Inspiration
Medical bills are one of those documents that can instantly make a person feel powerless.
A patient may receive a bill filled with unfamiliar codes, repeated charges, vague service descriptions, and a final amount they do not know how to question. Most people are not medical billing experts. They may not know what a CPT code means, whether they were charged twice, whether a service was overbilled, or whether they may be eligible for reimbursement.
That confusion creates a real access problem. People may pay bills they do not understand, delay follow-up care, or avoid asking questions because the system feels too complicated.
We built InsurCheck to help change that.
Our goal was to create a tool that turns a confusing medical bill into a clear, structured, and actionable report. Instead of leaving patients with a wall of codes and charges, InsurCheck helps them understand what was billed, what may be suspicious, and what steps they can take next.
What it does
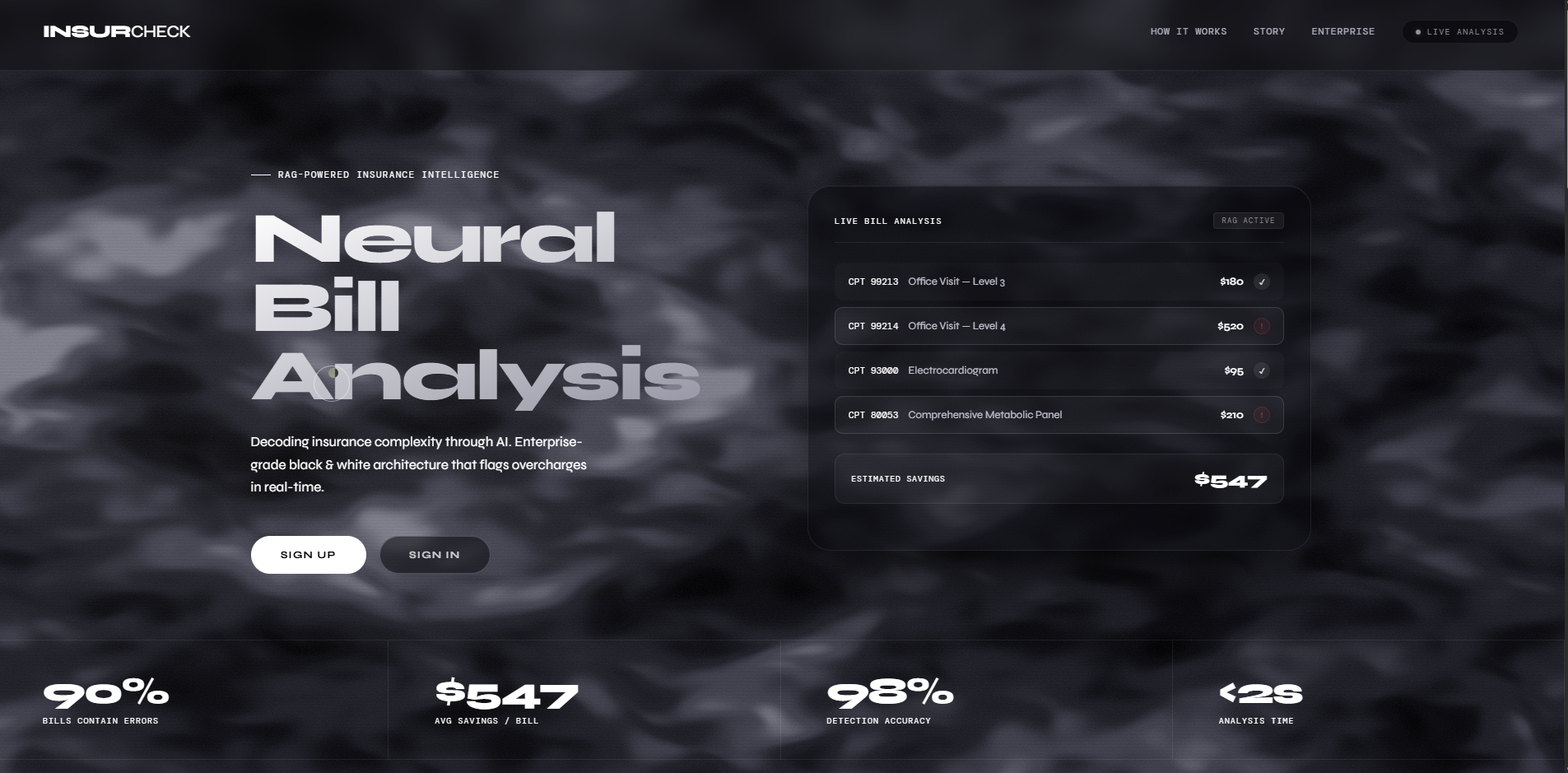
InsurCheck is an AI-powered medical bill validation and reimbursement assistant.
A user uploads a medical bill PDF, and the system:
- Extracts the bill text using PDF parsing.
- Reconstructs the bill into readable line items.
- Identifies billing codes, descriptions, quantities, unit prices, and totals.
- Runs a custom backend rule engine to detect suspicious billing patterns.
- Flags possible issues such as duplicate billing, missing information, unbundling, and potential overcharges.
- Retrieves relevant billing/code knowledge through a lightweight RAG pipeline.
- Uses IBM WatsonX with a Granite model to generate a plain-language explanation.
- Displays the results in an interactive React dashboard.
The final dashboard shows flagged charges, estimated savings, reimbursement eligibility, and next steps a patient can take when contacting their provider or insurer.
How we built it
We built InsurCheck as a full-stack application.
The frontend is built with React, Vite, JavaScript, and CSS. It provides a polished dashboard where users can upload bills, view reconstructed line items, inspect flagged billing codes, and read the generated analysis.
The backend is built with Java 21 and Spring Boot. It includes authentication with Spring Security and JWT, PDF text extraction with PDFBox, persistence with Spring Data JPA, and a modular custom rule engine.
The most important part of the system is that we do not blindly send a PDF to an AI model and hope for a useful answer.
Instead, the backend first performs deterministic validation:
- The PDF parser extracts raw bill text.
- The bill analysis service reconstructs structured bill data.
- The custom rule engine checks for billing problems.
- Rule violations are attached to affected line items.
- The RAG pipeline retrieves relevant billing knowledge.
- IBM WatsonX generates a patient-friendly explanation based on the validated findings.
This architecture makes the AI output more grounded, explainable, and useful.
Custom rule engine
We designed the rule engine so that each billing rule is modular and extendable.
Current rules include:
- Duplicate Billing Rule — detects repeated billing codes that may indicate a patient was charged twice.
- Missing Information Rule — flags bills missing important patient, provider, policy, date, or total information.
- Unbundling Rule — detects when services may have been billed separately instead of under a bundled code.
- Upcoding / Overcharge Rule — flags charges that appear unusually high compared to internal reference values.
Each rule returns structured violations that the frontend can display directly to the user.
This gives the system a real validation layer before WatsonX generates the explanation.
IBM WatsonX integration
We integrated IBM WatsonX to turn backend findings into natural, patient-friendly guidance.
After the rule engine identifies issues, the backend builds an augmented prompt using:
- extracted bill text
- patient and provider context
- billing codes
- detected rule violations
- CPT code explanations
- billing rule knowledge
- reimbursement guidance
- dispute process information
WatsonX then generates a clear explanation that tells the user what was found, why it matters, and what they can do next.
We also built a rule-based fallback system so that if the AI service is unavailable, the application can still return a useful analysis instead of failing completely.
Challenges we ran into
One of the biggest challenges was making the system more than just an AI wrapper.
It would have been easy to upload a PDF and ask an LLM to explain it. But that would not be reliable enough for a project about medical bills. We wanted the backend to do real work first.
So we focused on building a structured analysis pipeline:
PDF Upload
→ Text Extraction
→ Bill Reconstruction
→ Rule Engine Validation
→ RAG Pipeline
→ WatsonX Explanation
→ Frontend Dashboard
Built With
- css
- custom-billing-rule-engine
- granite-3-8b-instruct
- ibm-watsonx
- java-21
- javascript
- jwt
- lightweight
- pdfbox
- rag
- react
- react-three-fiber
- rest-apis
- spring-boot
- spring-data-jpa
- spring-security
- vite







Log in or sign up for Devpost to join the conversation.