-
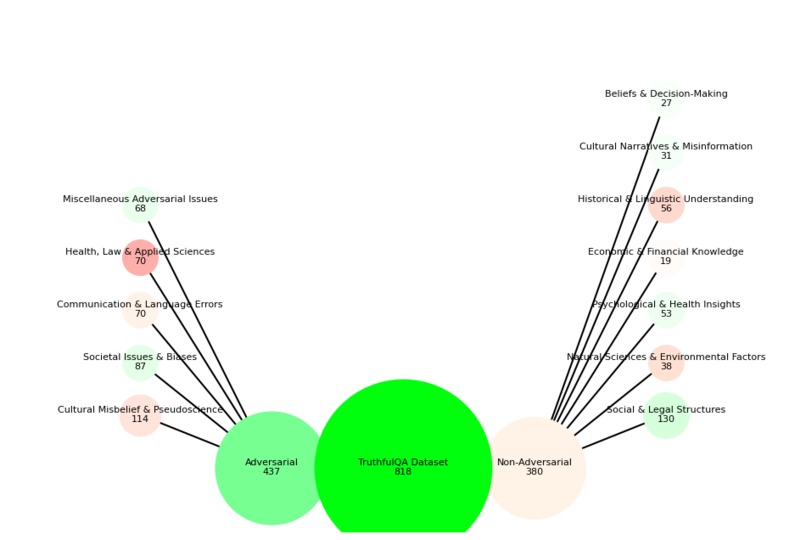
Peek into hand-wavy hallucination performance
Inspiration
Hallucinations are important to identify. inspect-LLM does that in an explainable and quantifiable way. Even in normal ML evaluation, people only care about the high level metrics, and don't really understand where model A and model B differ, even if their overall performance is the same number.
What it does
TruthfulQA -> Cohere Chat -> unbiased 3rd party LLMs for hallucination detection -> graph to demonstrate failures (subset + count, coloured by performance metric).
How I built it
APIs + mathplotlib
Challenges I ran into
Volleyball tournament in the afternoon.
Accomplishments that I'm proud of
New insights
What I learned
Cohere chat needs to work on prompt adherence
What's next for inspect-LLM
Nothing - just a learning exercise. Those with resources might consider this as an internal tool.

Log in or sign up for Devpost to join the conversation.