-
-
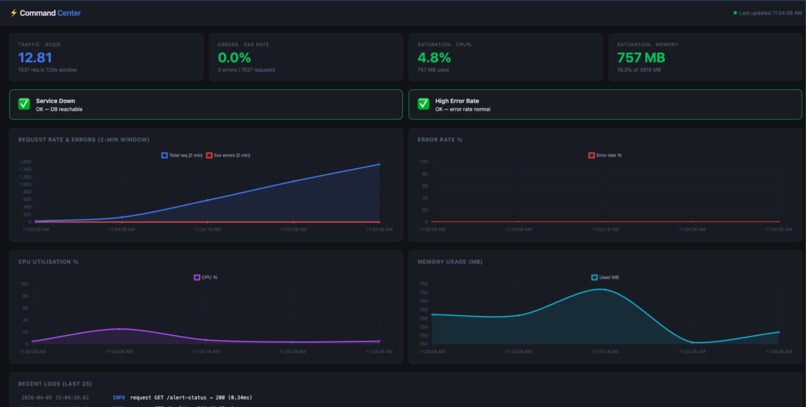
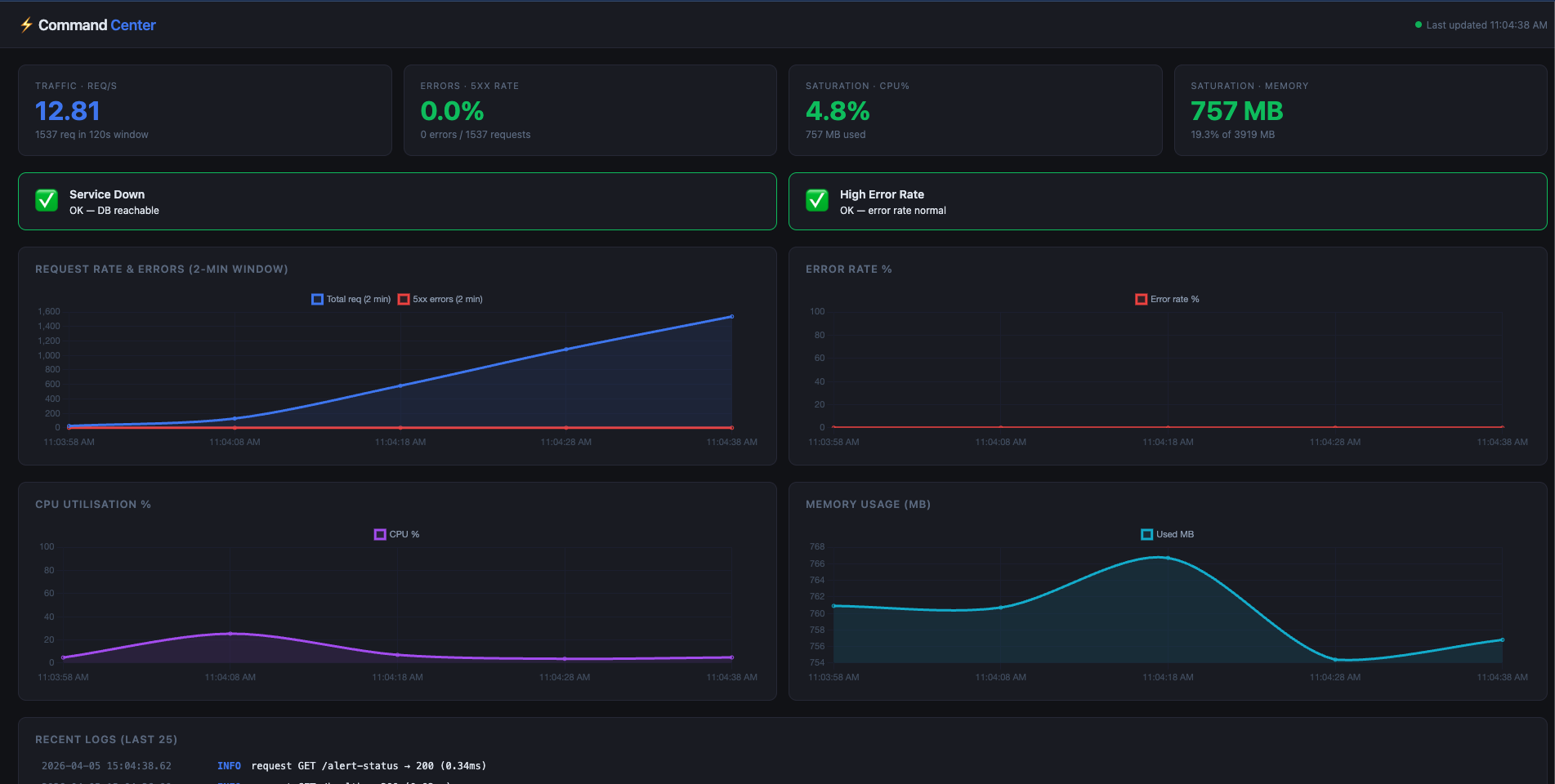
Grafana dashboard using Prometheus server
-
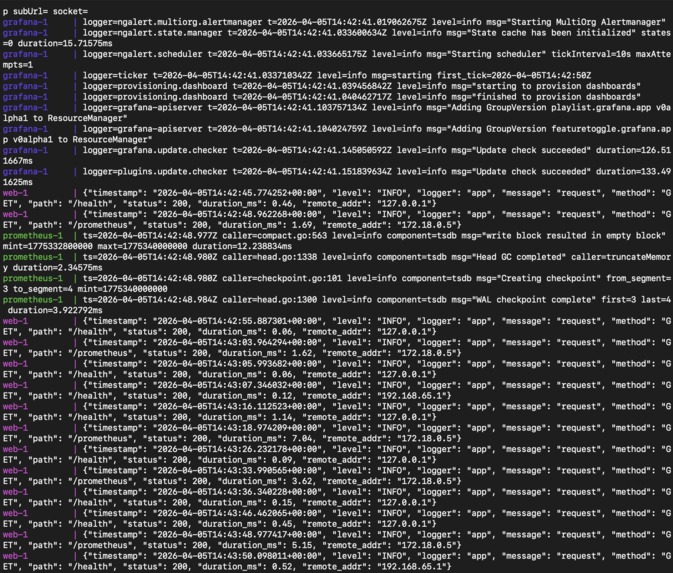
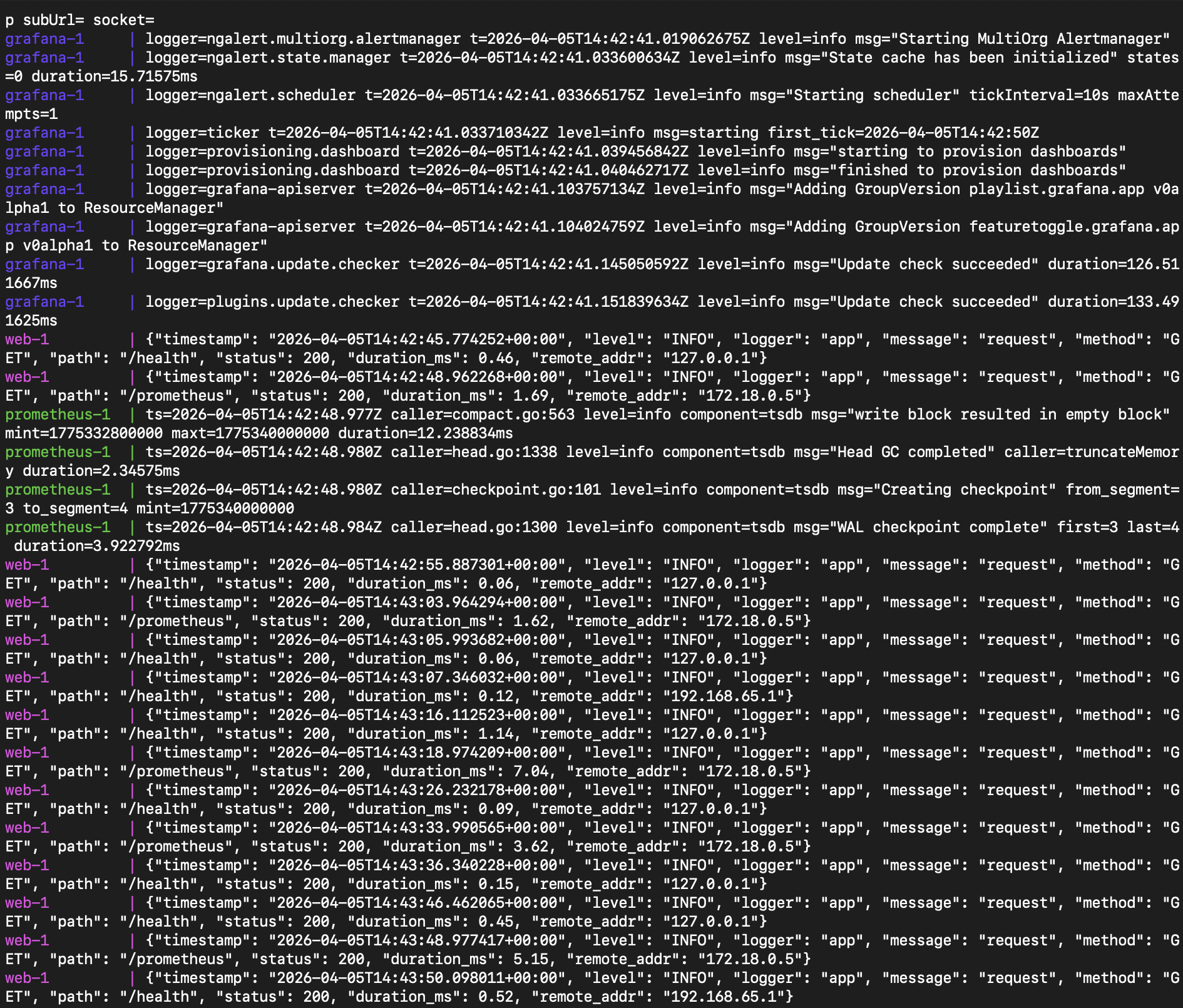
Docker container logging
-
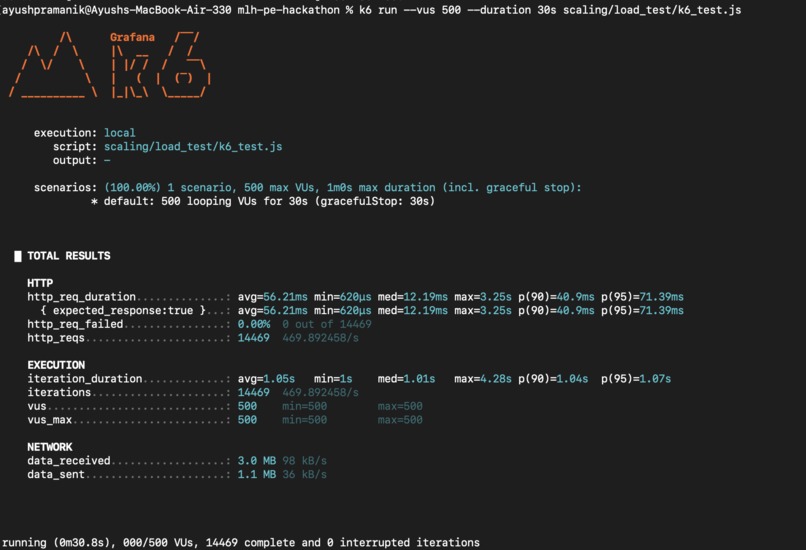
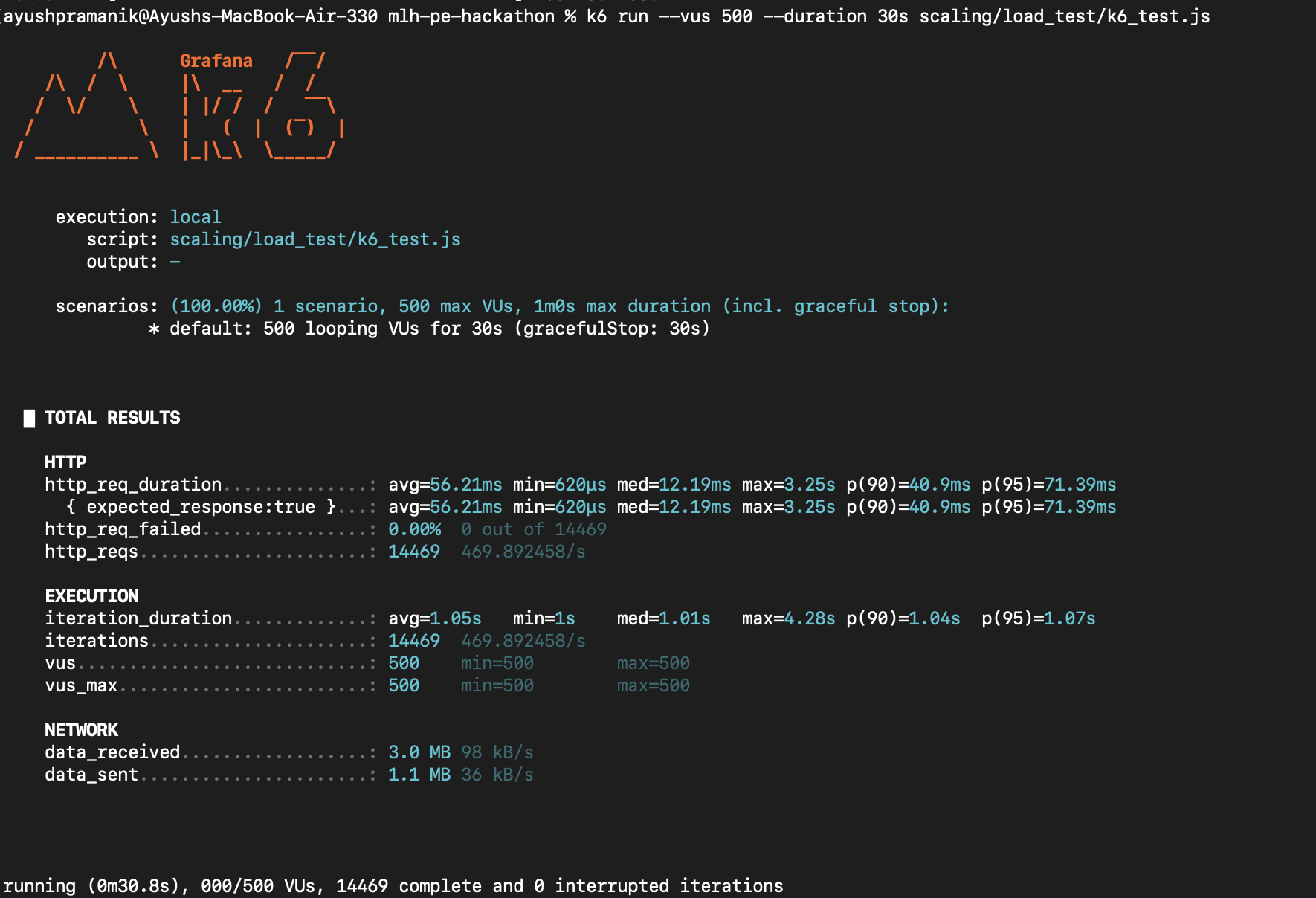
500 concurrent users using k6 load-testing
-
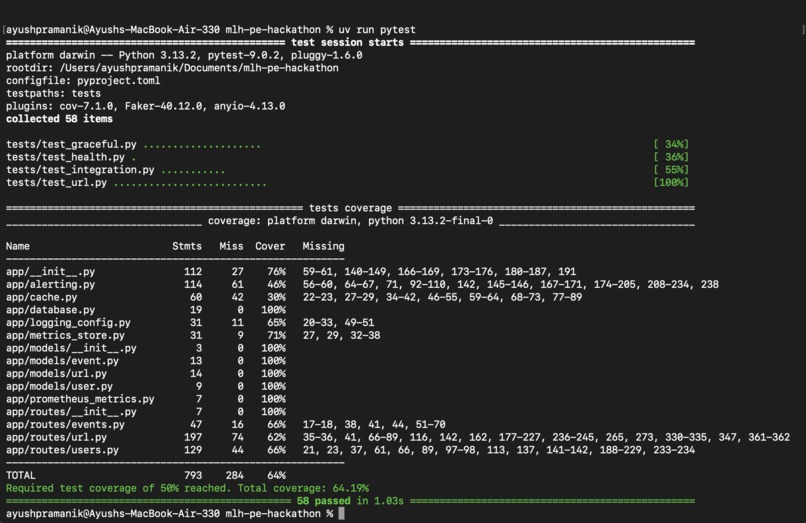
Pytest unit testing
-
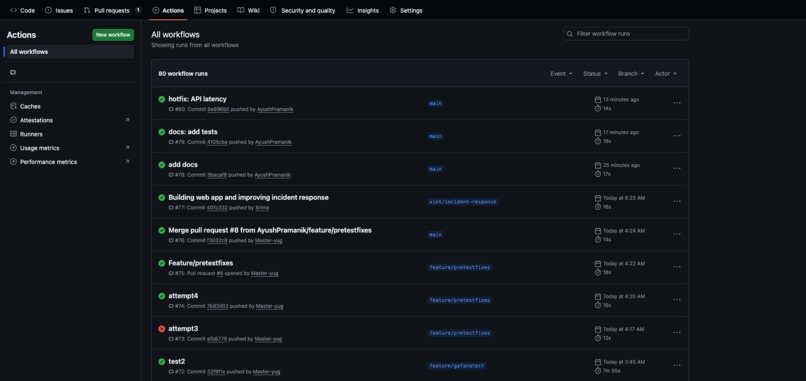
Github workflows CI
Inspiration
Production systems fail in fascinating and humbling ways. For the MLH Production Engineering Hackathon, we wanted to build something that doesn't just work, but survives.
What We Built
We built a production-grade URL shortener with Flask, Peewee ORM, and PostgreSQL. Engineered with reliability, observability, and chaos resilience in mind.
At its core, it's a REST API that shortens URLs, tracks redirects, and manages users and events. But what makes it interesting is everything around the happy path:
- Automatic crash recovery via Docker's
restart: alwayspolicy — kill the container, it comes back within seconds - Graceful error handling across all 400, 404, and 500 scenarios — clients always get JSON, never an HTML stack trace
- Collision-resistant short code generation with retry logic that statistically never fails
- Full observability with Prometheus metrics, Grafana dashboards, and structured request logging via Nginx
- Load testing with k6 to validate performance under pressure
- Redis caching to reduce database load on hot redirect paths
- Chaos Mode — a documented fire drill that simulates crashes and proves self-healing works
How We Built It
We started with a minimal Flask app factory pattern and layered in production concerns one at a time:
- Database layer — Peewee ORM with
DatabaseProxyfor clean connection lifecycle management,reuse_if_open=Truefor resilience, anddb.atomic()for safe bulk inserts - Containerization — Dockerized the app and database with a
docker-compose.ymlthat wires health checks, volume persistence, and restart policies - Monitoring stack — Added Prometheus for metrics scraping and Grafana for real-time dashboards, all living in the
monitoring/directory - CI/CD — GitHub Actions workflow for automated testing on every push
- Failure documentation — Wrote a detailed
RUNBOOK.mdand Failure Manual covering every known failure mode and its recovery path
Challenges We Faced
- Connection management in Flask + Peewee is subtle — we had to carefully handle
before_requestandteardown_appcontexthooks so connections are always opened, reused, and closed correctly, even when requests fail mid-flight - Making every error response JSON required global
errorhandleroverrides for 404, 405, and 500 — Flask's defaults return HTML, which is terrible for API clients - Designing the Chaos Mode demo to be reproducible and educational took iteration — we wanted anyone to be able to run
docker killand watch the app self-heal live - Balancing simplicity with production patterns — this project doubles as a hackathon starter template, so we had to keep the scaffolding clean while still demonstrating real engineering practices
What We Learned
- Reliability isn't a feature you bolt on at the end — it has to be designed in from the first
docker-compose.yml - Writing a Failure Manual before things go wrong forces you to think clearly about your system's dependencies and failure modes
uvis a genuinely excellent Python toolchain and we're never going back- Chaos engineering is more fun (and more revealing) than it sounds
What's Next
- Expand the seed dataset and add analytics endpoints for click-through tracking
- Add rate limiting via Redis to protect against abuse
- Integrate distributed tracing with OpenTelemetry
- Explore horizontal scaling with Nginx load balancing across multiple Flask workers


Log in or sign up for Devpost to join the conversation.