-
-
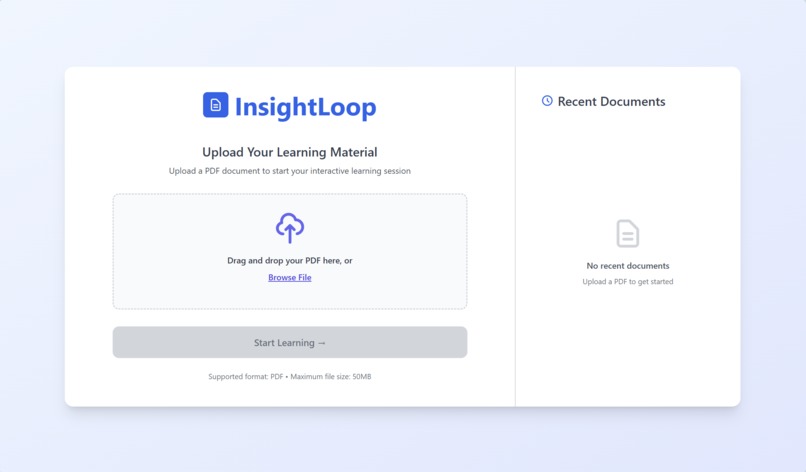
Landing Page
-
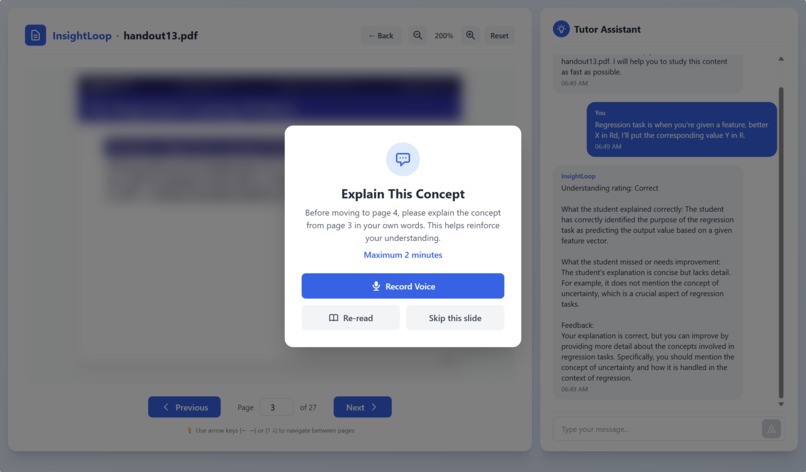
Explaining
-
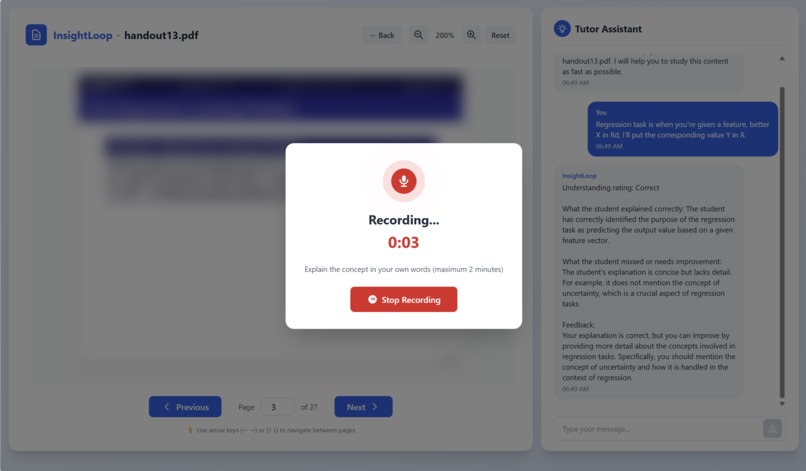
Recording
-
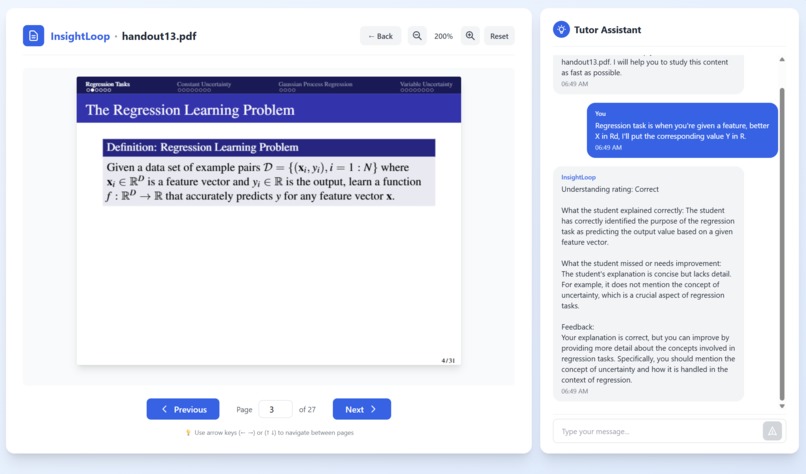
CheckingLLM
-
AskingLLM

Inspiration
Students rarely fail because they lack access to information, such as slides, PDFs, videos, and endless online resources are everywhere. What they lack is someone who listens to their explanations, catches confusion as it forms, and helps them clarify their thinking before moving on. True understanding isn’t watching content; it’s being able to explain a concept in your own words, clearly and confidently. Human tutors excel at this by noticing hesitation, reading facial cues, and sensing uncertainty in real time, but tutors are expensive, scarce, and not scalable. With advances in edge AI and multimodal sensing, we saw an opportunity to bring that same presence and responsiveness to every student: a private, on-device tutor that listens, watches, evaluates understanding, and steps in the moment learning starts to slip, all without relying on the cloud.
What it does
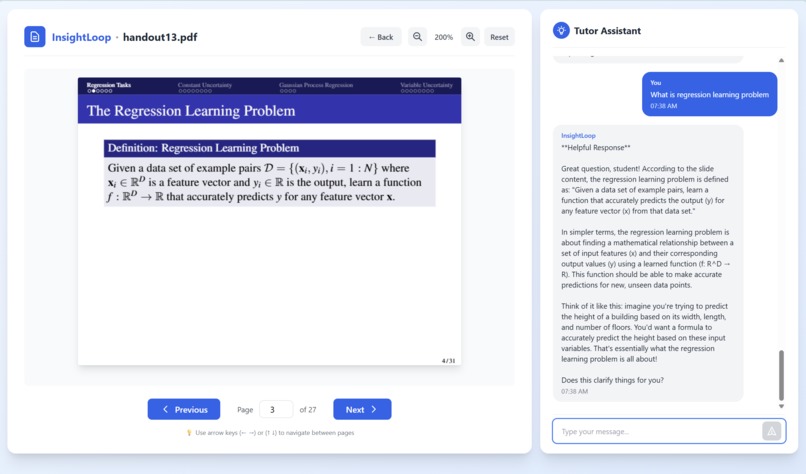
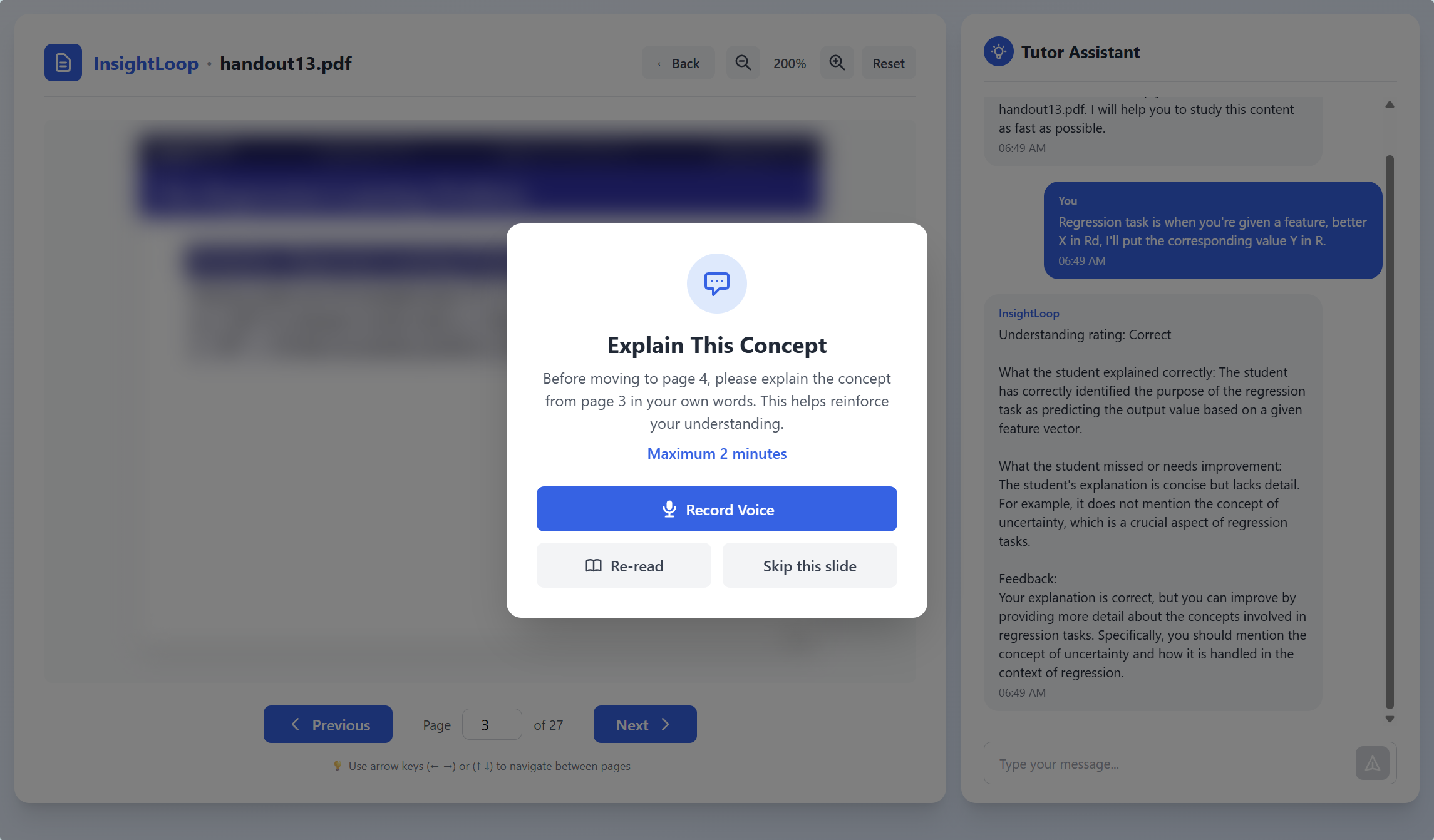
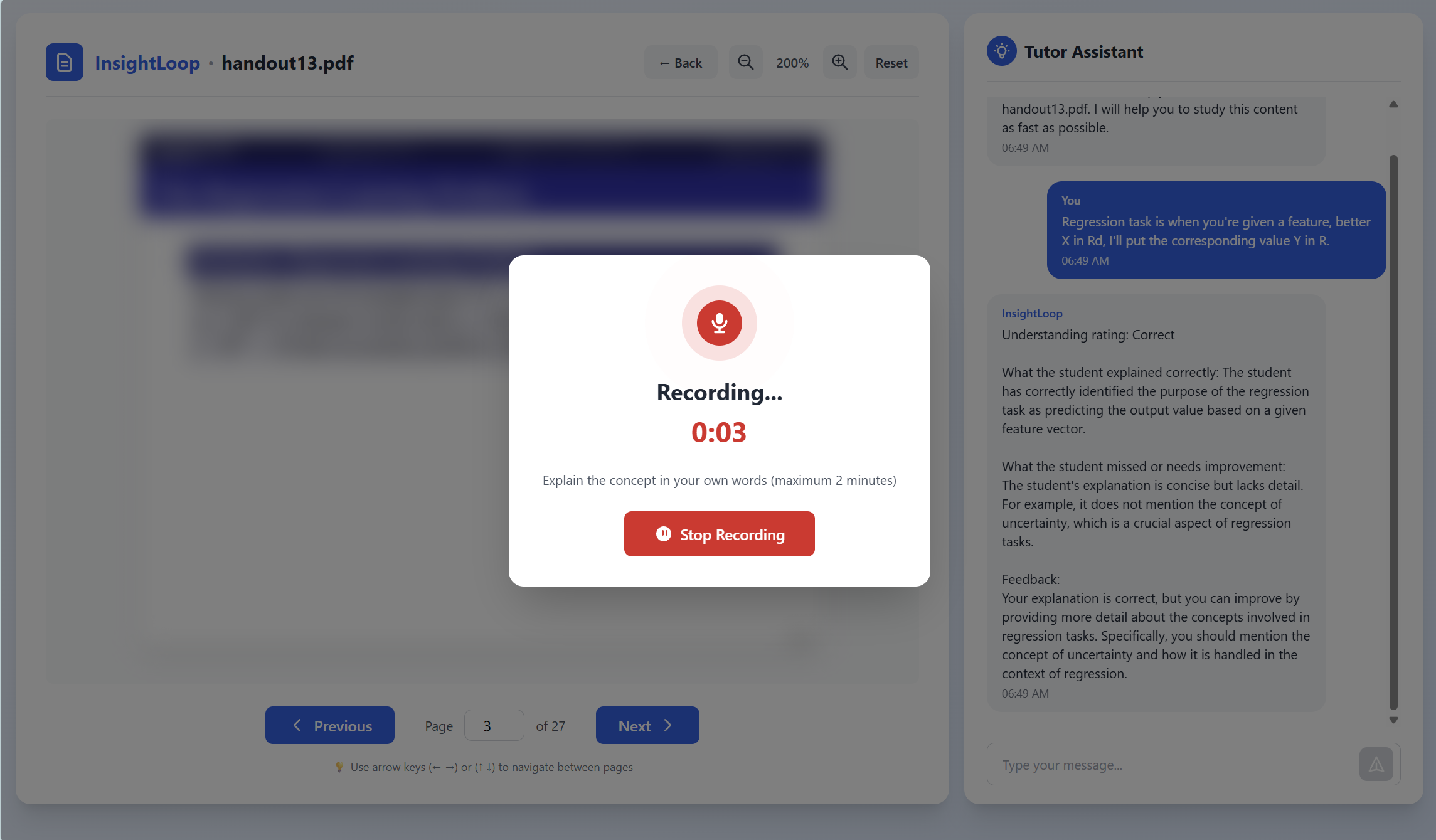
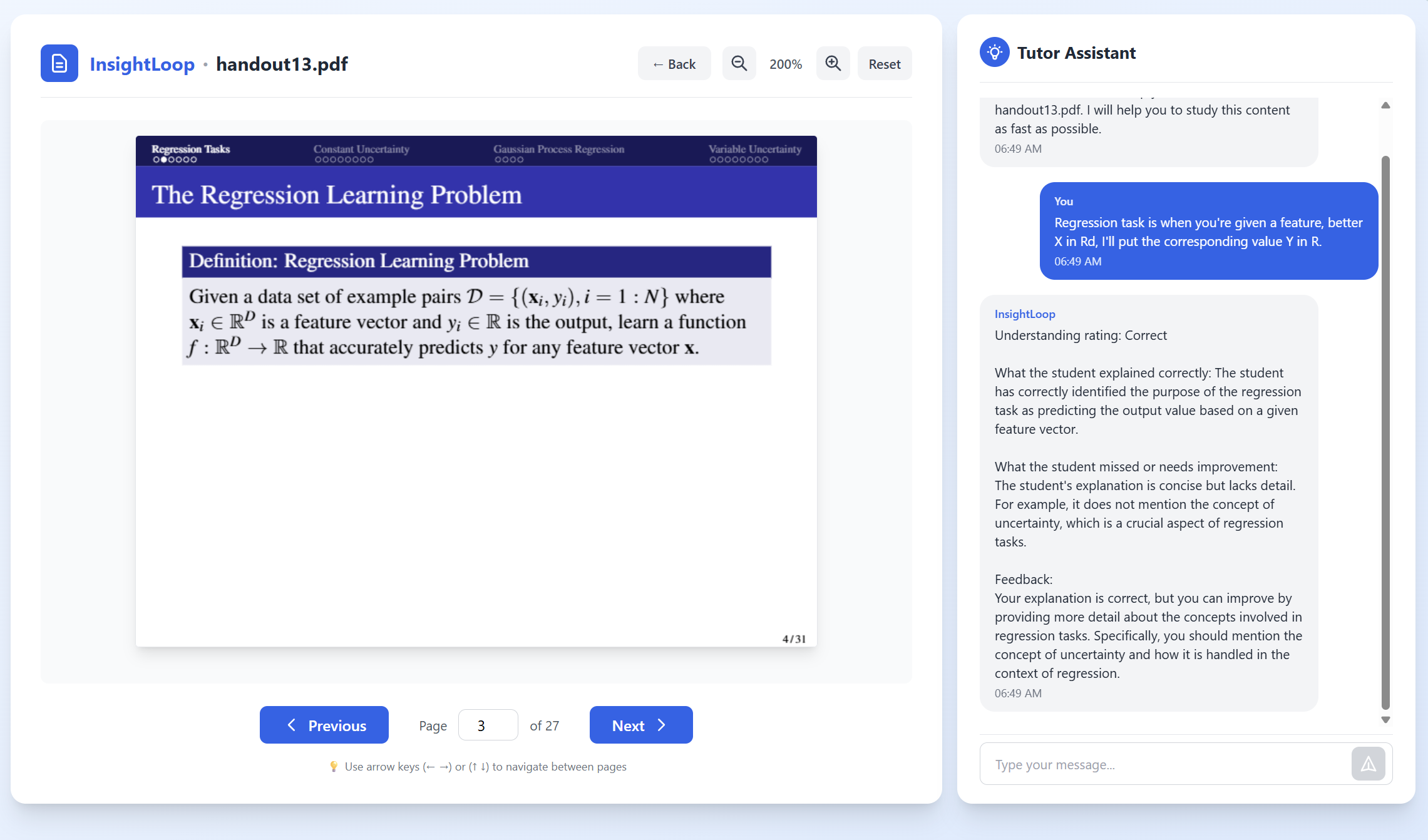
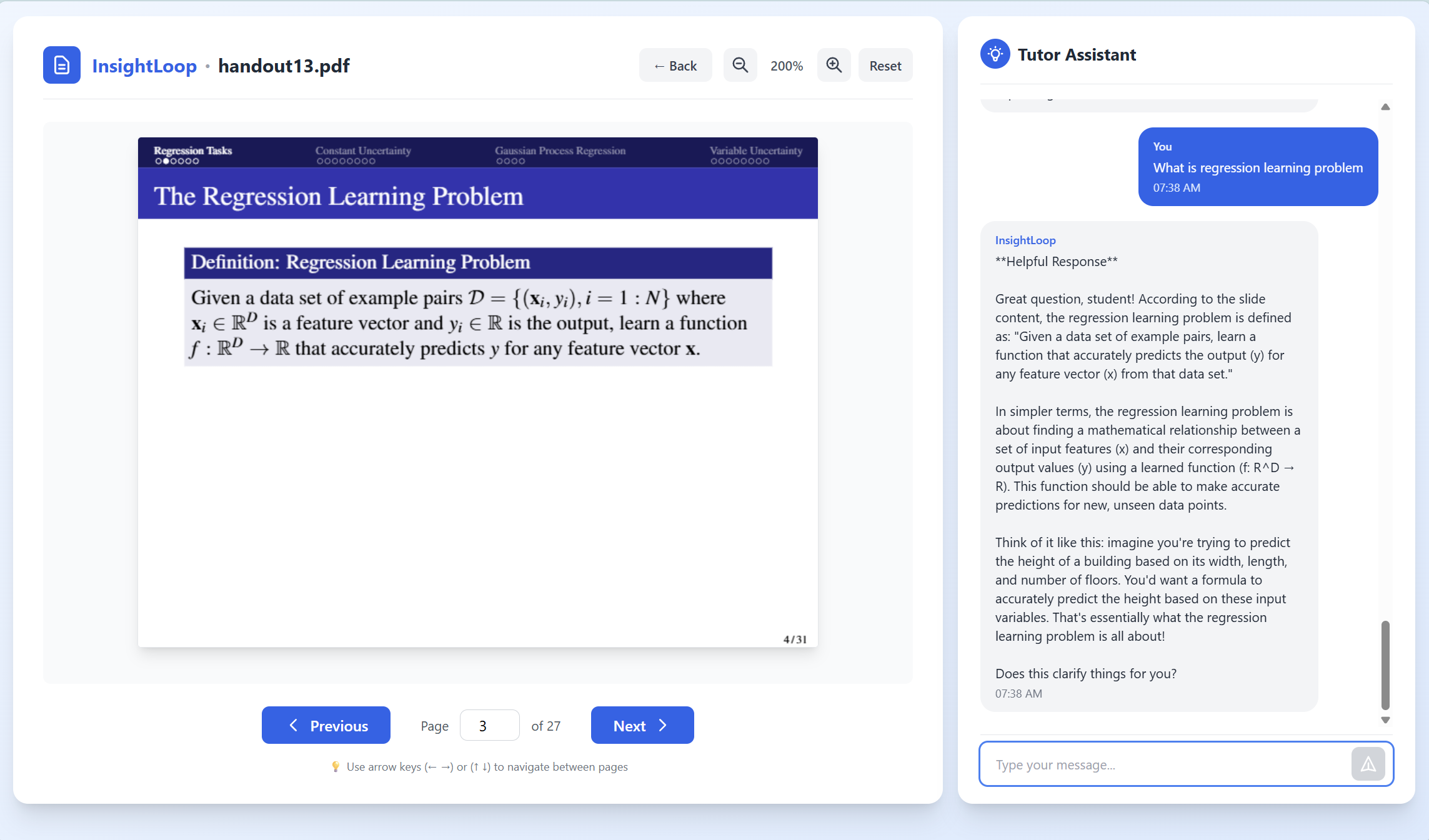
Our system lets students upload their own learning materials and transforms their study session into a live, interactive experience. After the student finishes reading a slide, the tutor briefly blurs the content and asks them to explain the idea in their own words. Using the camera and microphone, the agent captures hesitation, pauses, and vocal stress to measure confidence and understanding. These multimodal signals feed into an on-device AI engine that determines whether the student truly grasps the concept or is drifting into confusion. If uncertainty is detected, the tutor pauses progression and shifts into a conversational mode to analyze the student’s explanation, identifying what went wrong, and delivering a clear correction or walkthrough. If the explanation is accurate and confident, the slide advances smoothly and the lesson continues. All processing happens fully on-device with no cloud dependence, ensuring a private, real-time, and deeply personalized learning experience.
How we built it
We built the entire system fully on-device by combining a lightweight frontend study viewer with a multimodal edge-AI engine running locally on the Snapdragon X Elite. The frontend is implemented in React using PDF.js for rendering slides, with Web Media APIs handling audio capture as the student explains each concept. These short audio recordings are sent to a local Python backend powered by FastAPI, where we process them using WebRTC VAD and librosa to extract hesitation, pause duration, and speech-rate features, which are key indicators of student uncertainty. For understanding the student’s spoken explanation, we run Whisper locally to generate transcripts and timing metadata, enabling us to evaluate not just what the student said, but how they said it. The extracted transcript and acoustic features are then fed into our on-device LLaMA-based reasoning engine, accelerated through Nexa AI on the Qualcomm NPU, allowing the model to quickly assess understanding, identify misconceptions, and craft targeted explanations or corrections. Because every model runs entirely on the device with no cloud calls, the tutoring experience remains real-time, private, and adaptive, giving students instant feedback without ever leaving their machine.
Challenges we ran into
One of the hardest parts was getting all our models to run locally and exposing them cleanly through a backend server. We first tried the Simple Whisper Transcription example from the Qualcomm AI Hub repo and compiled through QNN for NPU execution, but the setup and compile time were too heavy for a hackathon, so we switched to the ai-hub-apps approach that pulls models directly from qai_hub_models.models, which finally gave us a working transcription pipeline on the Snapdragon X Elite. Once Whisper ran, wrapping it in a FastAPI server became the next challenge, especially handling browser-recorded audio, decoding it correctly, and making sure the endpoint responded immediately after each student's answer. On the LLM side, the local-agent repo added latency and complexity, so we moved to a simpler Nexa client that performed faster and integrated cleanly with our tutor flow. We also spent a lot of time tuning our confusion detection, combining silence rate, pitch shifts, and uncertainty in the transcription so it picked up real hesitation without overreacting to normal pauses. Finally, we refined our reasoning prompts so the model could classify explanations, identify missing ideas, and reply in a teaching style that fit our app.
Accomplishments that we're proud of
We’re proud that in just 24 hours, we built a fully on-device, real-time tutoring system that truly showcases the power of Qualcomm’s Snapdragon X Elite. Our biggest technical milestone was getting an end-to-end multimodal pipeline running locally that communicates seamlessly with near-instant feedback and zero reliance on the cloud.
We also pushed what an AI agent can do. Instead of simply answering questions, our agent evaluates student explanations, detects hesitation patterns, scores confidence, identifies misconceptions, and adapts its teaching in real time. This required careful confusion-scoring calibration, prompt engineering, and integrating multiple signals into a consistent reasoning loop while maintaining sub-second latency on-device.
Another major accomplishment is turning complex edge-AI infrastructure into a clean, intuitive product experience. Students can upload their own slides, study naturally, and get targeted feedback exactly when they need it. Despite running Whisper, LLaMA, and a lot of backend services locally, the system remains smooth and responsive thanks to proper NPU utilization and efficient backend orchestration.
We’re especially proud of the security and privacy foundation we built. All models run entirely on the student’s device; no audio, transcripts, or results ever leave the machine. We added guardrails to ensure no data leakage, no network calls, and no hidden telemetry. The local models are fully user-owned, and by design cannot use user data for training, logging, or fine-tuning, ensuring the system meets the highest standards of privacy, data control, and ethical edge-AI deployment.
Together, these accomplishments show not just a functional demo, but a forward-looking application that embodies Qualcomm’s vision for low-latency, privacy-preserving, intelligent Edge AI systems.
What we learned
We learned how challenging and rewarding it is to build a fully on-device AI system from end to end. Working with the Snapdragon X Elite taught us the practical realities of running real models on the NPU, from experimenting with QNN compilation to ultimately relying on Qualcomm’s AI Hub models for smooth Whisper transcription. We gained experience designing a responsive FastAPI pipeline that can ingest raw audio blobs, extract hesitation and timing features, and run low-latency inference without blocking the user. We also learned that confusion detection is nuanced: tuning silence thresholds, analyzing speech rate, and interpreting Whisper’s timing metadata showed us that understanding isn’t just the words you say, but how confidently you say them. Prompt engineering for the LLaMA reasoning engine further taught us how to classify correctness, identify misconceptions, and generate tutor-style responses consistently. Finally, we deepened our appreciation for privacy and security in edge AI, like adding guardrails, preventing any network calls, and ensuring all models remain fully user-owned, reinforcing how powerful and responsible on-device AI can be.
What's next for Insight Loop
Next, we plan to introduce personalized calibration tests so the system can learn each student's unique explanation style and adapt confusion detection to their individual behavior. We also aim to add lightweight CV signals such as blink rate, gaze stability, and attention cues to give students an even more responsive learning experience while staying fully on device. Finally, we will continue extending our tutoring engine with deeper mastery mapping, smarter retrieval from uploaded materials, and further Snapdragon X Elite optimizations to push the limits of real-time edge AI learning.
Example Source: Lecture slides from CS 589, Professor Benjamin M. Marlin, University of Massachusetts Amherst. Disclaimer: Some materials in this presentation are derived from UMass Amherst course slides and are used solely for academic/non-commercial purposes.





Log in or sign up for Devpost to join the conversation.