-
-
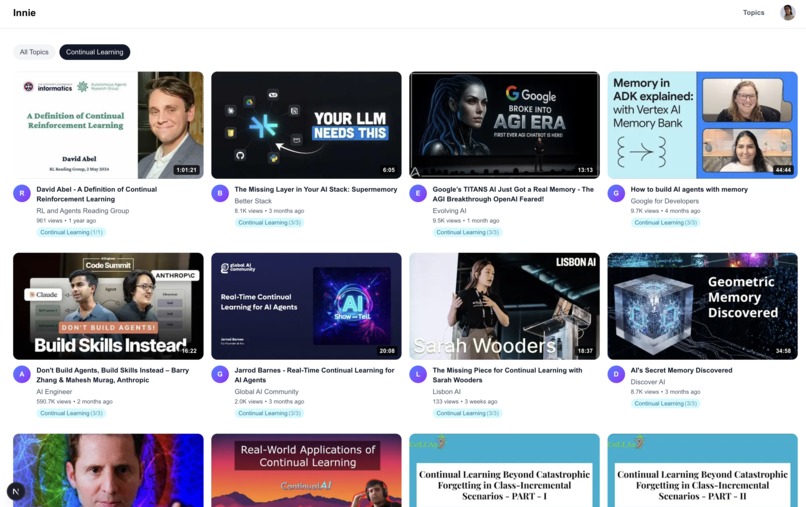
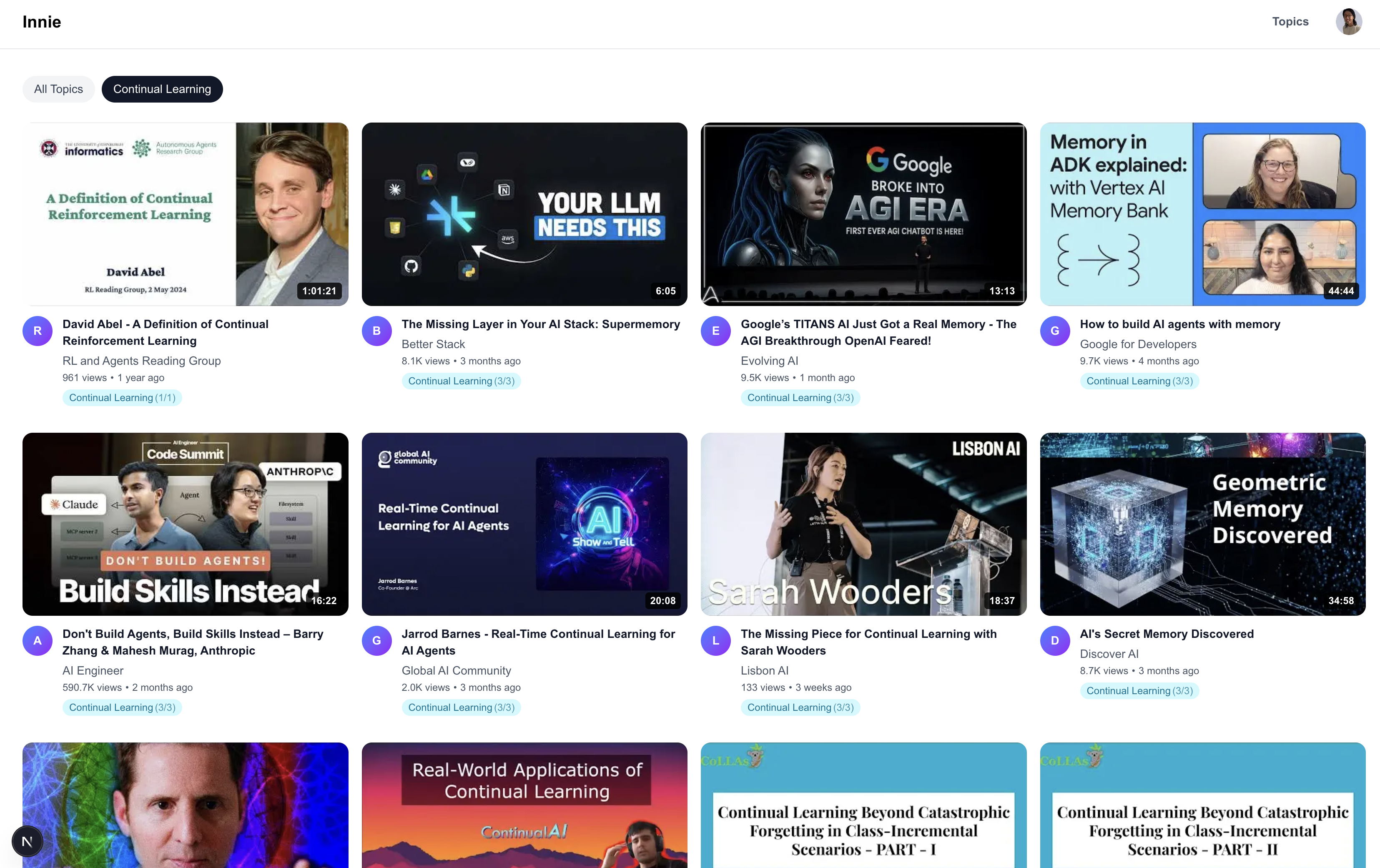
Main page
-
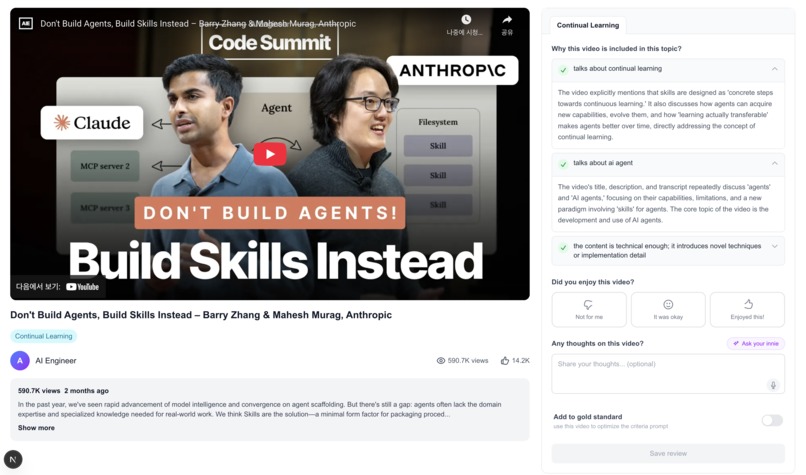
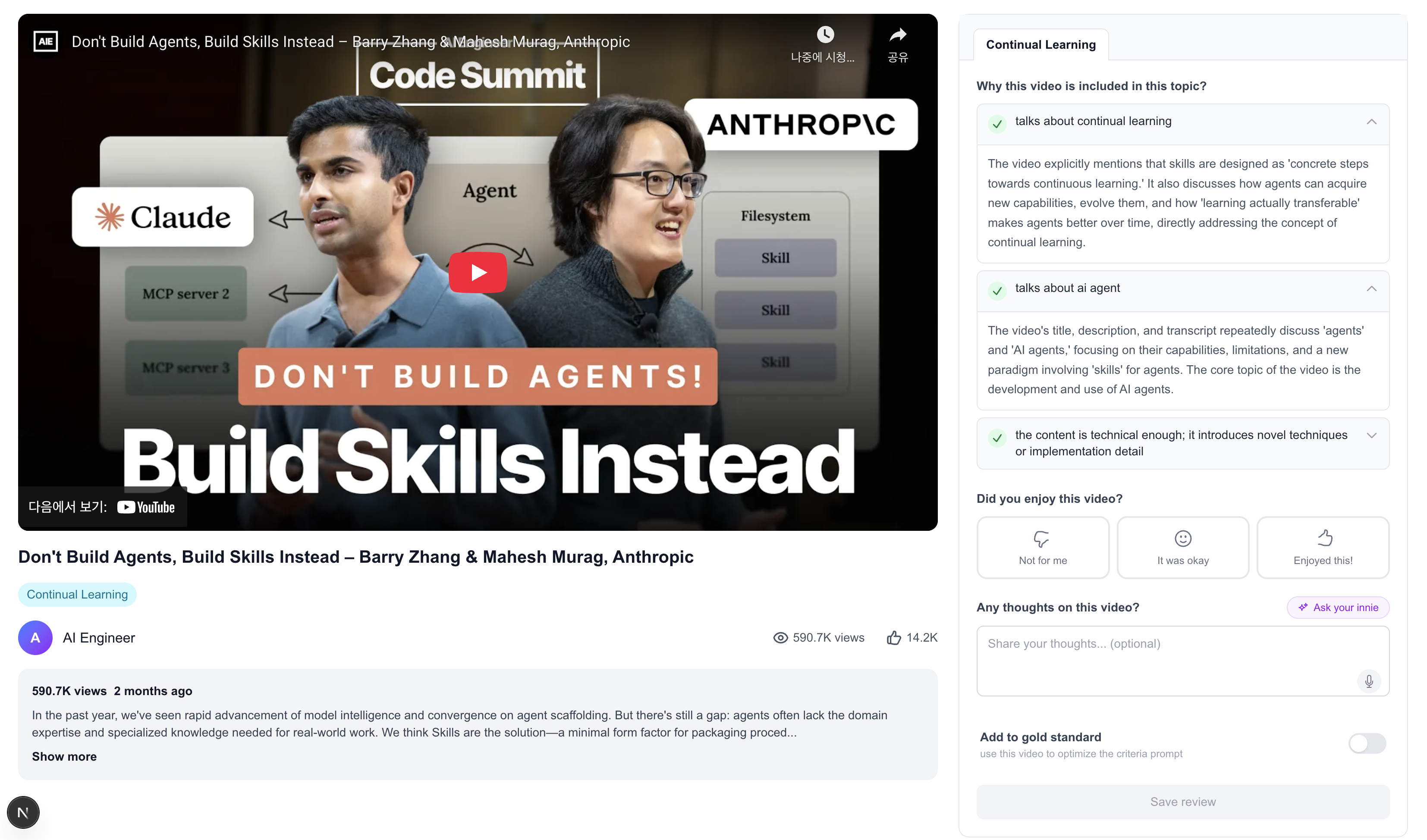
Video watch page with agent's rationale
-
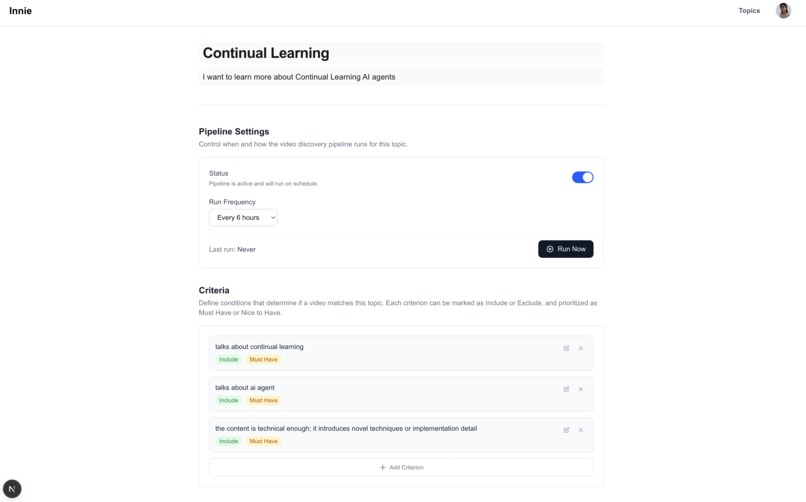
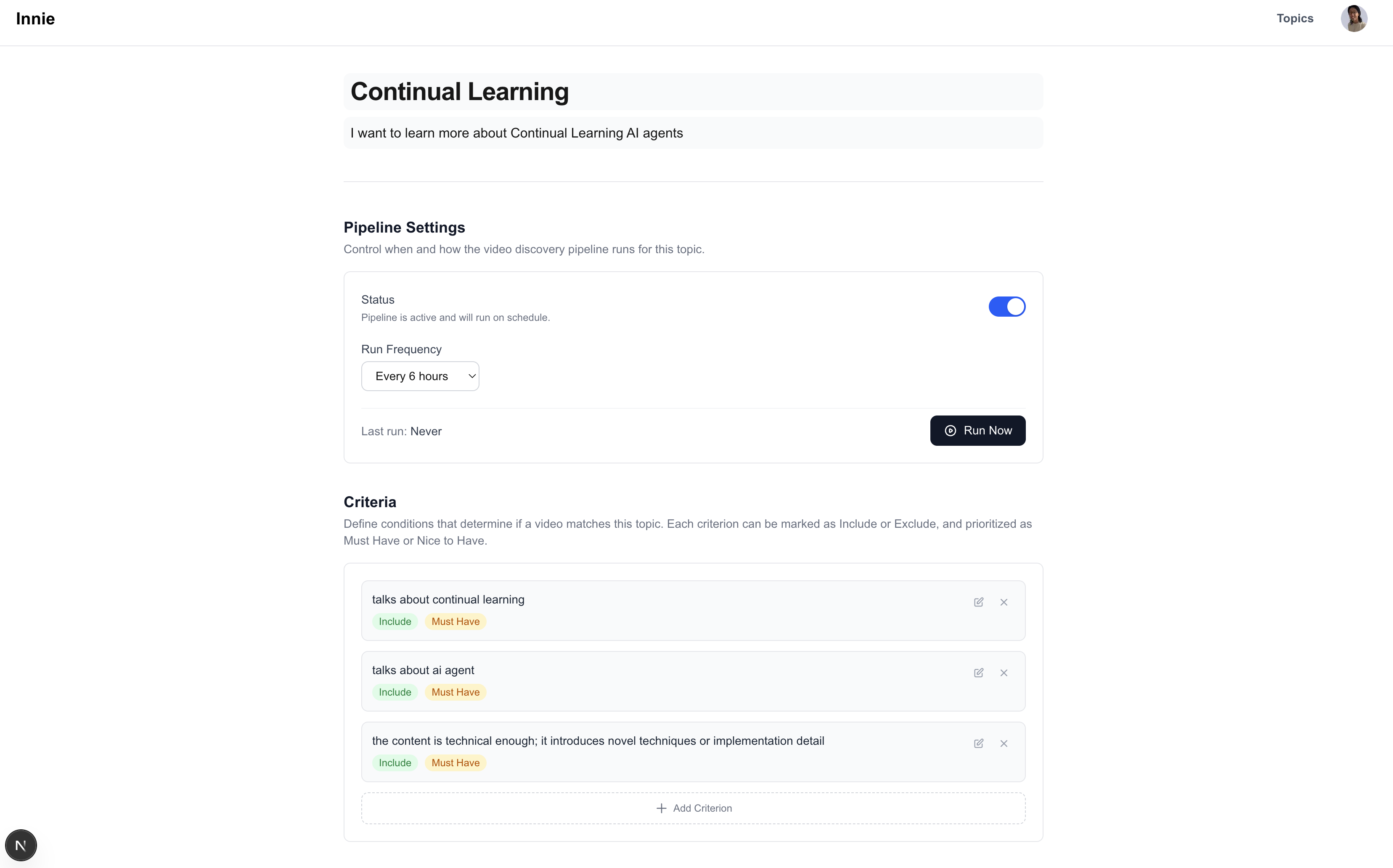
Topic setting page where you can set up criteria
-
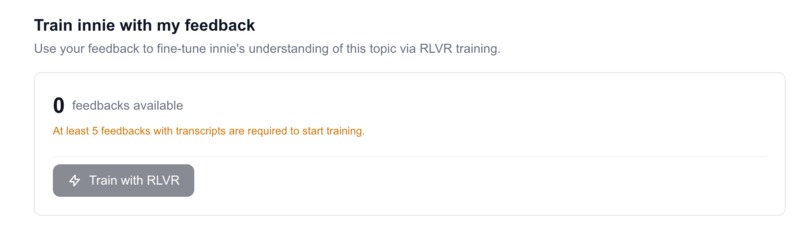
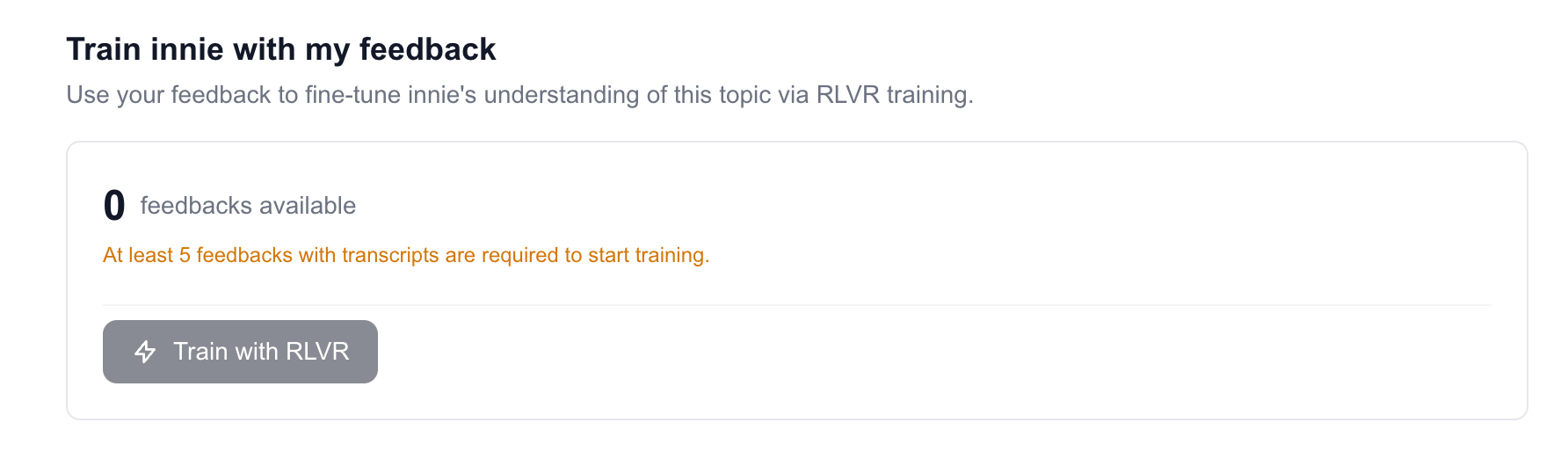
You can train your innie, a fine-tuned LLM based on your feedback!
innie — Explicit, User-Trained Content Recommendation
Today’s content recommendation systems (e.g., YouTube, TikTok) rely almost entirely on implicit signals—clicks, watch time, likes, and skips. These signals are noisy, opaque, and indirect. Users cannot clearly express why they like or dislike content, nor can they directly shape how their feed evolves.
innie addresses this gap by introducing a continuously learning personal agent that understands user preferences expressed in natural language. Instead of guessing intent from behavior, innie lets users explicitly describe what they want—or don’t want—to see. The system adapts in real time, learning what the user actually cares about.
How innie Learns
innie learns at two levels:
In-context learning (prompt updates):
Immediate adaptation based on user feedback in plain English.Weight-level learning:
Long-term personalization through supervised fine-tuning (SFT) and reinforcement learning (RL), allowing preferences to persist and improve over time.
User-Owned Preference Data
Through a well-designed UI/UX, users actively collect and own their preference data. This data is used to train a personal version of innie—a fine-tuned LLM that learns preferences by:
- Imitating user feedback (SFT)
- Trial-and-error learning (RL)
Outcome
The result is a transparent, controllable, and deeply personalized recommendation system, where users understand why they see certain content and can directly shape their own feed.
Built With
- agi
- gemini
- langchain
- lovable
- python
- render
- tinker
- typescript

Log in or sign up for Devpost to join the conversation.