-
-
insightforge-upload-flow
-
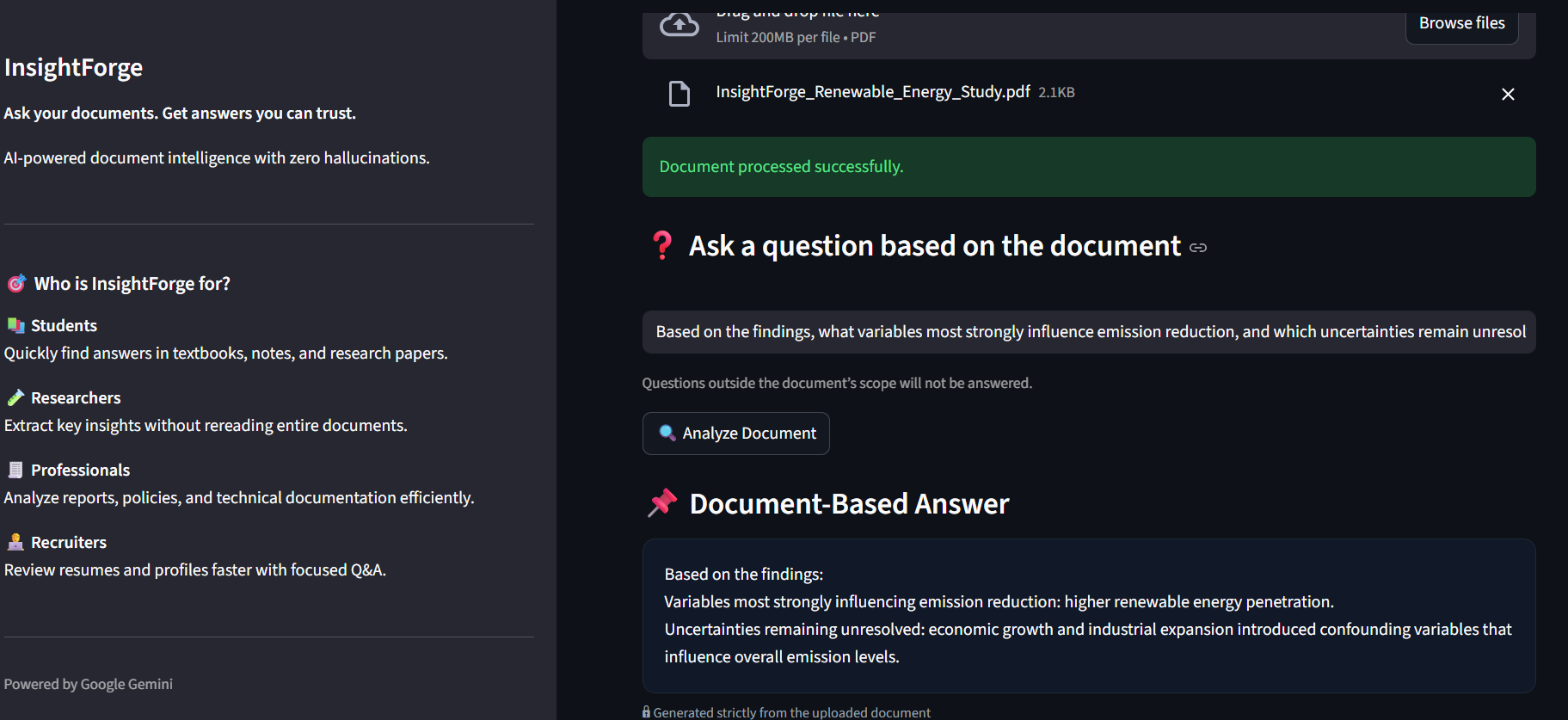
insightforge-document-answer
-
insightforge-target-users
📘 About InsightForge
💡 Inspiration
While working with academic papers, reports, and technical PDFs, I noticed a recurring problem:
finding precise answers inside long documents is slow, manual, and error-prone.
General-purpose AI tools can answer questions, but they often mix external knowledge, hallucinate facts, or go off-document, which makes them unreliable for serious academic or professional work.
I wanted to build a system that respects a strict boundary:
If the answer is not in the document, it should not be generated.
This idea of trust-first document intelligence became the foundation of InsightForge.
🧠 What I Learned
Through this project, I gained hands-on experience with:
- Designing constraint-based AI systems that prioritize correctness over creativity
- Working with large language models responsibly, preventing hallucinations
- PDF text extraction challenges and real-world document variability
- Building clean, user-focused interfaces using Streamlit
- Secure environment handling using
.envfiles and API key management - Deploying AI applications using Streamlit Community Cloud
Most importantly, I learned that AI products are not about power — they are about control and trust.
🛠️ How I Built InsightForge
InsightForge follows a simple but strict pipeline:
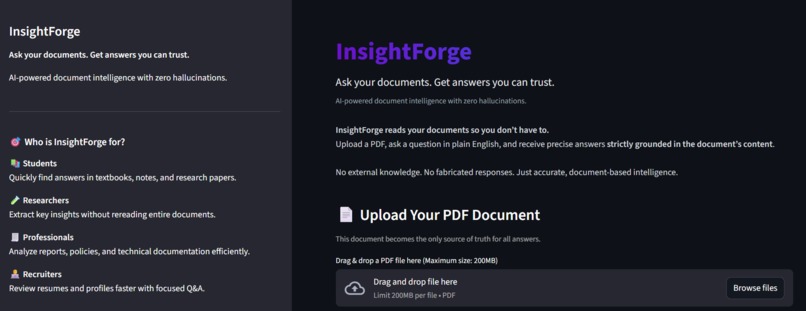
PDF Upload
Users upload a PDF document, which becomes the only source of truth.Text Extraction
The document is parsed using a PDF extraction pipeline, ensuring readable text is captured page by page.Context-Locked Prompting
A carefully designed prompt instructs the AI model to:- Use only the provided document
- Reject questions outside the document’s scope
- Avoid external knowledge or assumptions
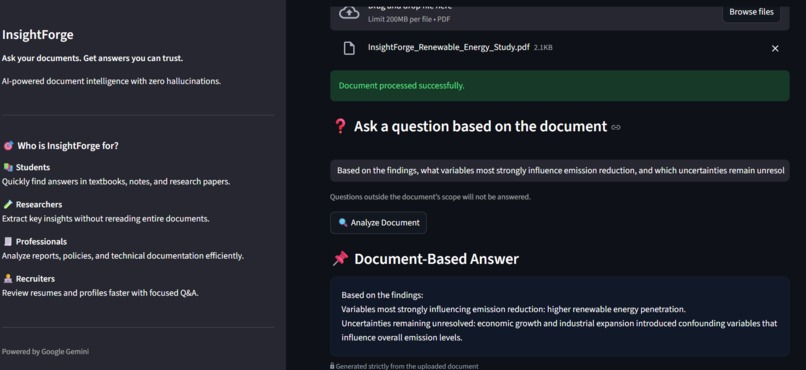
AI Processing
Google Gemini processes the request under these constraints and generates a response grounded strictly in the document.Clear Output
The response is displayed in a clean UI with trust indicators to reassure users of its reliability.
⚙️ Tech Stack
- Frontend: Streamlit
- AI Model: Google Gemini
- Backend Logic: Python
- Document Processing: PyPDF-based text extraction
- Deployment: Streamlit Community Cloud
🚧 Challenges Faced
Model Compatibility Issues:
Handling evolving AI model versions and API changes required careful debugging and version control.Preventing Hallucinations:
Designing prompts that strictly limit the model to document content was non-trivial and required iteration.PDF Variability:
Not all PDFs extract cleanly; handling empty or malformed text was a real-world challenge.Deployment Configuration:
Managing environment variables and ensuring secure API usage during deployment took careful setup.
Each challenge strengthened the system and made the final product more robust.
🎯 Why InsightForge Matters
InsightForge is not a chatbot replacement.
It is a focused intelligence tool built for scenarios where accuracy matters more than creativity.
By enforcing strict document grounding, InsightForge enables:
- Faster learning
- Better decision-making
- Trustworthy AI assistance
This project represents my approach to AI:
responsible, precise, and purpose-driven.

Log in or sign up for Devpost to join the conversation.