-
-
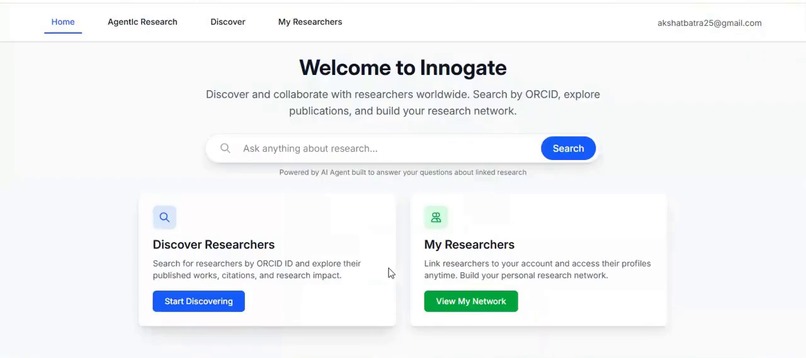
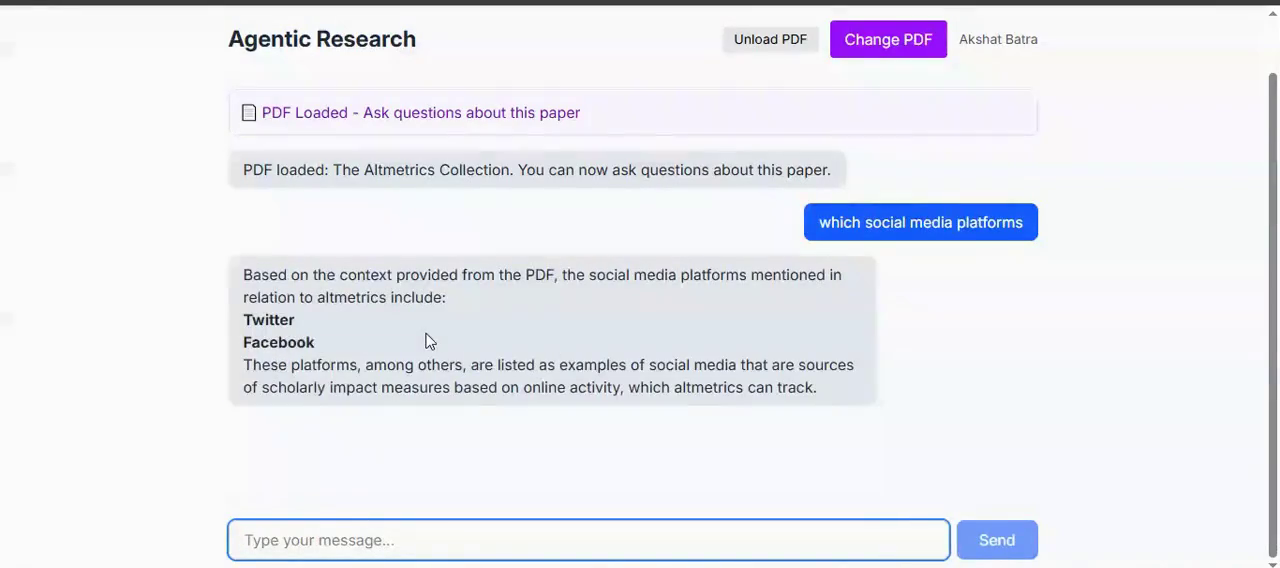
Home Page
-
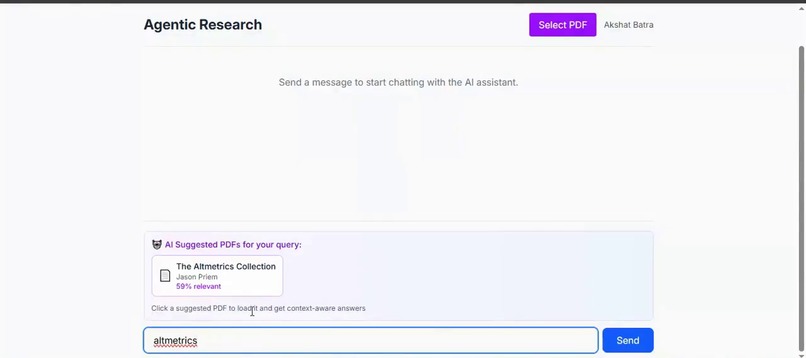
Agentic Suggestion
-
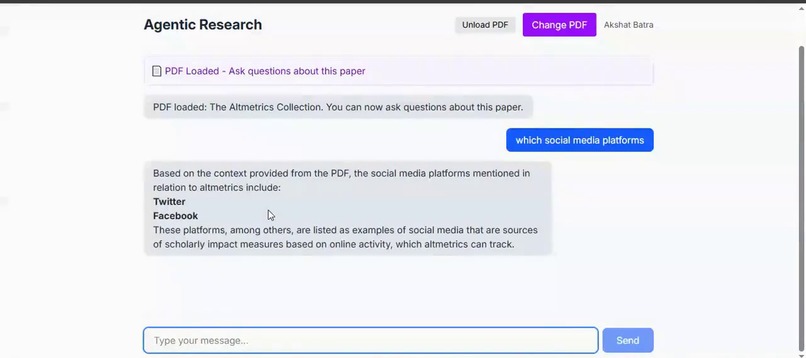
Agentic Synthesis
-
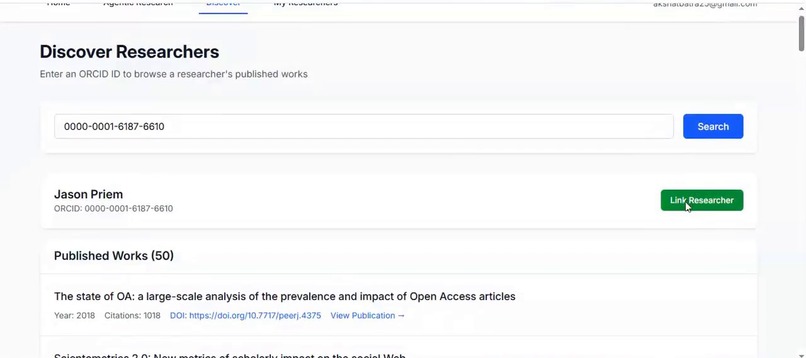
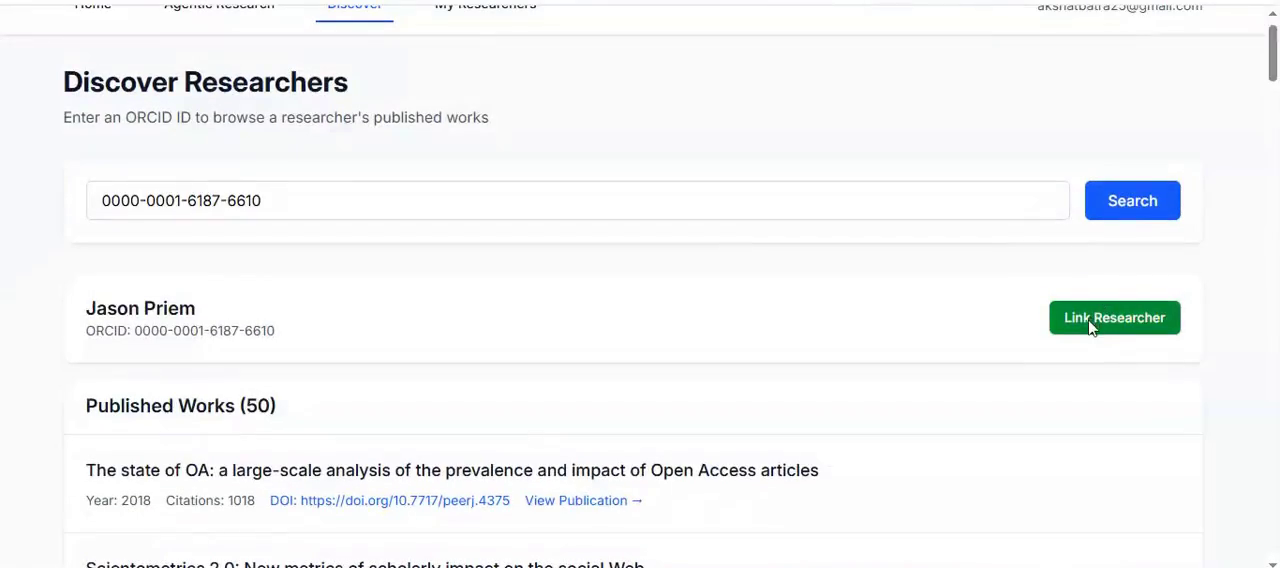
Discover Researchers
-
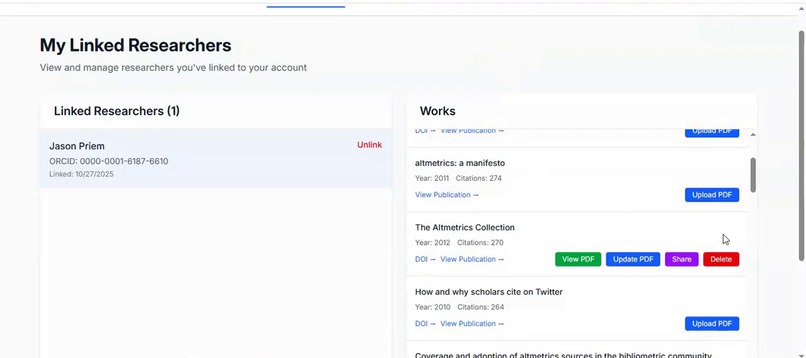
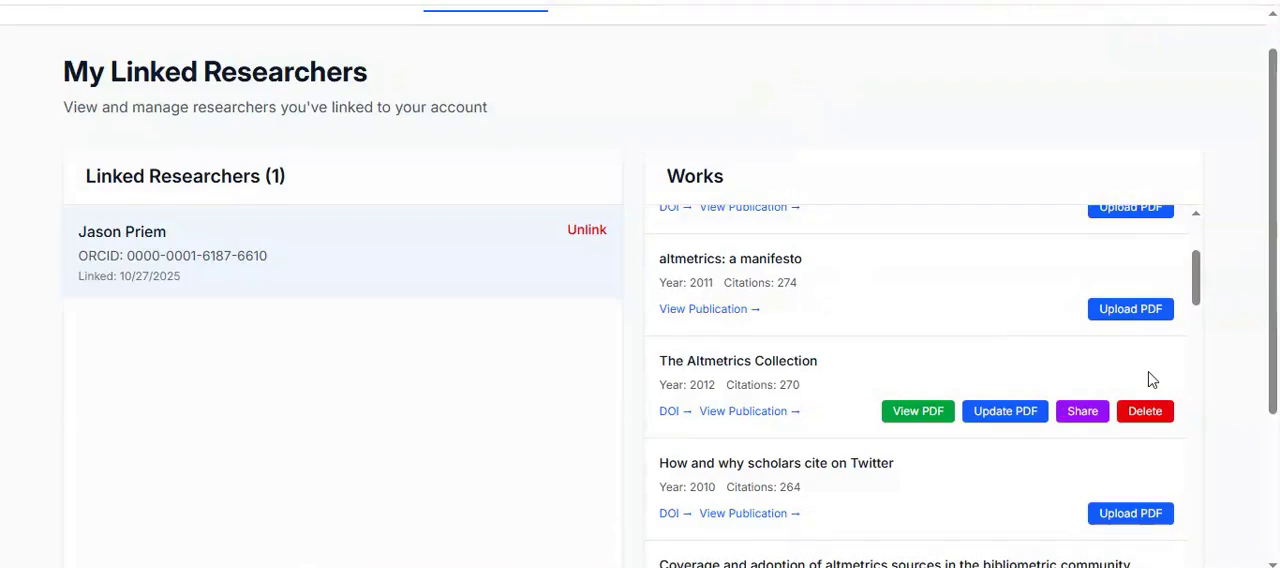
My Researchers
-
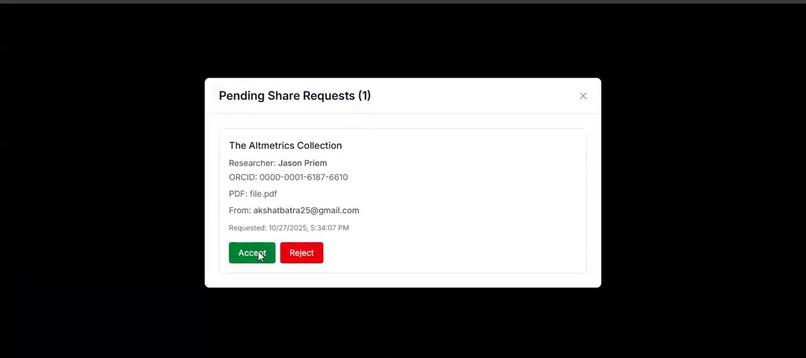
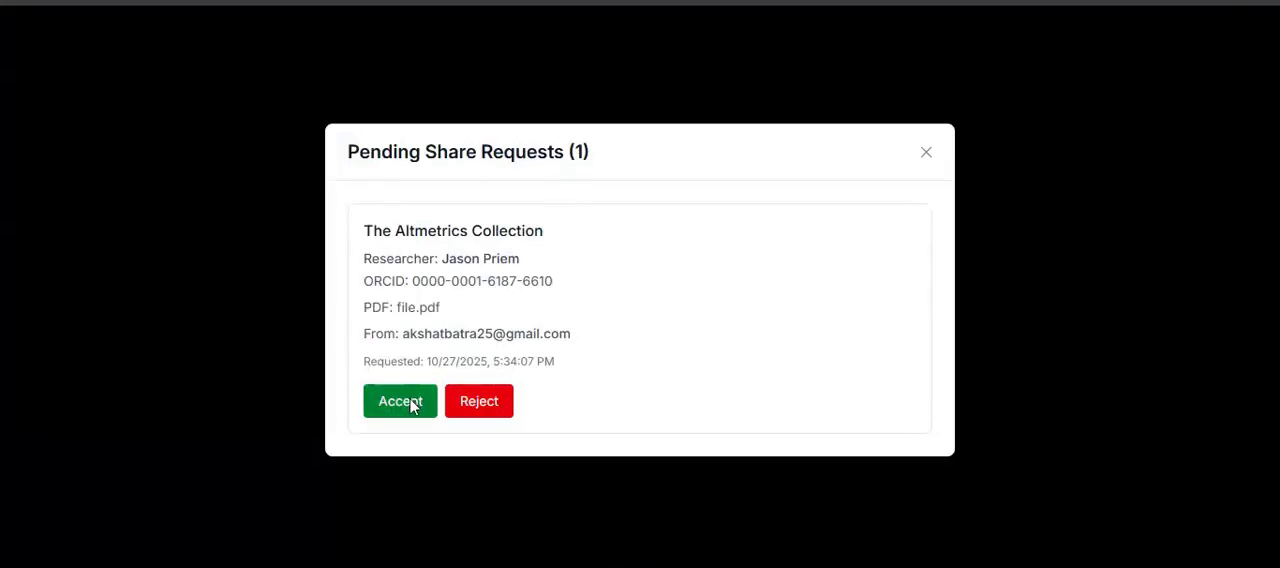
Research Paper Sharing Request
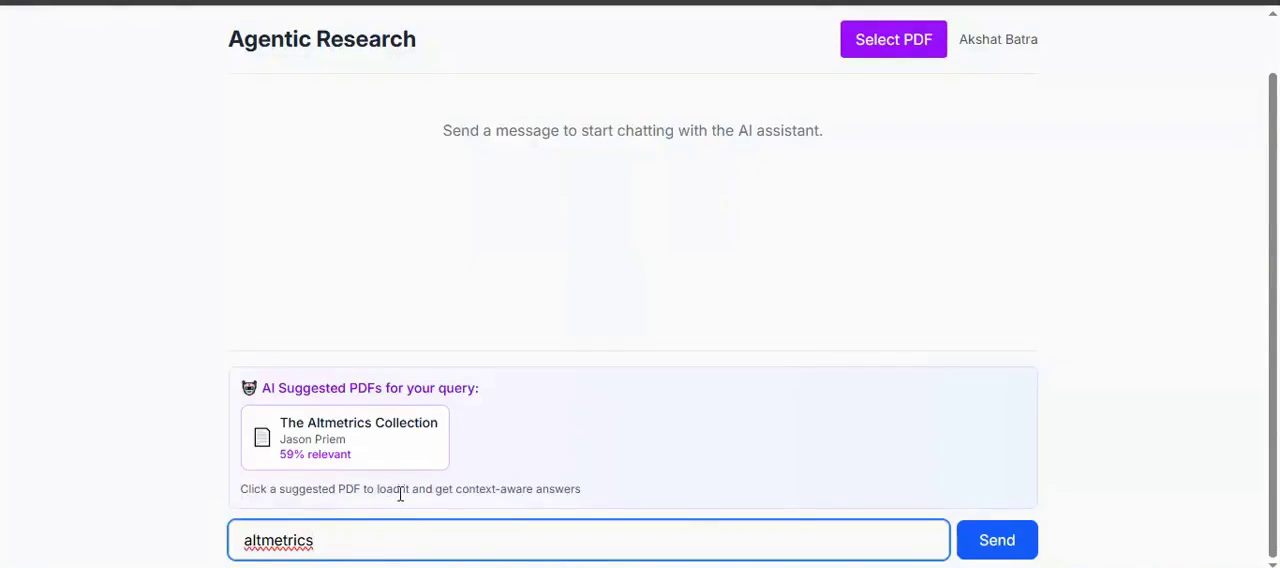
Inspiration
We built Innogate because reading, synthesizing, and cross-referencing large numbers of research papers is slow and error-prone. Modern LLMs, vector search, and agentic orchestration make it possible to automate much of that manual work: ingest PDFs, create semantic embeddings, retrieve the most relevant passages, and let a reasoning model produce concise, context-aware answers. We were inspired to combine agentic workflows (LangChain-style tool orchestration) with production-grade model hosting (NVIDIA NIM on AWS SageMaker) so researchers could run a scalable, secure RAG assistant for literature review and discovery.
What it does
- Ingests and stores PDFs with metadata and share controls.
- Processes PDFs into textual chunks and computes embeddings using NVIDIA NeMo Retriever (deployed as a SageMaker endpoint).
- Stores vectors in a memory-backed vector store (pluggable for persistence).
- Performs semantic search (similarity ranking) to retrieve context for queries.
- Uses NVIDIA Nemotron LLM (Nemotron on SageMaker) orchestrated by LangChain to answer questions, summarize, and produce recommendations based on retrieved context.
- Streams token-by-token responses to the frontend via Server-Sent Events (SSE) for a responsive chat experience.
- Protects endpoints and user flows via Auth0 authentication and optional OpenFGA authorization.
How we built it
Stack and architecture
- Frontend: React + Vite, Auth0 for SPA authentication. The chat UI sends queries and displays streamed tokens from the backend.
- Backend: Fastify + TypeScript. Responsibilities:
- File upload & PDF parsing (pdfjs-dist / pdf-parse).
- Embeddings and LLM inference via SageMaker endpoints (AWS SDK + LangChain integration).
- In-memory LangChain vector store for fast retrieval (can be swapped for Qdrant/Pinecone).
- SSE streaming endpoint that forwards tokens as they arrive.
- Database: PostgreSQL with Drizzle ORM for metadata, uploads, and share requests.
- Models: NVIDIA NIM (NeMo Retriever for embeddings; Nemotron for generation) deployed to AWS SageMaker.
Key implementation notes
- LangChain wrappers: custom factories to call SageMaker endpoints for embeddings and LLM inference, so the rest of the pipeline remains model-agnostic.
- RAG flow: query → embed → similaritySearch(top-k) → assemble context → call LLM with context → stream tokens to UI.
- Auth: Auth0 SPA + backend JWT verification plugin; protected endpoints require
Authorization: Bearer <token>. - Dev ergonomics: documented
.envfiles and included tips (e.g.,--legacy-peer-depsfor npm when needed).
Small runnable flow (developer view)
- Upload a PDF (multipart POST).
- Server parses, chunks, and sends batches to the NeMo Retriever endpoint to obtain embeddings.
- Vectors saved in memory with tags linking to PDF & chunk offsets.
- User queries via frontend; backend performs similarity search and calls Nemotron to generate an answer using the retrieved context.
- Tokens stream back over SSE and are displayed live.
Challenges we ran into
SageMaker deployment variance — Different model sizes and instance types caused configuration and cost surprises during testing. We mitigated this by recommending small dev instance types (e.g.,
ml.g5.xlarge/ml.g5.2xlarge) and clear env-driven endpoint names.Latency vs. cost tradeoff — Real-time inference can be expensive. We chose smaller Nemotron variants for interactive use, batched embeddings requests, and added caching for repeated queries.
Reliable streaming — Buffering and message chunking required designing a clean SSE protocol (token events, heartbeat, done/error events) to avoid UI stalls.
PDF variability — PDFs with multi-column layouts, scanned images, or inconsistent structure required robust pre-processing and adaptive chunking heuristics.
Auth0 local dev friction — Callback/origin misconfiguration led to failed logins; we added explicit Auth0 setup steps (Allowed Callback URLs, Refresh Token Rotation) and a dev notes section for unauthenticated testing.
Dependency & peer-dep issues — Some ecosystem packages required
--legacy-peer-depsor pinned versions; we documented these workarounds.
Accomplishments that we're proud of
- End-to-end RAG pipeline using NVIDIA NIM models served on SageMaker, integrated with LangChain.
- Responsive streaming chat UI that displays token-by-token model outputs using SSE.
- Robust PDF ingestion pipeline with chunking, embedding, and provenance-aware context assembly.
- Clean separation of concerns so models are pluggable (swap SageMaker-backed models for other providers with minimal changes).
- Production-minded design: Auth0 for authentication, Drizzle/Postgres for metadata, and clear environment-driven deployment steps.
What we learned
Practical RAG engineering essentials: embedding granularity, top-k selection, and prompt design to stay within context windows.
Cosine similarity and memory implications for vector stores:
- Cosine similarity used for ranking:
$$\mathrm{cos_sim}(u, v) = \frac{u \cdot v}{|u|\,|v|}$$
where \(u, v \in \mathbb{R}^d\) are d-dimensional embedding vectors.
- Memory estimate for float32 embeddings:
If \(N\) documents, \(m\) vectors per document, and embedding dimension \(d\), memory in bytes:
$$M = N \cdot m \cdot d \cdot 4$$
Example: \(N = 100\), \(m = 200\), \(d = 768\)
$$M = 100 \cdot 200 \cdot 768 \cdot 4 = 61{,}440{,}000\ \text{bytes} \approx 58.6\ \text{MB}$$
Integration patterns for SageMaker: endpoint naming, region, and AWS credential management matter — using IAM roles in production is crucial.
Streaming UX improvements dramatically increase perceived responsiveness compared to waiting for full responses.
What's next for Innogate
- Persist vector store to a managed vector DB (Qdrant/Pinecone) for scale and multi-user sharing.
- Add multi-document chain-of-thought style reasoning to synthesize insights across dozens of papers.
- Improve scanned document support with OCR and table extraction for more accurate ingestion.
- Add model monitoring, cost dashboards, and autoscaling policies for SageMaker endpoints.
- Provide optional deployment scripts / IaC for SageMaker endpoints (CloudFormation / CDK) and a small local-auth test mode for contributor onboarding.
Built With
- auth0-(+-openfga-optional)
- aws-sdk/client-sagemaker-runtime
- langchain
- langchain-in-memory-vectors-(pluggable-to-qdrant/pinecone)
- node.js-+-fastify
- nvidia-nim-(nemotron-&-nemo-retriever)-on-aws-sagemaker
- pdfjs-dist/pdf-parse
- postgresql-+-drizzle-orm
- react-+-vite
- typescript/javascript
Log in or sign up for Devpost to join the conversation.