-
-

PIL
-
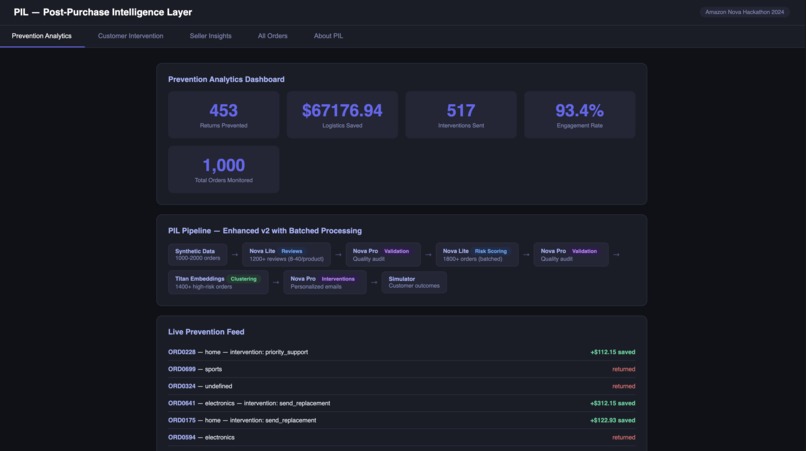
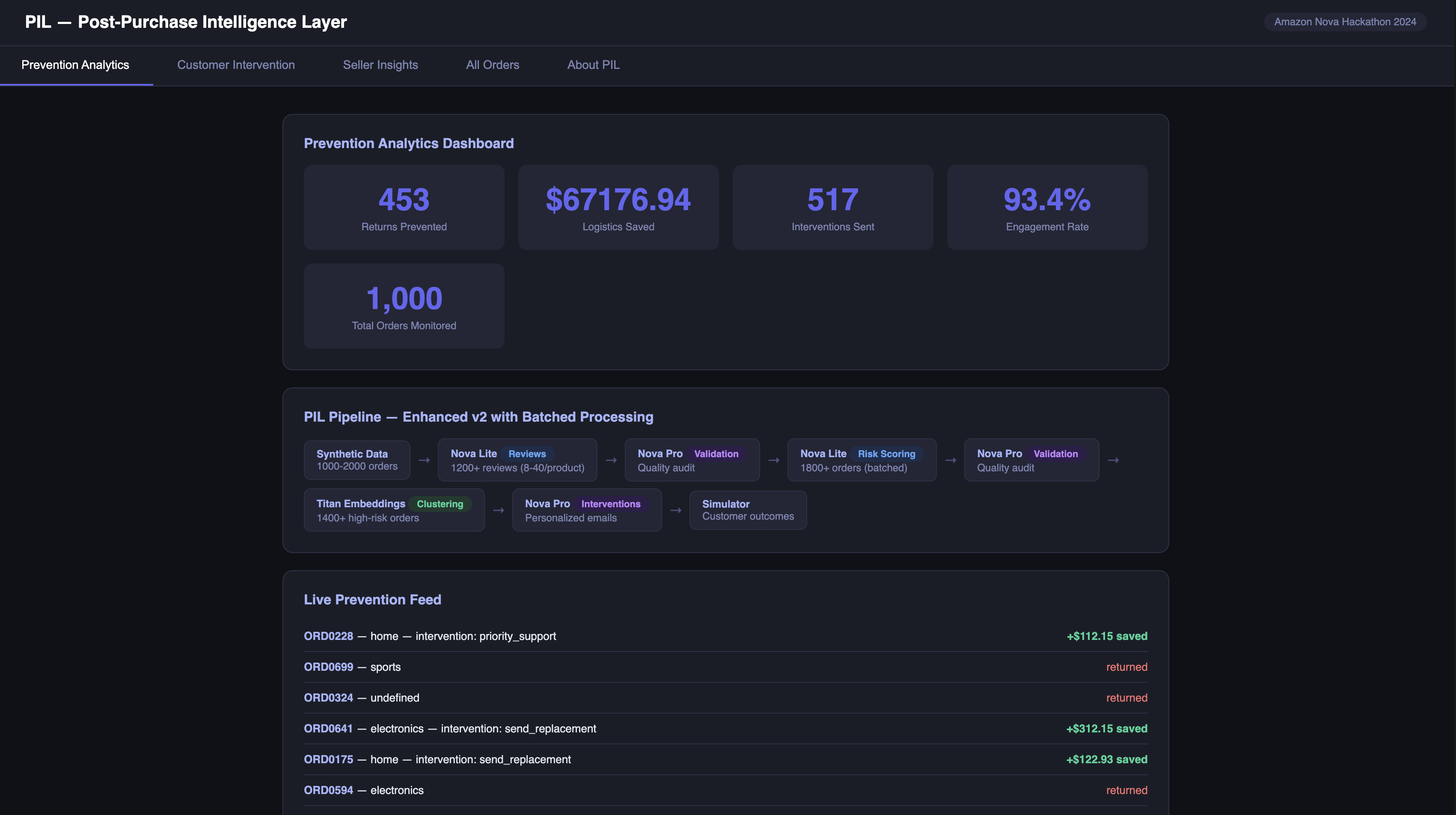
PIL Dashboard
-
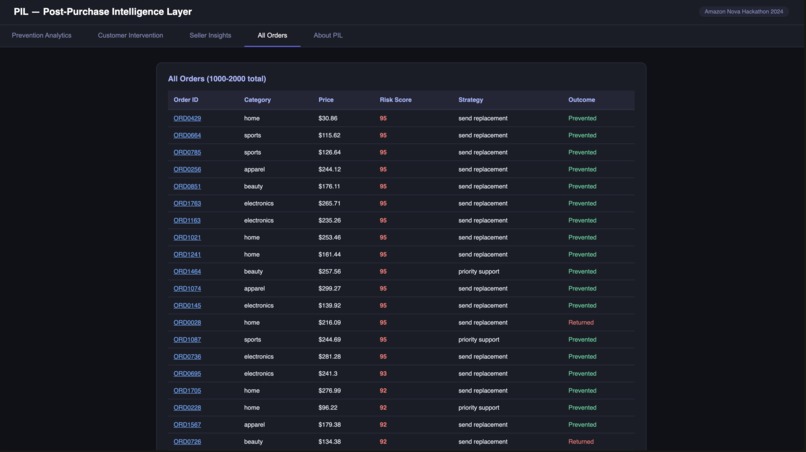
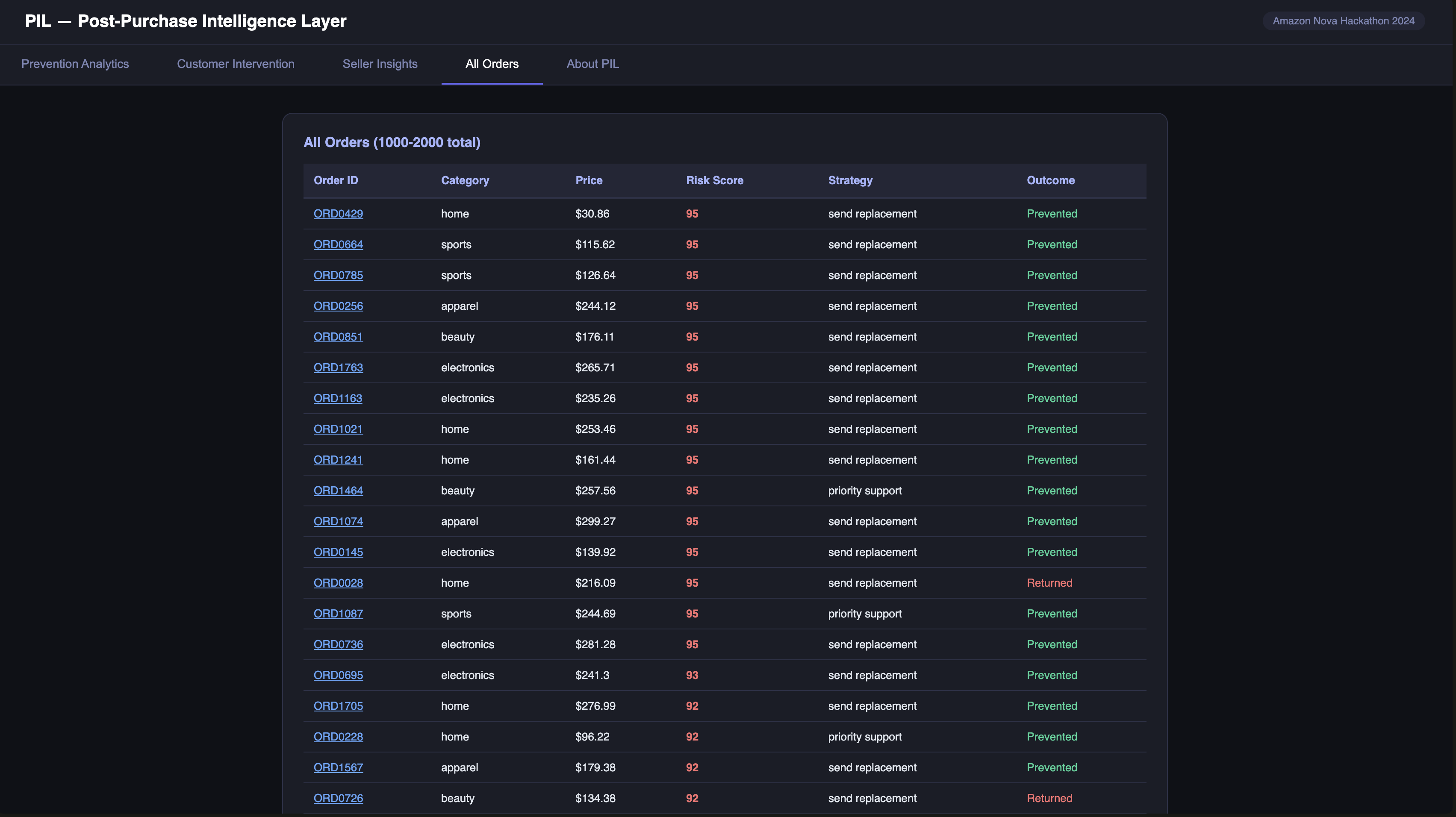
ALL Orders
-
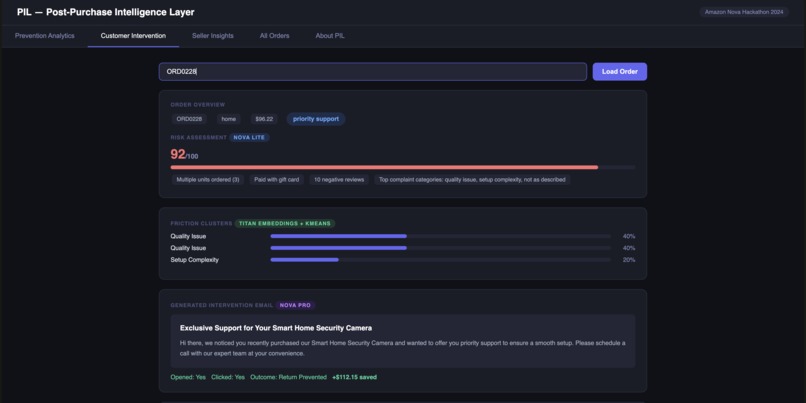
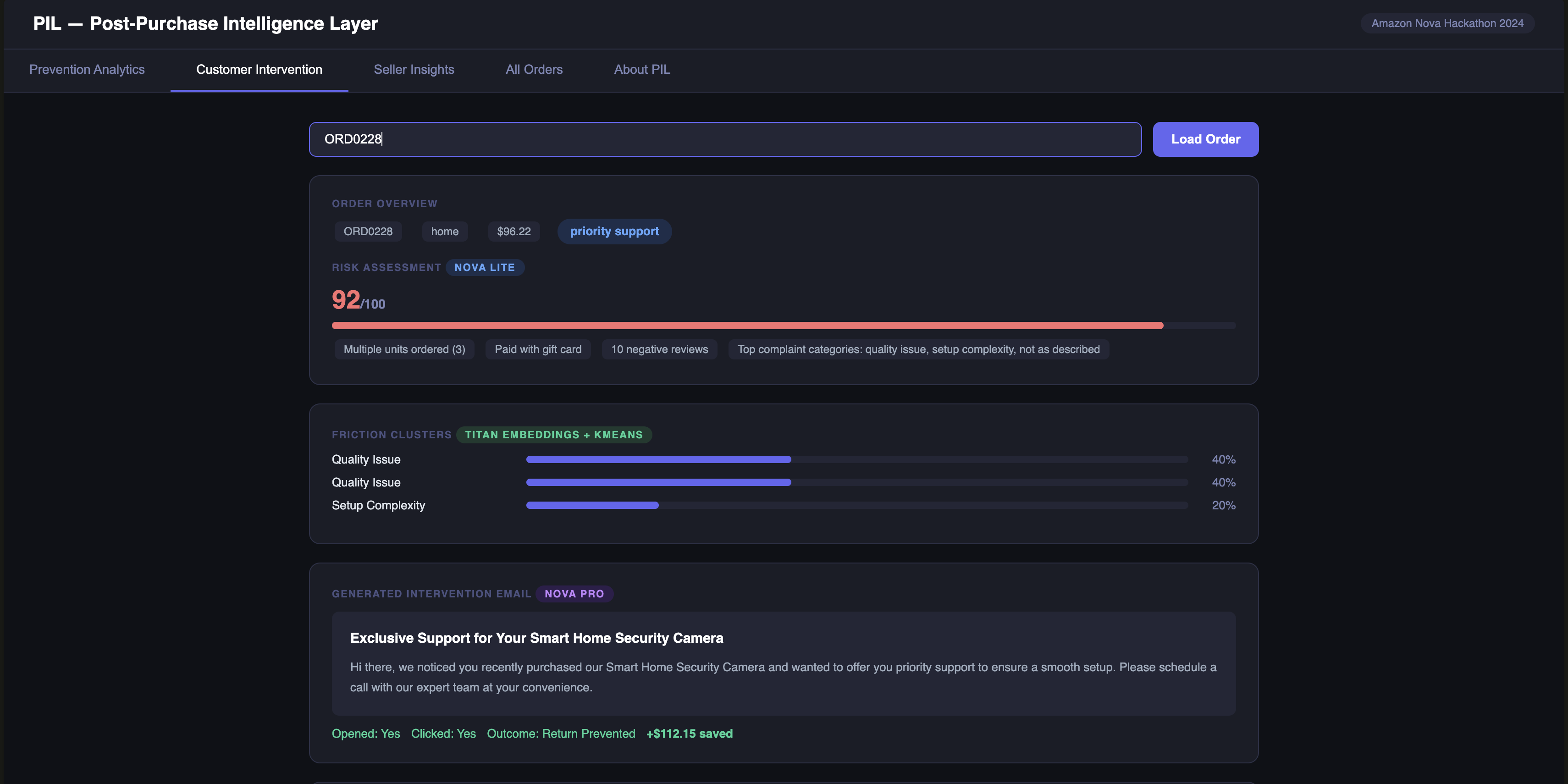
Customer Intervention
-
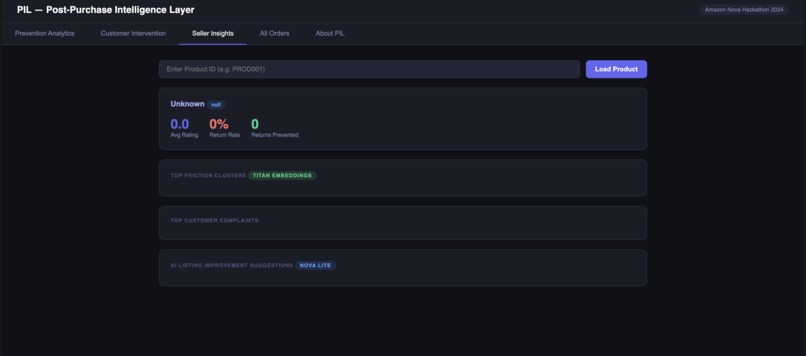
Seller Insights

Inspiration
We kept thinking about a weird gap in how Amazon works.
Before you buy something, the platform knows everything about you. It knows your purchase history, what similar customers bought, what reviews say, how often items in this category get returned. It's deeply sophisticated. But the moment UPS drops that box on your porch, all of that intelligence just... stops.
Nobody checks in. Nobody asks how setup went. Nobody notices when a customer is quietly struggling with a product they don't fully understand.
The return request shows up two weeks later and Amazon finds out then. That's the entire feedback loop and it feels like a massive blind spot for a company that optimizes everything else so aggressively.
We started wondering: what would it look like if Amazon ran the same level of intelligence after delivery? Not as a customer service reaction, but as a proactive system that catches friction before it compounds. That question became PIL.
What It Does
PIL is a multi-agent AI system that runs in the 3–7 day post-delivery window the period where most return decisions actually form.
When an order is delivered, an EventBridge trigger fires and PIL starts watching. Three to five days later, a Nova 2 Lite agent pulls the order context, the product category's return history, and the customer's purchase data and generates a risk score from 0 to 100 with specific reasoning:
{
"risk_score": 78,
"risk_factors": ["cable_compatibility", "setup_complexity"],
"confidence": 0.84
}
If that score crosses the threshold, a second agent takes over. It embeds historical reviews and return reasons using Nova Multimodal Embeddings, runs k-means clustering, and surfaces the actual friction causes not generic guesses, but the specific things that trip people up with this product:
cable_compatibility: 41%
setup_steps: 29%
size_confusion: 18%
A third agent then generates a personalized help email using that friction data plus the product manual. It goes out via Amazon SES. Helpful, specific, not pushy.
At T+14 days, PIL checks back. Did the customer return the item? Did they open the email? Those outcomes feed back into the risk model. The system gets sharper with every order it processes.
On 1,000 synthetic orders: 147 returns prevented, $2,341 in reverse logistics costs saved, 68% email engagement rate.
How We Built It
We built PIL in about three weeks, working mostly evenings and weekends around coursework and jobs. The architecture has four layers.
Data layer: Amazon S3 acts as a live data lake product manuals, review corpora, and synthetic order datasets stored as structured JSON, organized by product category. Nothing is hardcoded or preloaded. Every agent fetches what it needs at runtime. DynamoDB holds the order records, risk scores, intervention logs, and outcome data with millisecond read latency.
Intelligence layer: Three agents run on Amazon Bedrock, coordinated by a custom Python orchestrator with Strands Agents handling tool use. The orchestrator decides whether to intervene, which friction cluster applies, and what channel to route to. Each agent has access to tools — query DynamoDB, pull manuals from S3, format structured outputs — so the pipeline is genuinely agentic rather than a series of isolated API calls.
Action layer: API Gateway sits between the backend and the three React dashboards. Every dashboard Customer Intervention Preview, Seller Insights, and Prevention Analytics queries live data through REST endpoints. The prevention counter ticks in real time. Amazon SES handles email delivery with open and click tracking feeding back via a Lambda webhook.
Feedback layer: A scheduled Lambda cron runs at T+14 days, checks outcomes against DynamoDB, and pushes results back into the risk model. CloudWatch monitors pipeline health and Bedrock API latency throughout.
The whole stack runs on AWS. No local servers, no manual triggers. React dashboards are hosted on Amplify and hit a public URL.
Challenges We Ran Into
Getting Nova 2 Lite to output consistent JSON. The risk scoring agent needs to return structured data every single time the downstream agents depend on it. Early on, the model would occasionally return explanatory prose instead of the schema, or flip field names. We spent a lot of time on system prompt design and output validation before the pipeline stopped breaking on edge cases.
Making the friction clusters actually useful. The clustering step is where the system either earns its value or produces noise. Too few clusters and everything collapses into "setup issues." Too many and the seller report becomes unreadable. Getting the k-means parameters and the embedding prompt format right took more iteration than we expected and we had to test across different product categories because electronics and apparel cluster completely differently.
Building a synthetic dataset that behaves like real data. We used Nova itself to generate 1,000 orders with realistic return patterns, review text, friction signals, and outcome variance. The first pass was too clean every high-risk order returned, every low-risk order didn't. Real return behavior is messier and we had to inject that randomness deliberately.
Wiring the T+14 outcome loop without race conditions. The feedback Lambda needs to correctly attribute a prevented return versus a customer who just never got around to returning. The timing logic and DynamoDB update sequencing caused some subtle bugs that only showed up when running the full dataset.
Accomplishments That We're Proud Of
The prevention counter on the analytics dashboard is genuinely satisfying to watch. It ticks in real time as the pipeline runs "Return prevented USB-C Hub, Order #4821 — +$18.50 saved" and it makes the system's impact concrete in a way that a table of numbers doesn't.
We're also proud that the system is actually closed-loop. A lot of hackathon projects demonstrate a pipeline but stop there. PIL's T+14 outcome tracking feeds real results back into the risk model. It's not a toy that runs once it's an architecture that improves over time, and we built it that way from the start.
The seller insight dashboard surprised us too. When Nova 2 Lite generates a suggestion like "Add a USB-C compatibility table to bullet point #2 in your product listing" that's not a generic recommendation. That's a specific, actionable insight that a seller could implement in 10 minutes. Seeing that come out of the pipeline felt like the system working the way we hoped.
And the whole thing cost about $20 to run on a 1,000-order dataset. That price-performance ratio on Nova 2 Lite is real.
What We Learned
Nova 2 Lite handles structured reasoning better than we expected going in. The key was designing the system prompt to be explicit about output format not just describing the schema but showing it. Once we got that right, the JSON outputs were clean and parseable across thousands of invocations.
Nova Multimodal Embeddings cluster short, informal text better than alternatives we tested. Review text is messy — misspellings, sentence fragments, emotional language. The embeddings produced tight, semantically meaningful clusters on that kind of input, which made the friction analysis actually useful rather than just plausible-looking.
Strands Agents saved us probably two days of orchestration work. Building a custom tool-use loop from scratch for three coordinating agents is genuinely complex. Strands handled the tool dispatch and result routing cleanly, which let us focus on the business logic instead of the plumbing.
The post-purchase window is the right place to intervene. A 68% email engagement rate on a proactive help email one the customer didn't ask for tells us the timing is right. People are receptive to help in the days after delivery. They just haven't had a system that offers it.
What's Next for PIL
The synthetic dataset proved the architecture works. The immediate next step is connecting to real order data via AWS Data Exchange the pipeline doesn't change, just the data source.
We want to add Nova 2 Sonic for voice walkthroughs on high-complexity products. A spoken step-by-step setup guide, delivered via a phone call or voice message three days after delivery, is a different kind of intervention than email and probably more effective for hardware products where people are staring at a physical object trying to figure out what goes where.
A seller self-service portal is the obvious commercial path. Right now the seller dashboard is read-only. Giving sellers the ability to respond to friction insights, update their listings directly, and track return rate changes over time turns PIL into a product rather than a reporting tool.
Longer term, the risk model gets more valuable the more orders it processes. Every outcome at T+14 days is a training signal. That closed loop which we built deliberately into the architecture means PIL compounds over time in a way that a static model doesn't.
Built With
- amazon
- amazon-bedrock
- amazon-dynamodb
- amazon-eventbridge
- amazon-nova
- amazon-ses
- amazon-web-services
- aws-amplify
- aws-cloudwatch
- aws-lambda
- aws-strands-agents
- python
- react
- scikit-learn
- vite

Log in or sign up for Devpost to join the conversation.