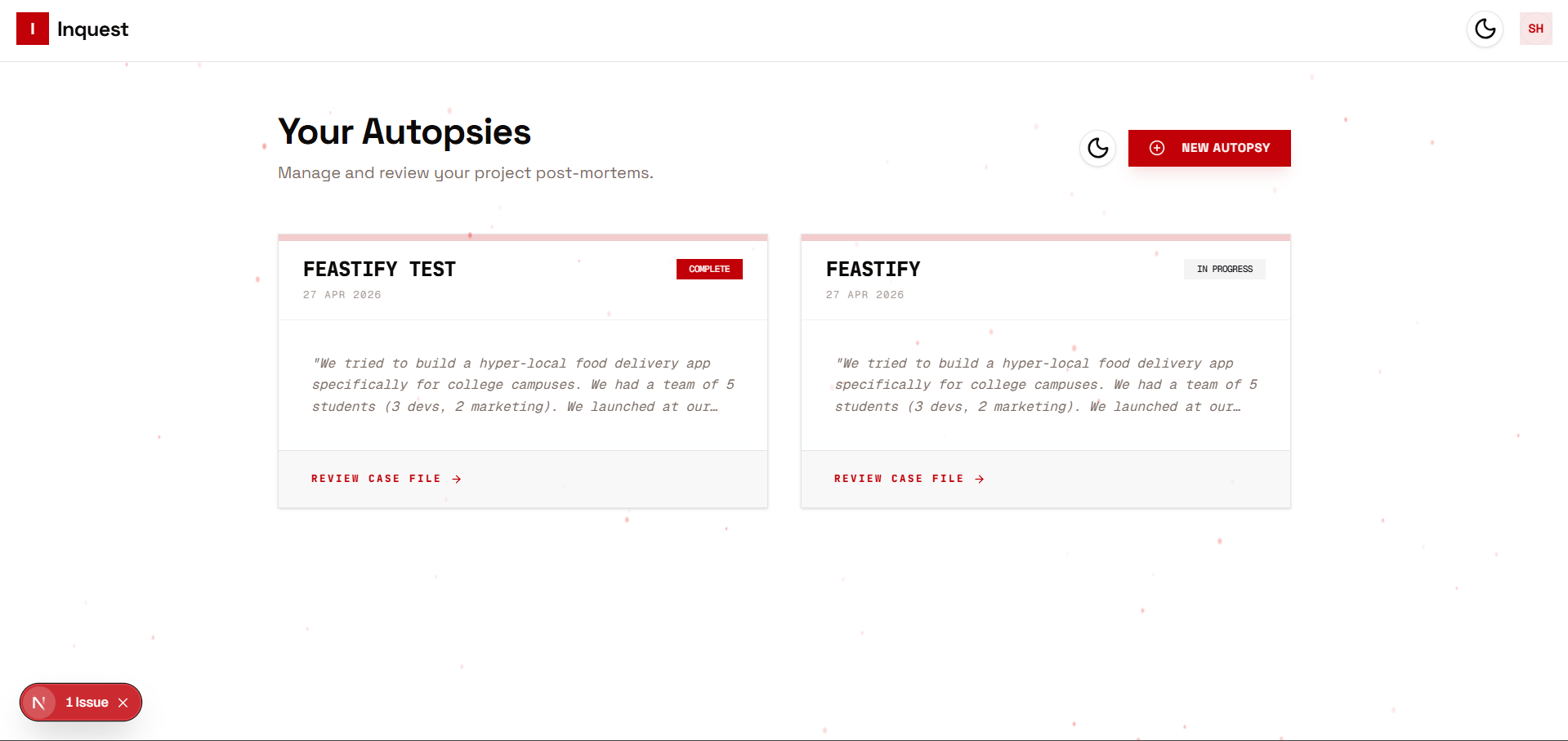
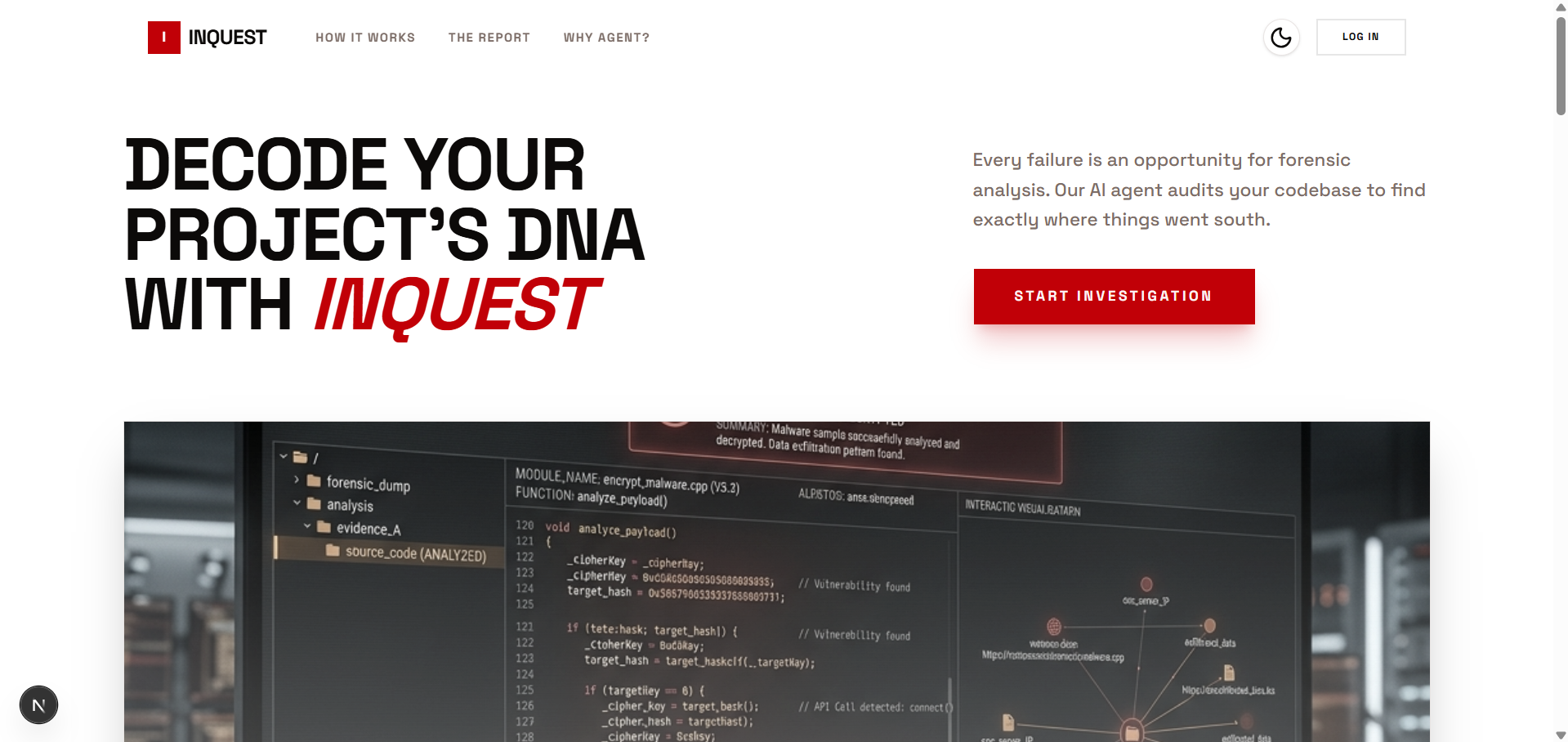
What Inspired Inquest
Every developer has a graveyard. A folder of repos that almost worked. The problem isn't that projects fail — it's that we never really understand why. We say "scope creep" or "ran out of time" because it's easier than the honest answer.
I wanted to build something that would not let you off the hook. Not a form. Not a template. An investigator.
How I Built It
Inquest is a full-stack agentic application built on Next.js 15 App Router with two core systems working together:
1. Autonomous Repo Ingestion
When a user submits a GitHub URL, the /api/ingest-repo route autonomously:
- Fetches the entire file tree via GitHub's Git Trees API (
?recursive=1) - Filters files by type and size (only source files under 100KB)
- Batch-fetches file contents with rate-limit-safe 200ms delays
- Decodes base64 content and prepends each file with
### FILE: {path}for citation - Estimates token count using
chars / 4and truncates at 700k tokens
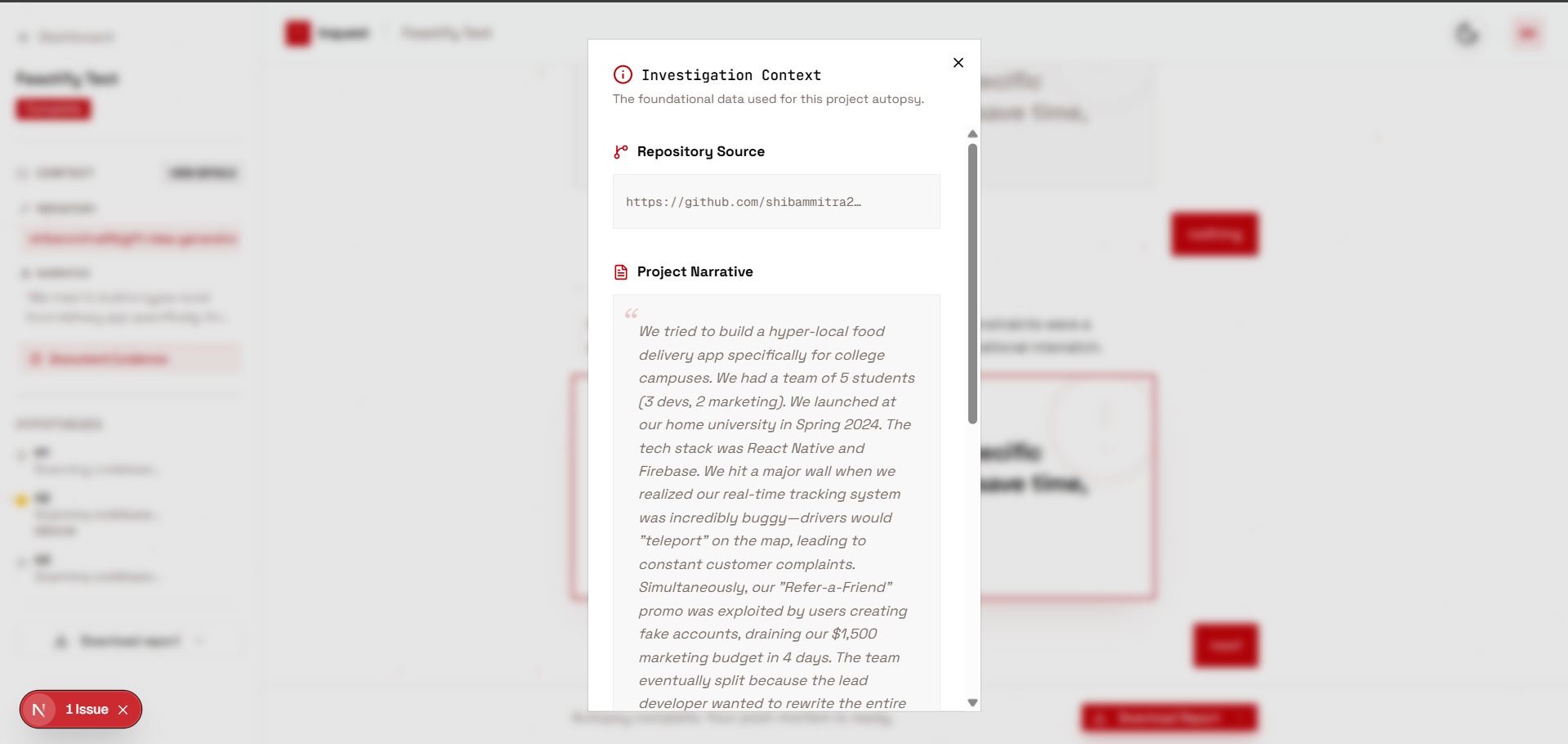
This gives the agent a complete picture of the codebase before asking a single question — made possible by Gemini 1.5 Pro's 1M token context window, which eliminates the need for chunking, RAG pipelines, or vector search entirely.
2. The ReAct Agent Loop
The agent follows the Reason → Act → Observe → Repeat pattern, implemented manually without any agent framework:
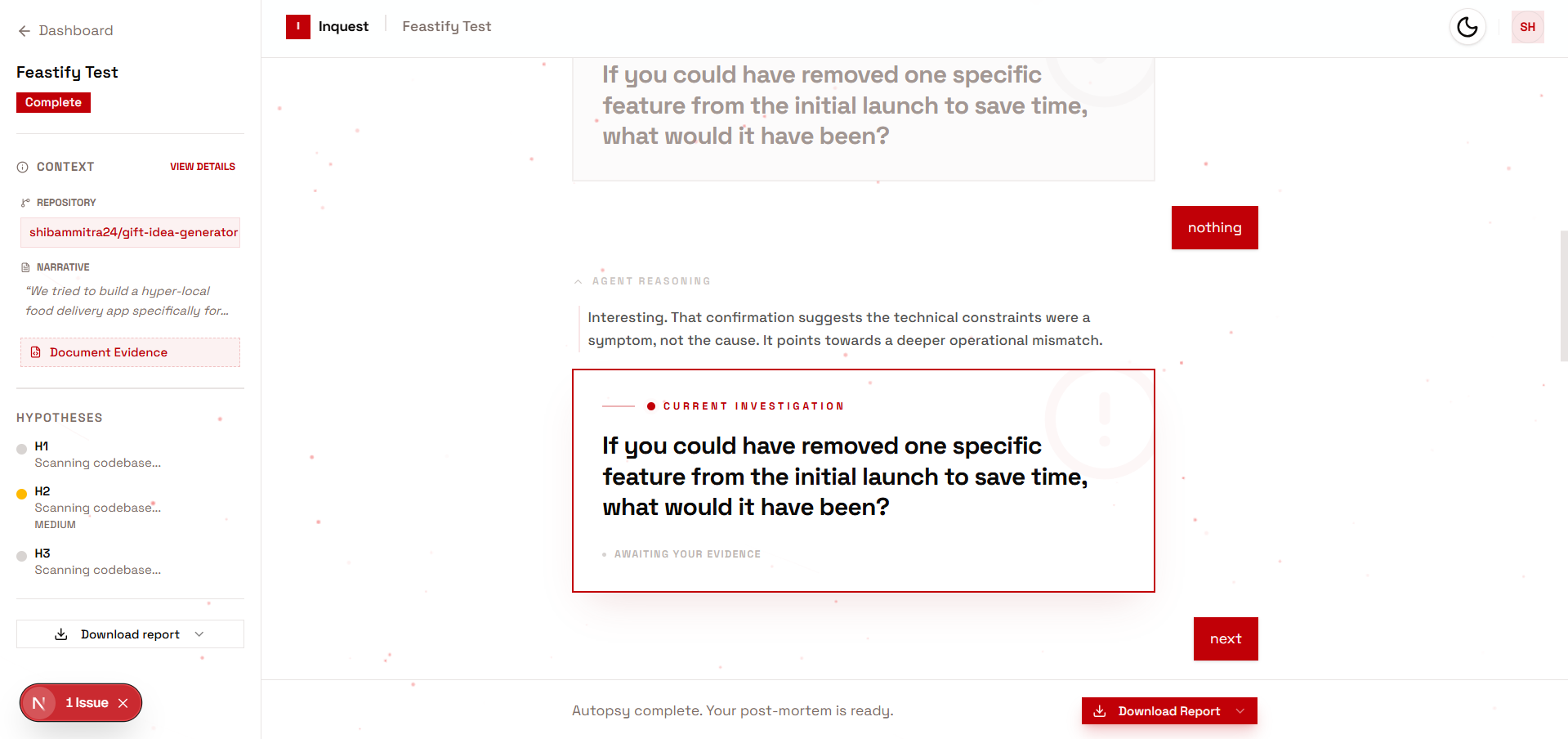
Phase 1 — Hypothesis Formation After reading the full repo + project story, the agent forms exactly 3 failure hypotheses, cites specific filenames as evidence, rates each LOW / MEDIUM / HIGH confidence, then asks one targeted question.
Phase 2 — Interview (4–5 turns) After each answer, the agent updates its confidence ratings and asks the next most important question — each question decided by what was learned from the previous answer, not a pre-written script.
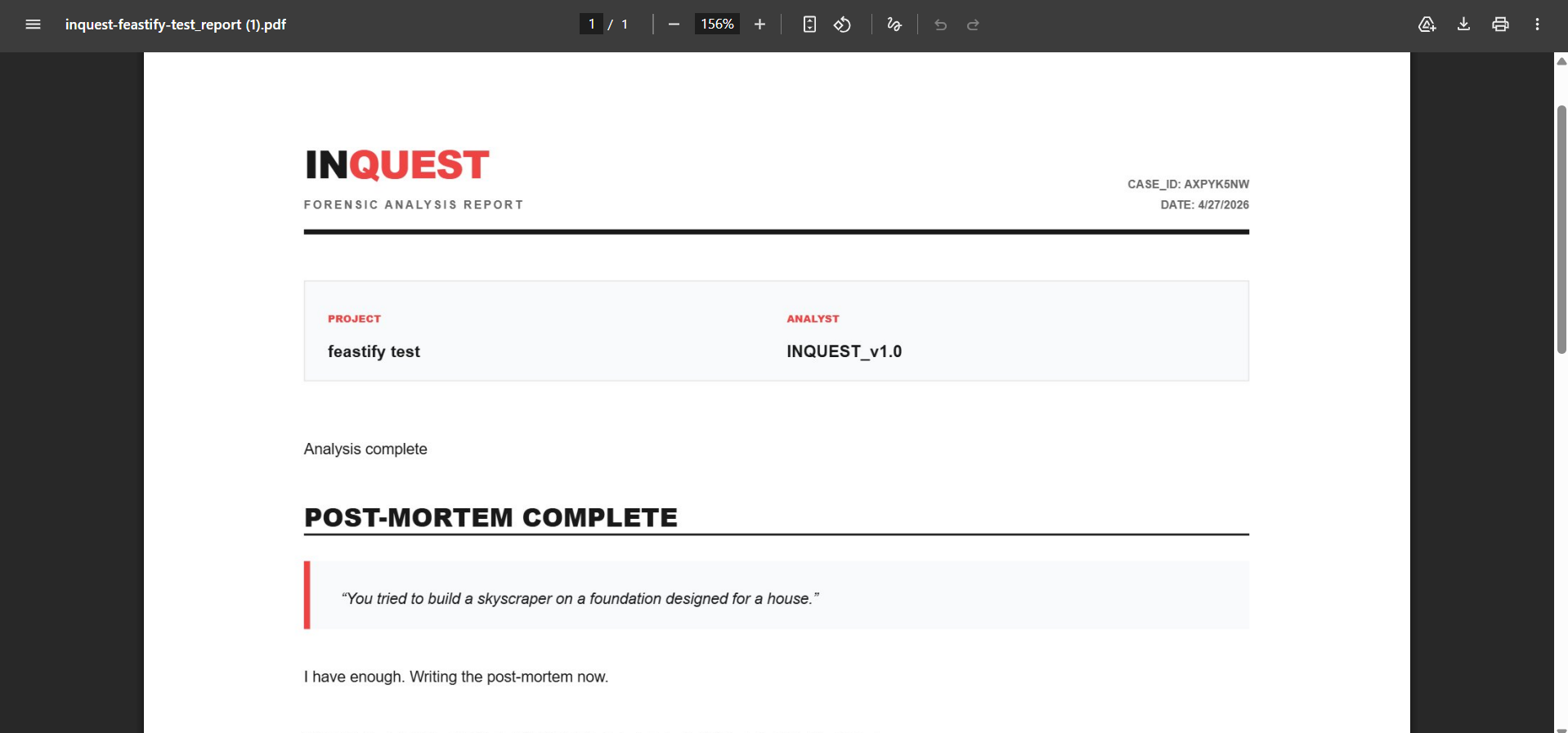
Phase 3 — Self-Termination The agent decides when it has enough evidence. It says: "I have enough. Writing the post-mortem now." The user never triggers report generation. The agent does.
3. Persistent Memory via Supabase
Every message is stored in Supabase with role (user | assistant). On each API call,
the full message history is reconstructed and sent to Gemini — making sessions fully
resumable across devices and browser sessions. Row Level Security ensures users can
only access their own data, enforced at the database level.
The Post-Mortem Report
The final report has five structured sections:
- What actually killed this project — the real root cause
- The chain of events — the narrative of how it unfolded
- What survived — what was genuinely good (blameless post-mortem culture)
- What to carry forward — actionable lessons
- One honest sentence — a single sentence capturing what the project was really about, underneath all the technical reasons
The fifth section is the emotional core of the product.
What I Learned
- How to implement the ReAct pattern from scratch — without LangChain, CrewAI, or any agent abstraction layer. Every reasoning step is explicit and inspectable.
- How a large context window changes architecture: Gemini 1.5 Pro's 1M token window let me treat the entire repo as a single document rather than a retrieval problem.
- How to design agent UIs that make internal state visible — the live confidence tracker shows the agent's belief state updating in real time, which most agent products hide entirely.
- That temperature is a design decision: 0.4 for the interview phase (adaptive, non-generic questions), 0.3 for the report phase (structured, consistent output).
Challenges
The hardest challenge was the self-termination condition. Getting the agent to reliably decide when it knows enough — not too early (shallow report), not too late (redundant questions) — required careful prompt engineering across the phased system prompt. The exact trigger phrase "I have enough. Writing the post-mortem now." is both a model instruction and a string the frontend watches for to flip session state.
The second hardest was citation grounding.
Early versions produced hypotheses like "the architecture seems problematic."
Getting the agent to cite specific filenames as evidence — "the absence of any
test files under src/__tests__/ and the 47 TODO comments in lib/api.ts
suggest..." — required structuring the ingested context with ### FILE: {path}
headers and explicitly instructing the model to cite before concluding.
Token budget management across repos of wildly different sizes required the truncation logic to be conservative enough to always leave headroom for the conversation history and the model's response within the 1M context window.
Built With
- api
- css
- framer
- github
- motion
- next.js
- postgresql
- react-markdown
- remark-gfm
- rest
- shadcn/ui
- supabase
- tailwind
- typescript

Log in or sign up for Devpost to join the conversation.