-
-
Demo
-
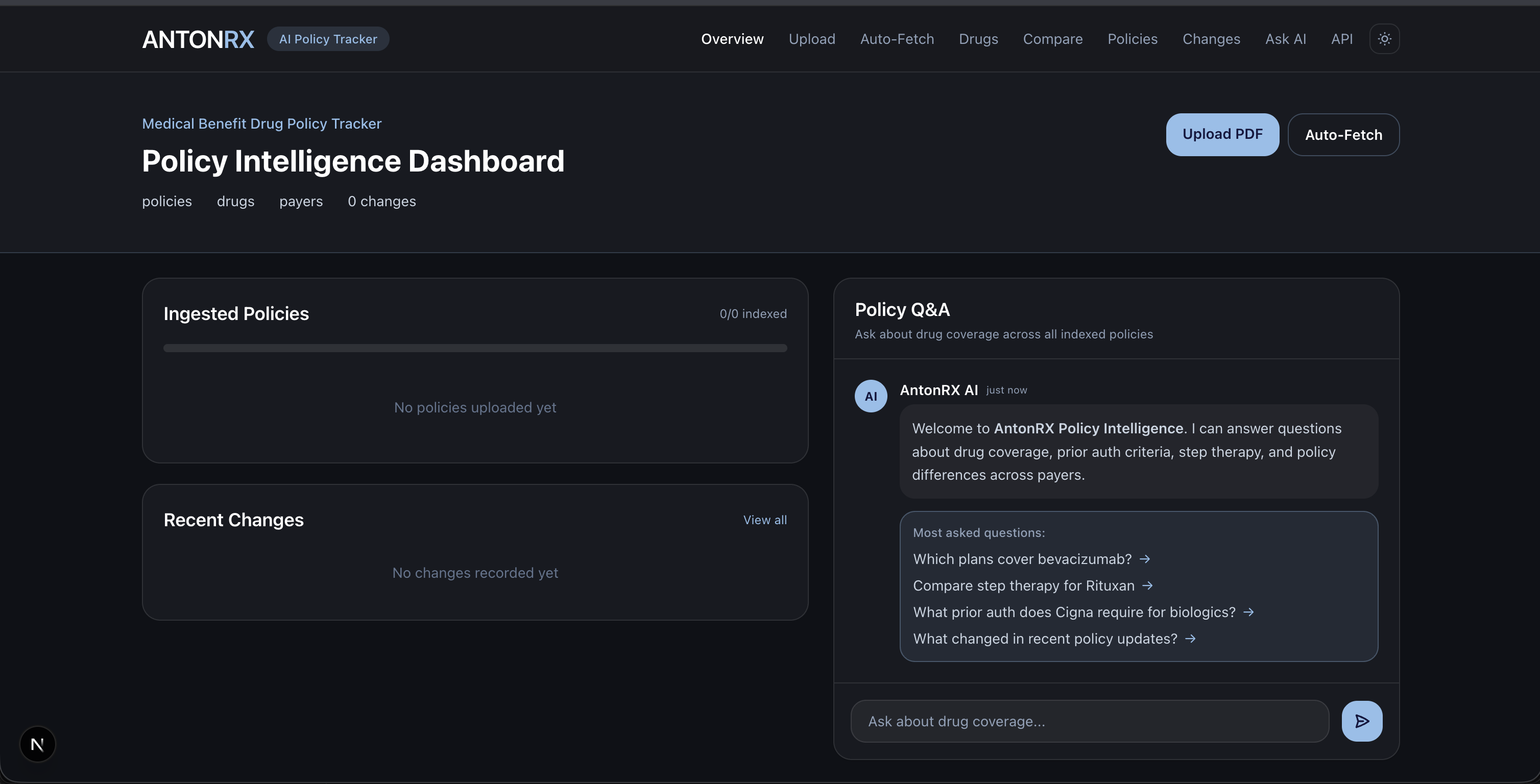
Dashboard
-
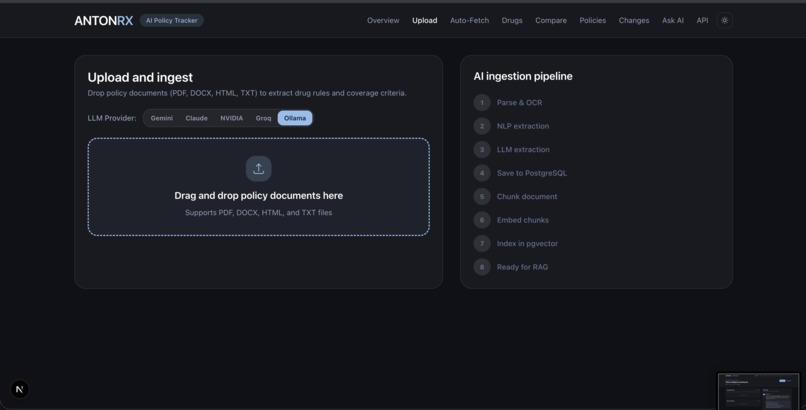
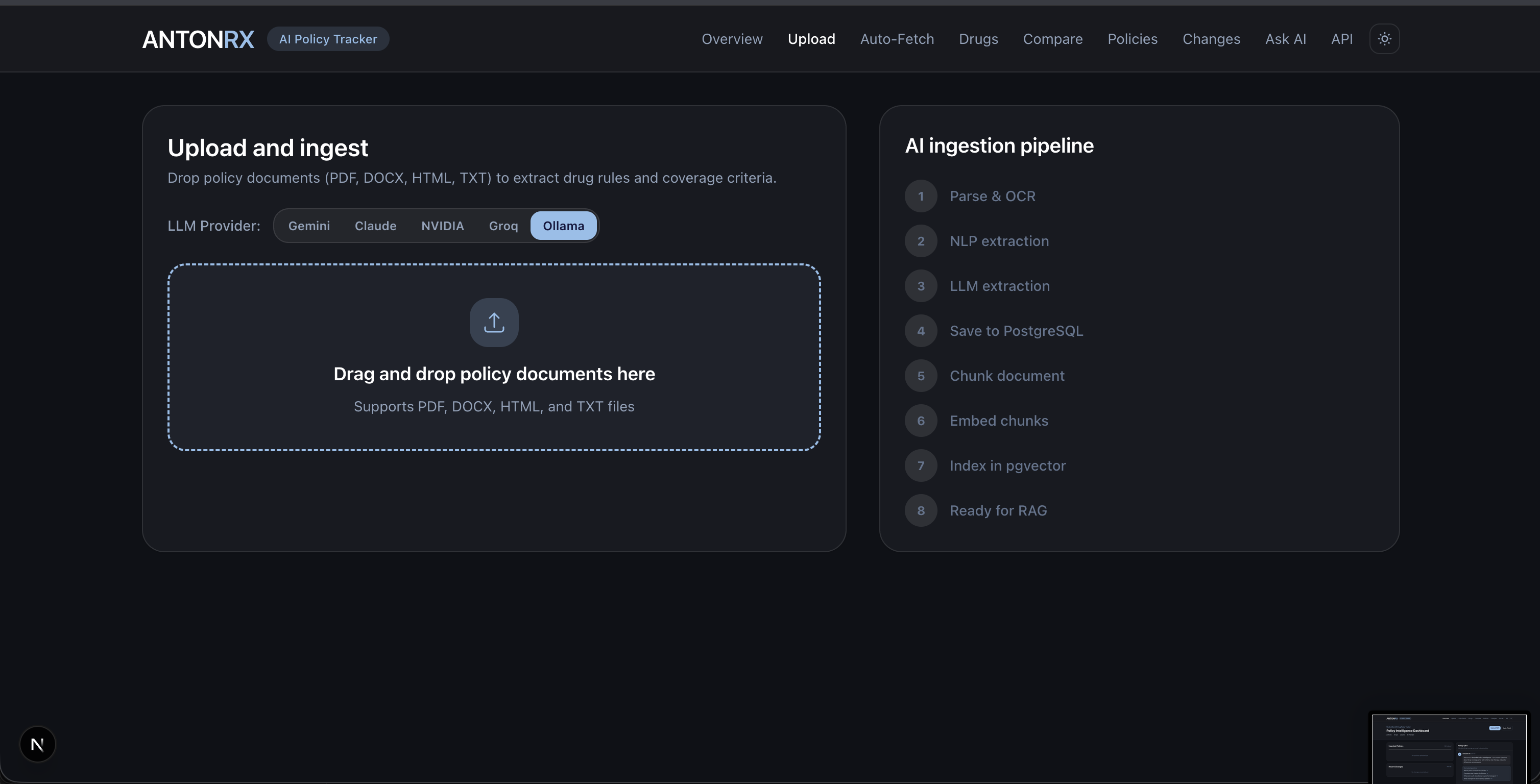
Image Upload
-
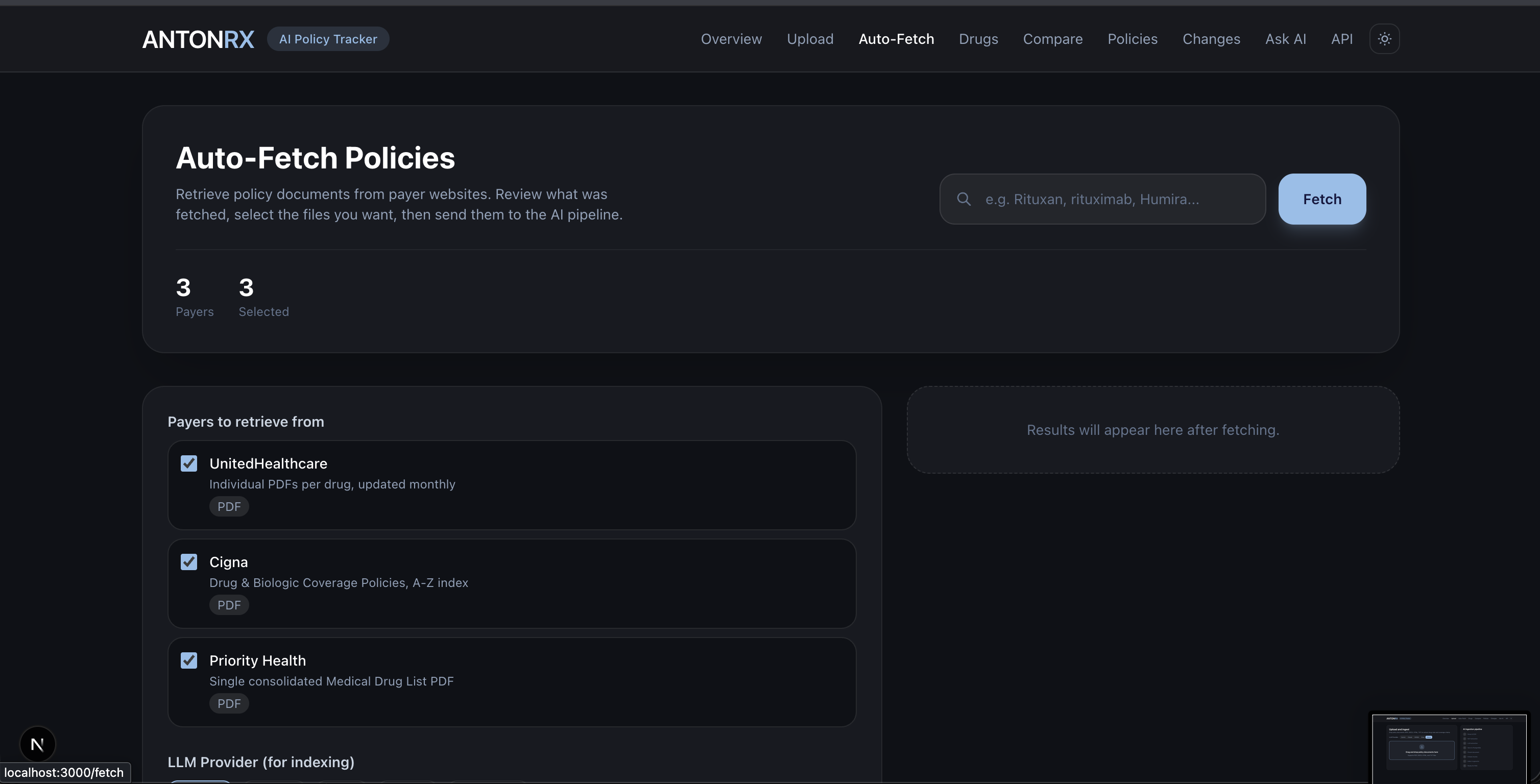
Auto Fetch From Insurance
-
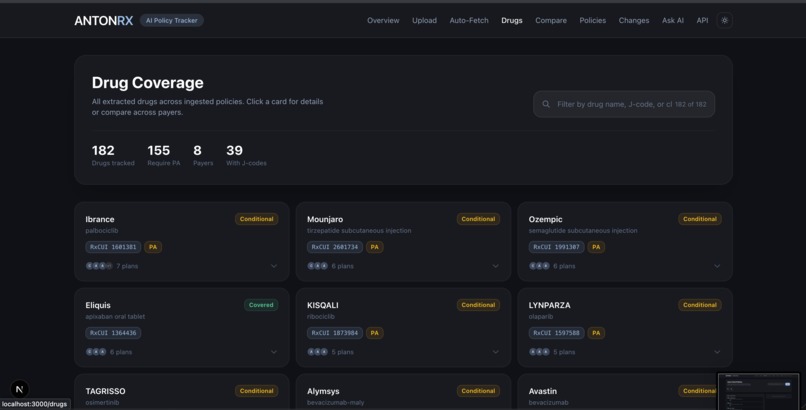
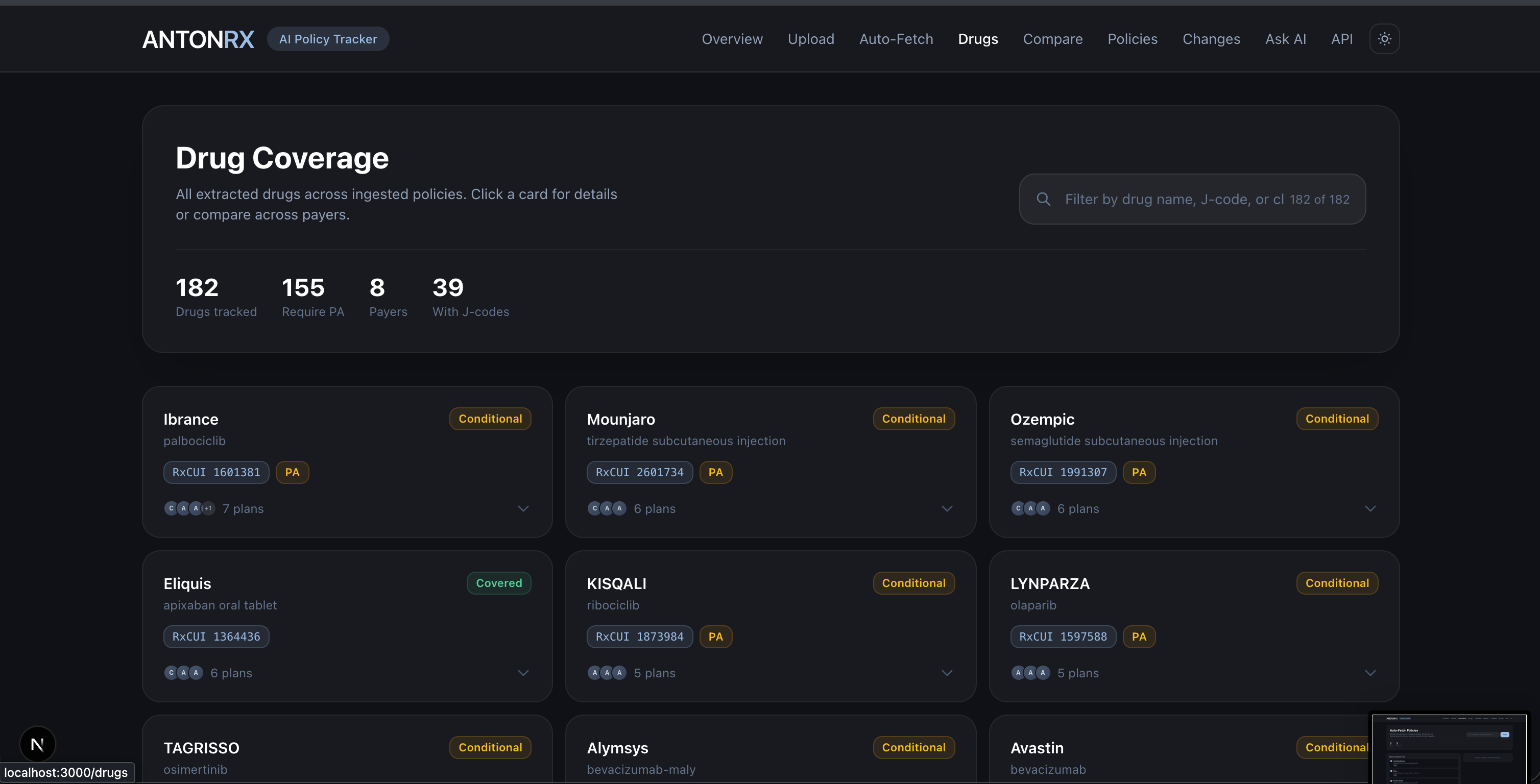
Drug Search
-
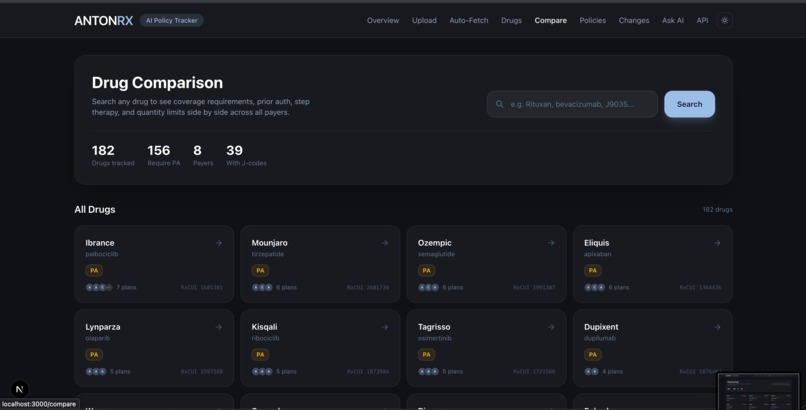
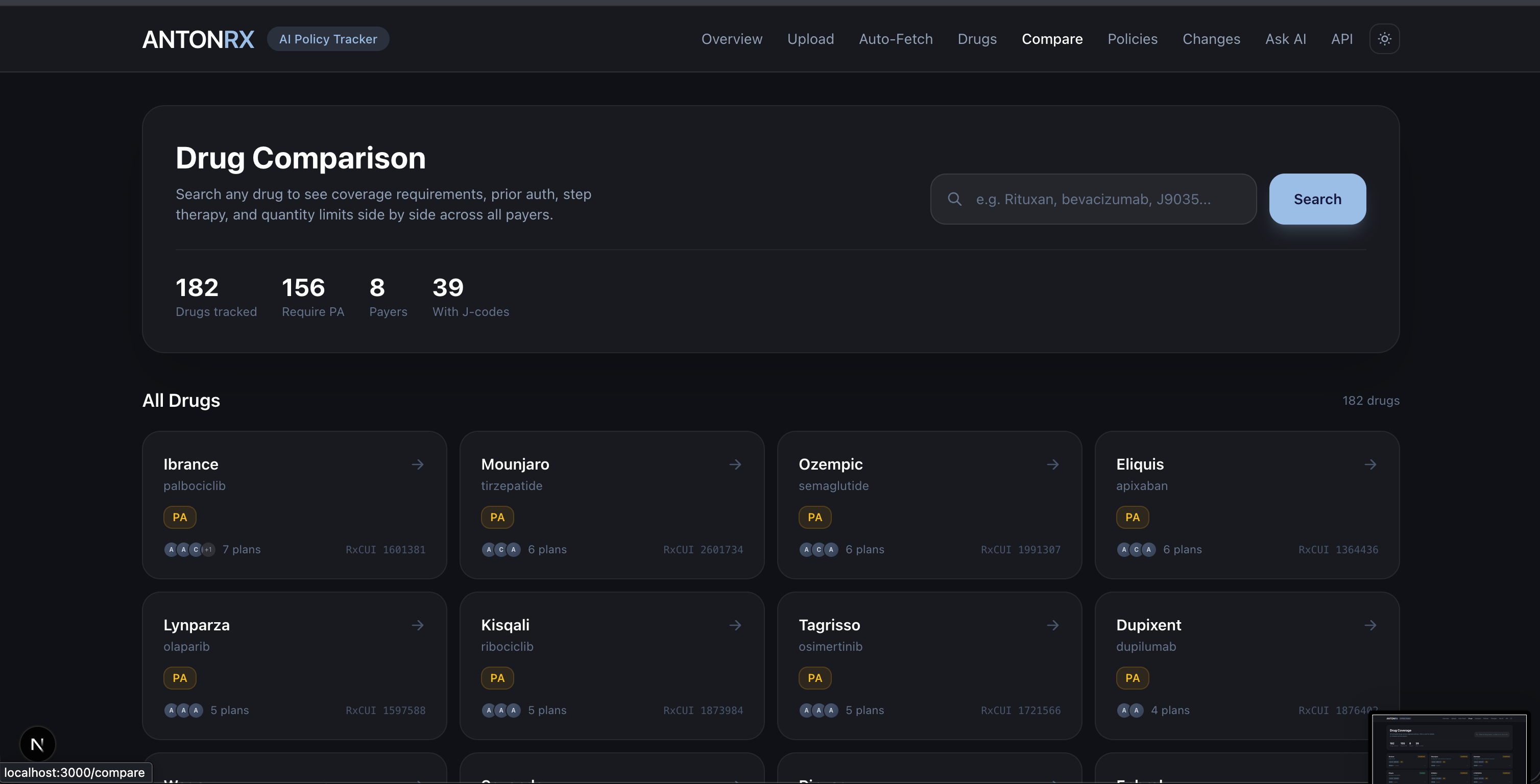
Policy Drug Compare
-
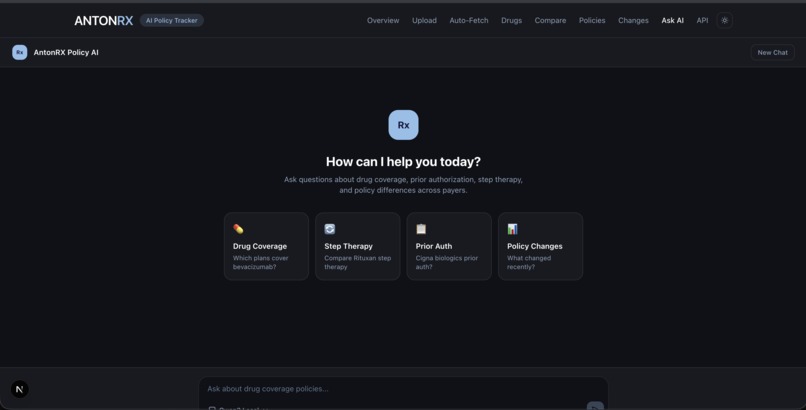
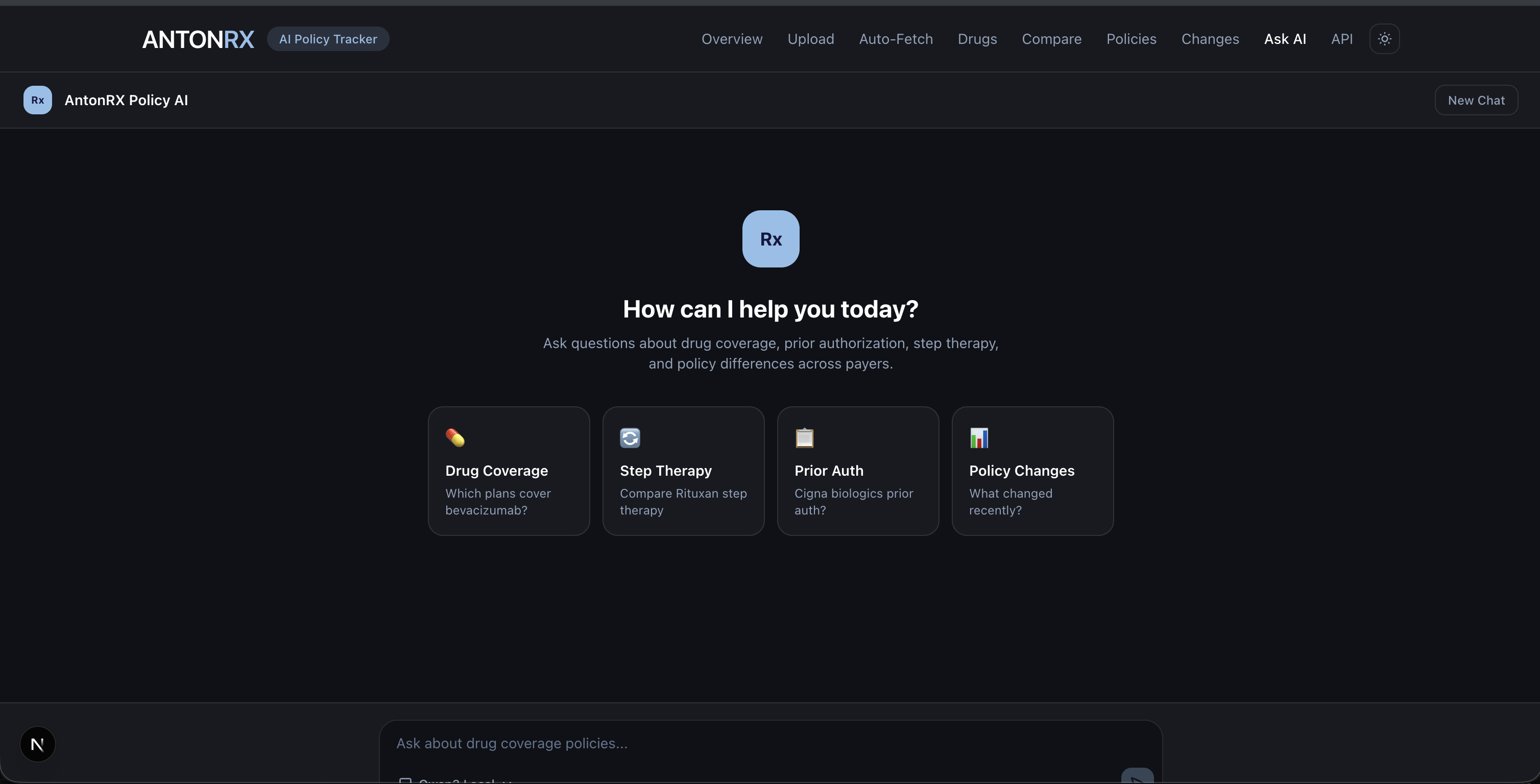
AI Chat
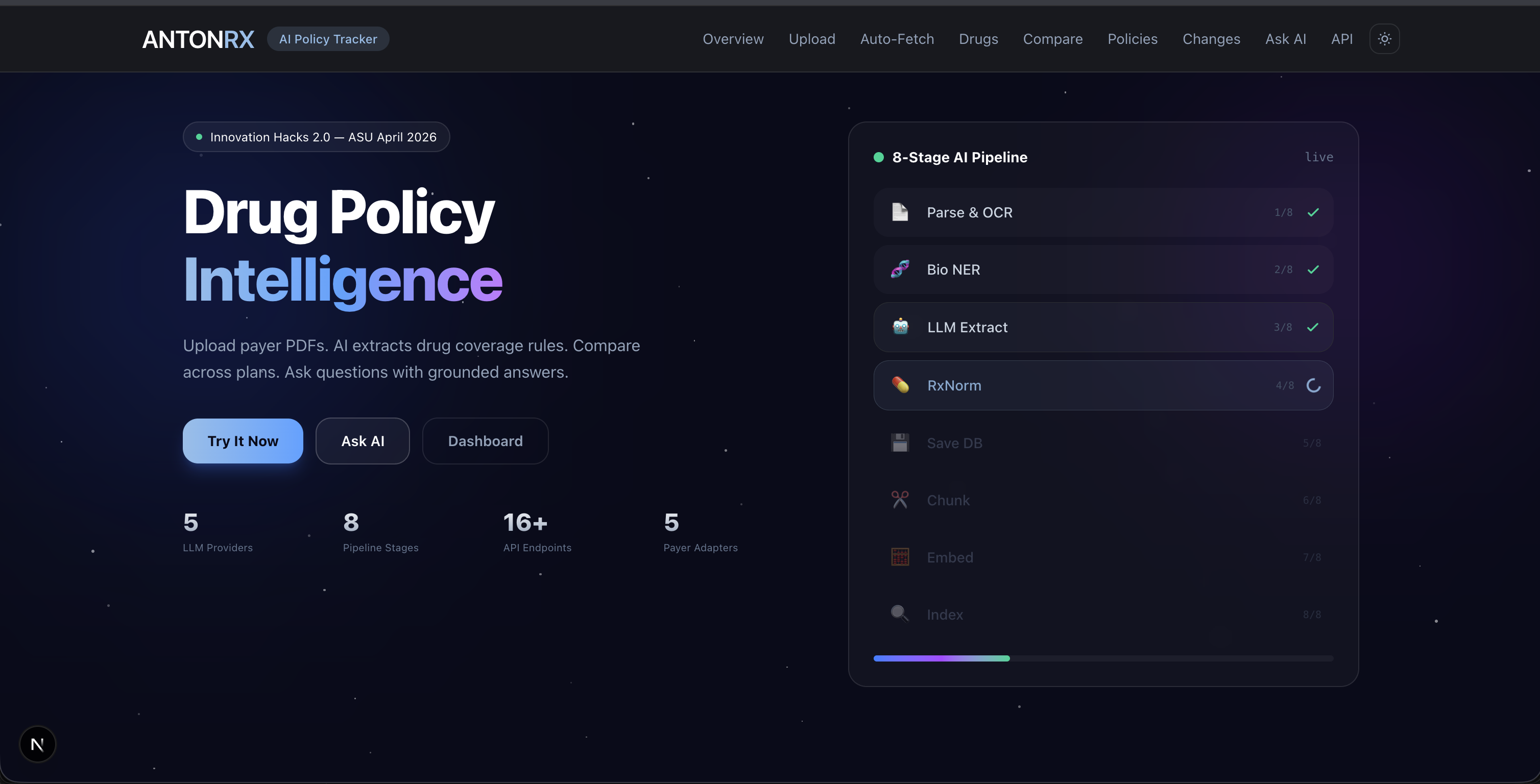
InsightRX
Project Name
InsightRX
Tagline
AI-powered drug policy intelligence — upload payer PDFs, compare coverage across plans, and get cited answers in seconds.
Inspiration
Medical benefit drug policies are buried in 200+ page PDFs from every payer. Right now, healthcare teams manually dig through these documents to figure out if a drug like bevacizumab is covered by Cigna vs. UHC, what prior auth is needed, and whether step therapy is required. It takes hours per drug, per plan. When policies update, nobody finds out until a claim gets denied.
We wanted to build the tool that should already exist: one place where you search a drug and instantly see coverage, PA requirements, step therapy, and quantity limits across every payer — backed by the actual policy text, not guesswork.
What it does
InsightRX is a full-stack policy intelligence workspace that turns messy payer PDFs into structured, searchable, comparable data.
Core features:
- Drug Search — Search by drug name, generic name, or J-code. Results show coverage status across all indexed payers with RxNorm-normalized identities.
- Cross-Payer Comparison — Select any drug and get a side-by-side matrix: coverage status, prior authorization, step therapy, quantity limits, site-of-care restrictions, and approved ICD-10 diagnoses for every plan.
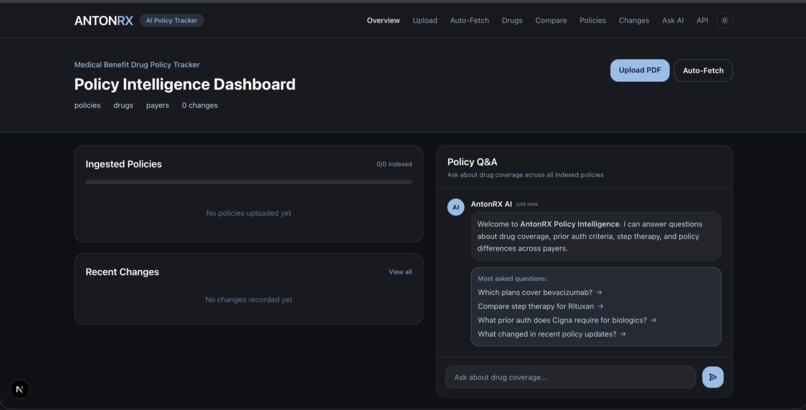
- Policy Q&A (RAG Chat) — Ask natural language questions like "Which plans cover Rituxan?" and get grounded answers with source citations pulled from indexed policy text.
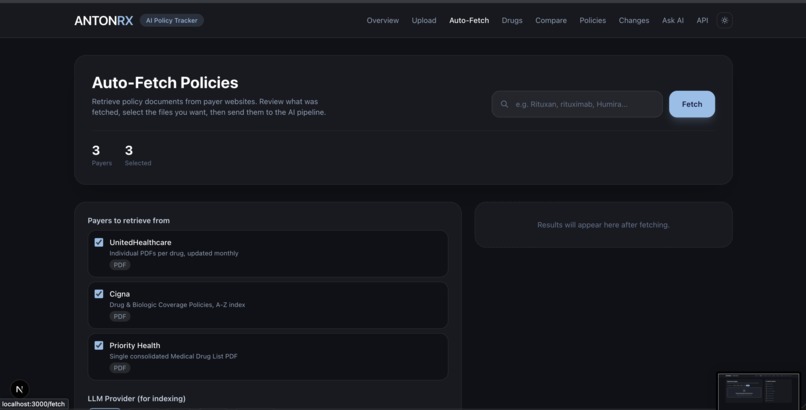
- Auto-Fetch — Pull policy documents directly from supported payer websites (UnitedHealthcare, Cigna, Priority Health) without manual downloads.
- Change Detection — When a new version of a policy is uploaded, the system computes text diffs + semantic similarity and classifies changes as breaking, material, minor, or cosmetic with LLM-generated summaries.
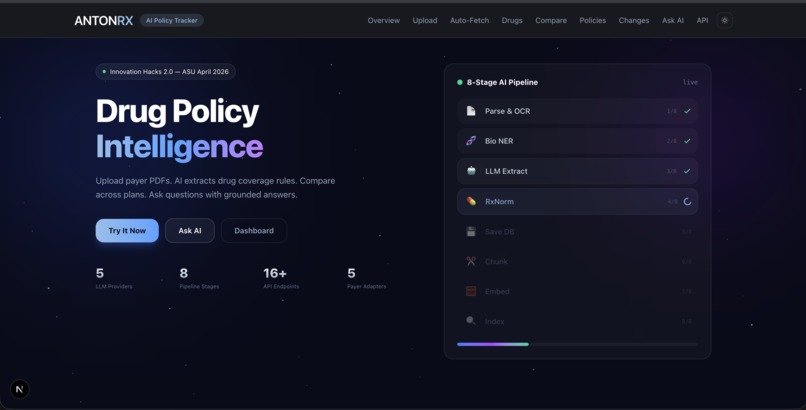
- Upload & Ingest — Upload any payer PDF and run it through an 8-stage pipeline that parses, extracts, normalizes, and indexes the document automatically.
- Dashboard — Live stats, recently indexed policies, change timeline, and embedded Q&A — all in one view.
- Interactive API Docs — Full OpenAPI reference for all 16 endpoints across both stacks.
How we built it
InsightRX is a dual-stack application:
Frontend — Next.js 16 / React 19 / TypeScript / Tailwind CSS 4
- 11 pages: dashboard, drug search, drug detail, policies, policy detail, compare, changes, chat, fetch, upload, API docs
- Reusable components: CoverageMatrix, DrugSearch, ChatInterface, ChangeTimeline, PolicyCard, Dropzone
- shadcn/ui component library with full dark mode
- BFF pattern: Next.js API routes proxy to FastAPI for ingestion/query, and hit Neon Postgres directly via Drizzle ORM for reads
Backend — FastAPI / Python / SQLAlchemy
- 8-stage ingestion pipeline:
- Parse — Docling (97.9% table accuracy) with Marker fallback
- NLP Extract — scispaCy NER + Med7 for drug names, codes, dosages
- LLM Extract — Gemini 2.5 Flash structured output grounded in NLP hints
- RxNorm Normalize — NIH RxNorm API maps drugs to RxCUI identifiers
- Store — Structured records saved to PostgreSQL (12 tables)
- Chunk — Paragraph-aware sliding window chunking
- Embed — Gemini text-embedding-004 with batched generation
- Index — pgvector with HNSW indexing + metadata filters
- Hybrid RAG: structured SQL lookup + vector similarity search for retrieval, Gemini for answer generation with citations
- Policy fetchers: site-specific scrapers for Cigna, UHC, Priority Health
- Change detector: text diff (SequenceMatcher) + semantic diff (cosine similarity) + LLM significance classification
Database — PostgreSQL 16 + pgvector (Neon)
- 12 tables: payers, plans, policies, policy_versions, drug_coverages, clinical_criteria (tree structure), step_therapy, quantity_limits, site_of_care, provider_requirements, document_chunks (768-dim vectors), audit_log
- IVFFlat index on 768-dimensional embeddings for fast similarity search
Multi-Provider LLM Support
- Gemini, Anthropic, Groq, NVIDIA, and local Ollama — switchable per request
Challenges we ran into
- Table extraction accuracy: Medical policy PDFs have complex multi-column tables with merged cells for drug lists, HCPCS codes, and ICD-10 criteria. We tried multiple parsers before settling on Docling, which hit 97.9% accuracy on our test set.
- Drug identity resolution: The same drug appears as "Rituxan", "rituximab", "J9312" across different payers. We built a normalization layer using the NIH RxNorm API to map everything to canonical RxCUI identifiers so comparisons actually work.
- Grounding LLM extraction: Raw LLM extraction hallucinated drug names and codes. We solved this by running scispaCy/Med7 NER first, then passing those NLP-extracted entities as grounding hints to the Gemini structured extraction step — dramatically improving accuracy.
- Change detection at scale: Simple text diffs produce noise. We combined section-level text diff with cosine similarity of section embeddings to classify changes by significance (breaking/material/minor/cosmetic), so users know what actually matters.
- Dual-stack coordination: Running Next.js and FastAPI together with shared database access required careful API design. The BFF pattern (Next.js API routes as proxy) kept the frontend clean while letting the Python backend own all AI/NLP logic.
Accomplishments that we're proud of
- Built a fully functional 8-stage ingestion pipeline that takes a raw payer PDF and produces structured, searchable, comparable drug coverage data — end to end, no manual steps.
- Cross-payer comparison matrix that shows coverage, prior auth, step therapy, quantity limits, site-of-care, and ICD-10 criteria side-by-side for any drug.
- RAG-powered Q&A that returns cited answers grounded in actual policy text, not hallucinated responses.
- Semantic change detection that classifies policy updates by real clinical impact (breaking vs. cosmetic).
- Multi-provider LLM support — swap between Gemini, Anthropic, Groq, NVIDIA, or local Ollama without code changes.
- Clean, polished UI with dark mode, responsive layout, and a dashboard that actually feels like a production tool.
What we learned
- Biomedical NLP is a different world — scispaCy and Med7 exist specifically for clinical text and outperform general-purpose NER on drug names, dosages, and medical codes.
- RxNorm is essential for any drug comparison system — without normalized identifiers, cross-payer comparisons are meaningless.
- Grounding LLM outputs in upstream NLP results (not just raw text) is the key to accurate structured extraction from messy documents.
- pgvector with HNSW indexing makes hybrid RAG (structured SQL + vector similarity) practical at query time without a separate vector database.
- Docling's TableFormer is genuinely best-in-class for extracting tabular data from PDFs — we benchmarked it against Marker, Unstructured, and Tika.
What's next for InsightRX
- More payer adapters — Extend auto-fetch to Aetna, Humana, BCBS, and Medicaid/Medicare sources.
- Automated monitoring — Scheduled policy re-fetches with alerts when breaking changes are detected.
- FHIR integration — Export structured coverage data as FHIR CoverageEligibilityResponse resources for EHR integration.
- Formulary support — Extend beyond medical benefit drugs to pharmacy benefit formularies.
- Multi-tenant deployment — Role-based access so different teams (pharmacy, medical affairs, market access) can share one instance.
Built With
next.js react typescript tailwindcss fastapi python postgresql pgvector drizzle-orm sqlalchemy google-gemini docling rxnorm scispacy shadcn-ui neon docker zod
Try it out
- GitHub: https://github.com/hackathon-asu/InnovationHacks26
- Demo Video: https://youtu.be/42bPqaOjiuY
Team
- Abhinav
- Neeharika
- Adi
Team: The Formulators | Innovation Hacks 2.0 @ ASU
Built With
- docker
- docling
- fastapi
- gemini
- javascript
- neon
- pgvector
- postgresql
- python
- react
- sqlalchemy
- tailwind
- typescript

Log in or sign up for Devpost to join the conversation.