot of machine learning
- BMI of 80 is apparently possible
- apparently everyone that has insurance is rich
- old people live exclusively live on the east coast
- move to Seattle to save money
- smoking saves you money on your premium
What's next for InsurED with Doge Senpai
- more insights
- more graphs
- more doge
- much wow
- meme3 coming to a town near you...

Log in or sign up for Devpost to join the conversation.