-
-
architecture
-
website
-
sidebar
Inspiration
We've all encountered data tables and charts while browsing but lacked tools to quickly understand them. Copying data into spreadsheets just to answer simple questions is tedious. We wanted to build an AI assistant that analyzes data directly on any webpage - no setup required.
What it does
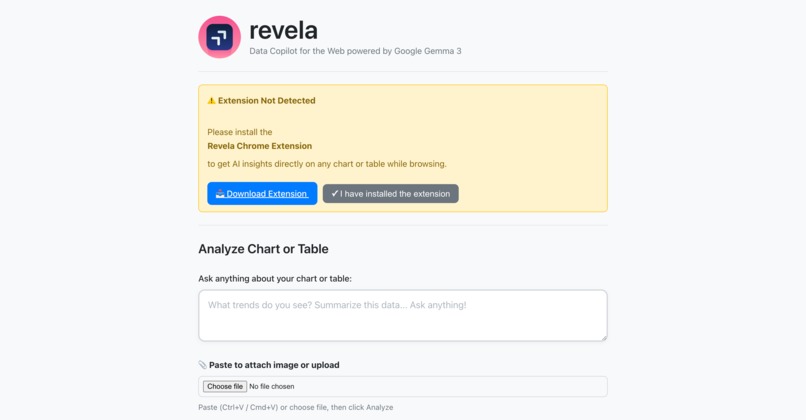
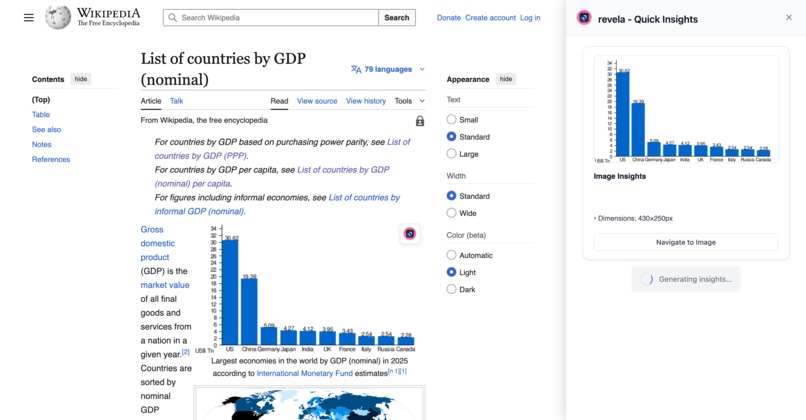
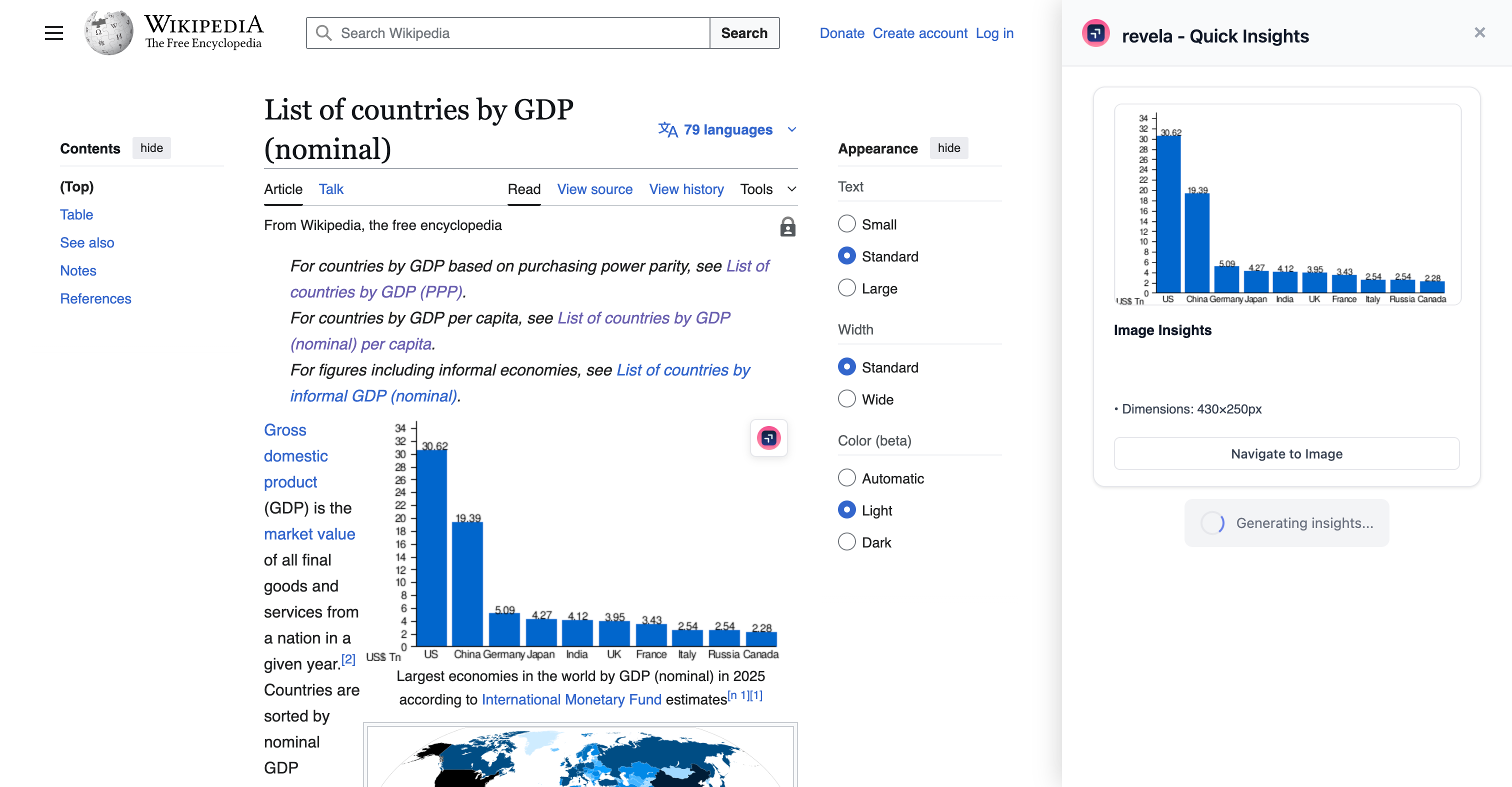
Revela is a Chrome extension that provides AI-powered analysis of tables and charts on any webpage.
Hover over a table or chart to see instant insights. Click "Deep Analyze" to open a chat sidebar where you can ask questions or request visualizations. Sessions are ephemeral with automatic cleanup - no data is stored.
How we built it
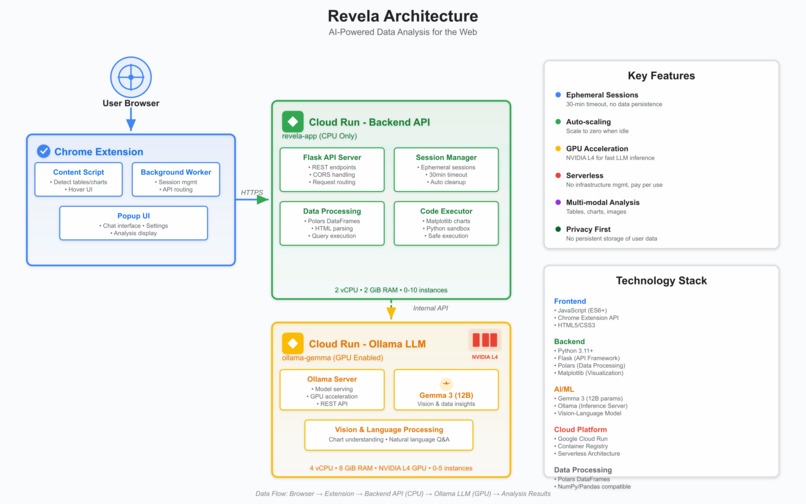
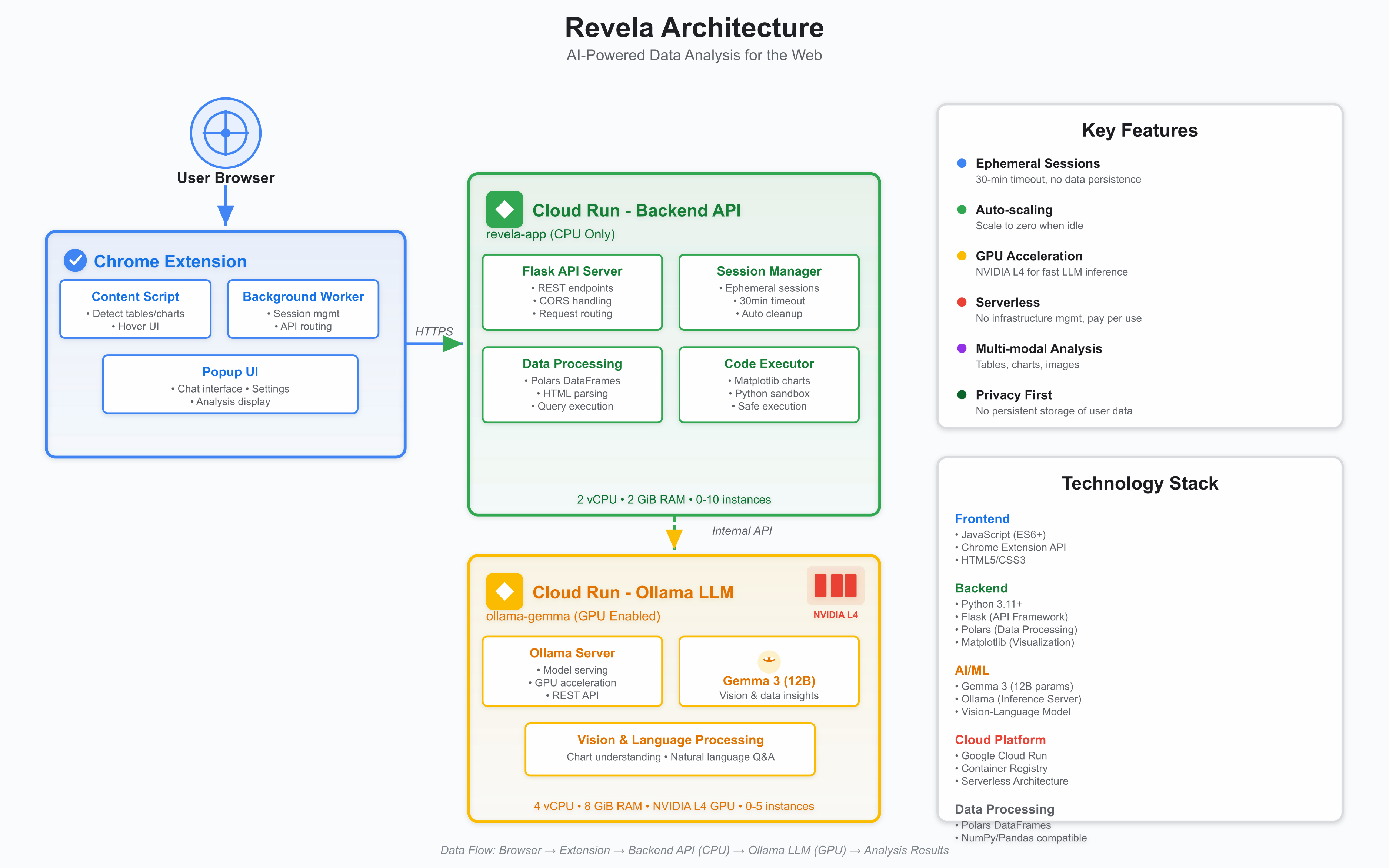
We built Revela entirely on Google Cloud Run, leveraging its unique ability to handle both CPU and GPU workloads in a serverless architecture.
Flask API (Cloud Run - CPU): The main backend service manages sessions, processes data with Polars, and generates charts. Deployed directly from source code with Cloud Run's source deployment feature. Auto-scales from 0-10 instances based on traffic.
Ollama LLM (Cloud Run - GPU): Runs Google Gemma 3 (12B) with NVIDIA L4 GPU acceleration. This is where Cloud Run truly shines - we get GPU-powered inference that scales to zero when idle, something traditional GPU infrastructure can't offer. Auto-scales 0-5 GPU instances.
Chrome Extension: Browser integration that detects tables/images and provides the UI.
Cloud Run's service-to-service authentication secures communication between the Flask API and Ollama container. The scale-to-zero capability means we only pay for actual usage, making GPU inference economically viable. Auto-scaling handles traffic spikes seamlessly without manual intervention.
Tech Stack: Google Cloud Run (CPU & GPU), Gemma 3, Ollama, Flask, Polars, Python, Docker.
Challenges we ran into
GPU cold starts on Cloud Run took some time for the Ollama container. We tuned minimum instances during peak usage to balance cost and performance.
HTML table extraction across diverse websites required building a robust parser that handles inconsistent structures.
Managing state in a stateless Cloud Run environment required careful session design with in-memory storage and automatic cleanup.
Accomplishments that we're proud of
Successfully deployed a production-ready system using Cloud Run's GPU support for LLM inference - proving you can build sophisticated AI services entirely serverless.
The architecture scales to zero when idle, eliminating infrastructure costs during downtime while maintaining instant availability when needed. This cost-efficiency would be impossible with traditional GPU deployments.
We leveraged Cloud Run's source deployment to ship both services without complex CI/CD pipelines, and IAM-based service authentication for secure inter-service communication.
What we learned
Cloud Run transforms AI infrastructure. The ability to run GPU workloads serverlessly with scale-to-zero is a game-changer. Traditional GPU deployments require expensive always-on instances, but Cloud Run only charges for actual inference time.
Source deployment makes iteration incredibly fast - push code and Cloud Run handles containerization and deployment.
Service-to-service authentication with IAM provides security without managing API keys or tokens.
The combination of CPU and GPU instances in the same platform lets you optimize each service independently - lightweight orchestration on CPU, heavy inference on GPU.
What's next for Revela
Next, I plan to turn Revela into a stable, production-ready product and publish it on the Chrome Web Store. After launch, I’ll focus on improving reliability, tuning performance, and expanding features based on real user feedback.
Built With
- chrome
- cloudrun
- docker
- flask
- gemma
- javascript
- ollama
- polars
- python
Log in or sign up for Devpost to join the conversation.