-
-
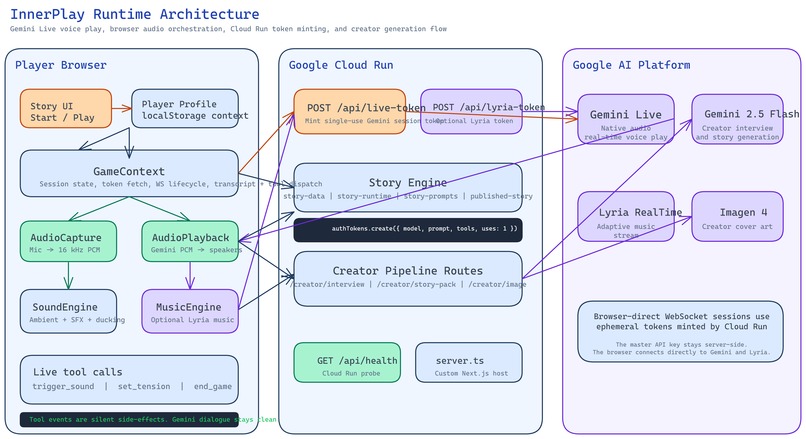
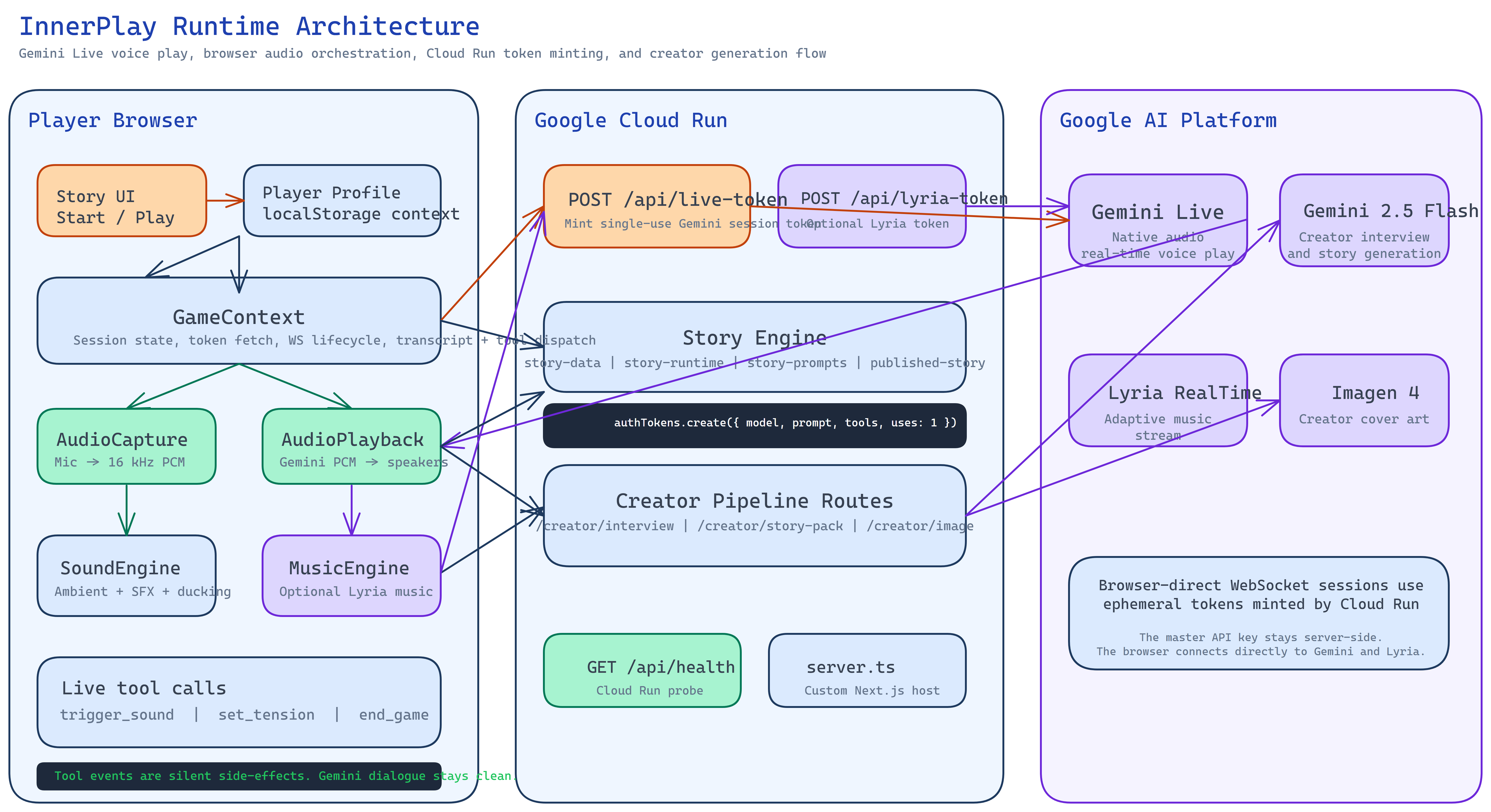
architecture-diagram
Inspiration
I'm an imaginative person. Every night before sleep, I close my eyes and just... wander. I've done it since I was a kid constructing places, following characters, staying in scenes until they feel real. It's the thing I do best, and I never thought of it as a skill until I tried to explain it to someone and they looked at me like I was weird.
I'm also an audiobook listener. Not just non fiction story audiobooks. The kind where a single narrator carries an entire world. I'd listen in the dark, and my imagination would fill in everything the words left out. The voice was a key, and my mind was the room it opened.
At some point I started wondering: what if I could actually be in it? Not watching. Not reading. Actually deciding what happens — and having the story respond to what I said?
What exists right now is passive. You listen to audiobooks. You watch stories unfold. Even "interactive" fiction still mostly means reading text on a screen and clicking choices. None of it felt like what I was looking for.
I wanted something that met my imagination where it actually lives — in the dark, behind closed eyes, powered by a voice that talks back.
That's what InnerPlay is. You put on headphones. You close your eyes. You speak, and the story speaks back. There's no screen. No controller. No interface to navigate. Just you, your voice, and a live AI character that reacts to everything you say, how you say it, and even the length of your silences.
I built this for the version of me that's been lying in the dark imagining stories for years. It turns out I wasn't the only one.
What It Does
InnerPlay is the first game designed to be played with your eyes closed.
Players put on headphones, say "begin," and enter a ten-minute live voice story powered by a Gemini voice agent. There is no interface to navigate, no text to read, no controller to hold. The AI character responds to what you say, how you say it, the length of your pauses, and a player profile that captures your emotional self-portrait — your life stage, values, recurring fears, and conflict style. No two sessions sound the same.
Stories are not branching trees. They are living conversations constrained by arc structure. The AI holds a narrative direction and tension level while staying genuinely responsive to the specific player in the room. If you challenge the character, the story escalates. If you go quiet, the silence becomes part of the experience.
The current catalogue includes:
- The Call — a thriller. You answer a phone. The person on the other end knows more about you than they should.
- The Last Session — psychological horror. Your therapist has scheduled one final appointment.
- The Lighthouse — cosmic horror. Something has been watching from offshore for a very long time.
- Room 4B — body horror. You wake up in a medical facility with no memory of checking in.
- Exit Interview — corporate horror. The HR rep at the end of the table is not reviewing your performance. She is reviewing your choices.
- Me and Mes — inner dialogue. A neutral facilitator maps your functional selves.
Three layers of spatial audio run continuously underneath every session: ambient environment, adaptive music, and the character's live voice. The goal is a ten-minute window where the player forgets there is a machine involved.
How We Built It
Gemini Live API as the Core Loop
The runtime is built around persistent Gemini Live WebSocket sessions using gemini-live-2.5-flash-native-audio via the Google GenAI SDK (@google/genai). Every story opens a native audio session: the browser streams microphone audio directly to Gemini, and Gemini streams synthesized voice audio back in real time. There is no intermediate speech-to-text or text-to-speech pipeline between the player and the model — it handles both ends natively.
The connection architecture is direct by design. The Next.js backend on Cloud Run mints a short-lived ephemeral token via the /api/live-token endpoint — that is the only server-side leg. After that, the browser establishes a WebSocket connection directly to Gemini using the ephemeral token. The audio stream never passes through our server. This keeps latency low and the voice feeling genuinely live.
Story Engine and State Director
Stories are defined as YAML documents validated against AJV schemas. Each pack specifies character persona, phase sequence (assessment → revelation → climax → resolution), sound cue triggers, and tension parameters. At session start, a bounded system prompt encodes the current phase's emotional target and permitted actions — not a script.
The State Director runs server-side and monitors the transcript stream from Gemini. Rather than using Gemini's tool call mechanism (which introduced latency and reliability issues in the live audio stream), the State Director uses pattern matching and semantic heuristics on the rolling transcript to detect phase boundaries and trigger audio cues. When the story phase changes, the State Director updates in-context instructions; the session does not restart.
Player Profile Personalization
Before playing personalized stories, players complete a questionnaire that produces a PlayerProfile stored in localStorage. The profile captures identity summary, behavioral patterns (conflict style, pressure tolerance, attachment tendency), emotional map (dominant emotions, avoided emotions, shame triggers), and narrative fragments (unfinished decisions, feared identities, desired identities).
At session start, a bounded GameProfileContext slice — not the full profile — is injected into the system prompt. The profile conditions how the character opens, what it notices, and where the story applies pressure. No raw psychological data is sent to the model without the player approving it first.
Three-Layer Spatial Audio
The Web Audio API manages three independent audio layers:
- Ambient — continuous environment sound (ringing telephone, hospital hum, ocean static), looped and crossfaded between scenes
- Music — tension-aware background scored to the current phase
- Voice — Gemini's live audio stream, positioned spatially in the stereo field
Audio cues triggered by the State Director cause ambient transitions in real time. The sound layer degrades gracefully to voice-only on low-end connections. Sound layers fade in before the character speaks — by the time the first line arrives, the player is already in the environment.
Backend: Google Cloud Run
The Next.js application runs on Google Cloud Run behind a custom server built with tsx to support persistent WebSocket connections (which the default Next.js server does not handle natively). The Docker container is deployed to us-central1, project innerplay-488718, service innerplay-gemini, and scales to zero between sessions to keep costs low.
The /api/live-token endpoint mints short-lived ephemeral tokens for Gemini Live sessions, keeping API keys off the client. Average token mint latency in production is under 350ms.
Challenges We Ran Into
Opening-Turn Lockup. The first and most damaging bug: when Gemini completed an opening turn without producing any audio or text payload — which is a valid model behavior — the opening-turn state machine refused to release the microphone. The player heard silence and the session was permanently stuck with no error message. We instrumented 11 startup timing stages (begin_clicked through first_turn_finalized) before the real cause became visible in the traces.
Transient 1008 WebSocket Closes. Gemini Live sessions occasionally close with a 1008 policy violation before the first transcript arrives. These are transient inference-side failures, not client configuration errors, and the error strings alone are not enough to tell them apart. The fix was a classification layer that distinguishes retryable transient closes from permanent errors, then executes a single reconnect attempt with guard logic preventing duplicate audio or transcript entries. An unbounded retry loop would have amplified the latency problems it was trying to solve.
Sanitizing Model Mechanics from the Transcript. Gemini embeds structured cues inline in its output stream. Without sanitization, the transcript the player sees would contain raw model output mixed into the story dialogue. We built a streaming sanitizer that strips these blocks in real time without splitting words across chunk boundaries — naive sanitization collapsed adjacent words when chunks landed mid-sentence.
Structured Arc vs. Freeform Generation. The hardest product problem: how do you constrain an open-ended model to follow a narrative arc without making it feel scripted? The answer was phase-gated instruction injection — describe the emotional target and permitted actions for this phase, not the words to say. The horror stories needed the model to maintain dread without the player explicitly setting the tone, which required per-story tuning.
Accomplishments That We're Proud Of
A working eyes-closed game. This sounds simple but it required every layer of the system working correctly together: reliable session startup, voice-first interaction, spatial audio, and a story engine that holds narrative tension without a visible UI. You close your eyes and you are somewhere else.
The creator pipeline. A storyteller with no coding background can describe a story concept in a multi-turn conversation with a Gemini interview agent and publish a playable live-voice story in under twenty minutes. The pipeline does not require manual JSON editing or prompt engineering.
Player profile personalization without a database. The PlayerProfile system provides meaningful story conditioning from localStorage alone. The profile is questionnaire-generated, user-reviewed, and bounds the context injected at session start to a small slice.
Zero-UI positioning. Every design decision — no loading spinners, no progress bars, no chat bubbles during play — pushed the technology into the background. The sound layers fade in before the first word is spoken.
The State Director pattern. Using transcript analysis instead of live tool calls to drive audio state gave us reliable, latency-free audio cuing without the instability that in-stream tool calls introduced in the live audio context.
What We Learned
The live API's failure modes are subtle. The most dangerous issues were not crashes — they were silent hangs. Gemini completing a turn without payload. Sessions closing with ambiguous status codes. Audio draining longer than turnComplete signals suggested. The instrumentation we added turned invisible problems into measurable ones.
Voice-first design requires different constraints than text-first. In a text interface, a player can re-read a confusing line. In a voice interface, confusion is permanent — the moment is gone. Every opening line, every phase transition had to be tuned for one-shot comprehension at audio speed.
Constraints are creative fuel. Removing the screen did not limit what InnerPlay could do. It forced every element to earn its place. The spatial audio system exists because there was no visual layer to carry atmosphere. The player profile exists because there was no visual customization to make people feel seen.
Short-form is the right format for this medium. Ten minutes is not a limitation — it is the design. A player can commit to ten minutes of darkness in a way they cannot commit to a hundred. The session end is part of the experience, not a failure state.
The brain is the best rendering engine. Players described seeing things they knew were not there — a hospital corridor, a lightkeeper's silhouette, a boardroom table. The voice did not describe those things in detail. The player's imagination did. The voice just gave it permission.
What's Next
More stories across genres — mystery, romance, existential comedy, sci-fi. The creator pipeline makes this tractable without building each story manually.
Multiplayer voice sessions: two players, one story, one AI narrator managing both. The tension of having another person's reactions visible to the AI — and invisible to you — is a design space that does not exist anywhere else.
Community creator tools, so storytellers can publish and share story packs publicly.
Mobile-native release — the core experience already works on mobile browsers, but a dedicated app would unlock tighter audio hardware integration and session history.
Lyria adaptive music at full fidelity. The experimental adaptive music integration is in the codebase behind a feature flag. When the API reaches production stability, the music layer will respond to tension in real time.
Cross-session memory. Player profiles are currently session-local. A cloud sync layer would let the AI remember how you played "The Call" when you walk into "Me and Mes."
Built With
- ajv
- cloud
- docker
- gemini
- gemini-2.5-flash
- gemini-live-2.5-flash-native-audio
- genai
- google-cloud-run
- google-genai-sdk
- live
- nextjs
- playwright
- react
- sdk
- speech-to-text
- text-to-speech
- typescript
- vitest
- web-audio-api
- websocket
- yaml


Log in or sign up for Devpost to join the conversation.