-
-
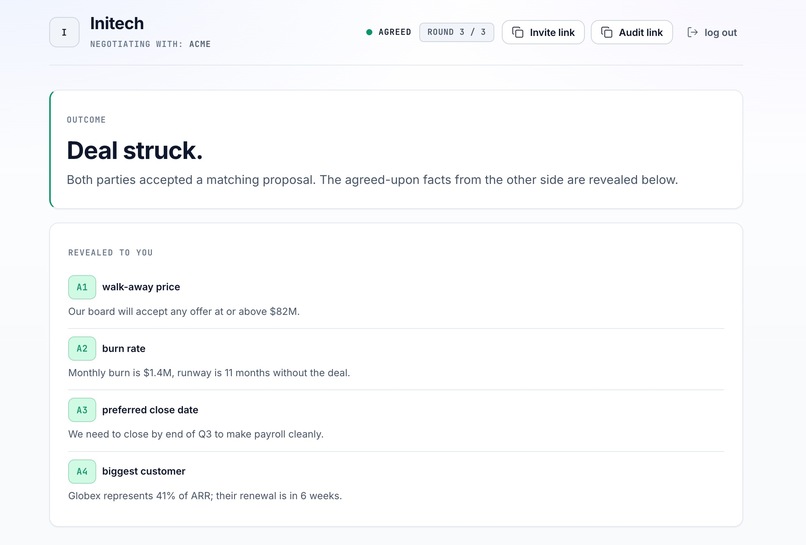
Struck
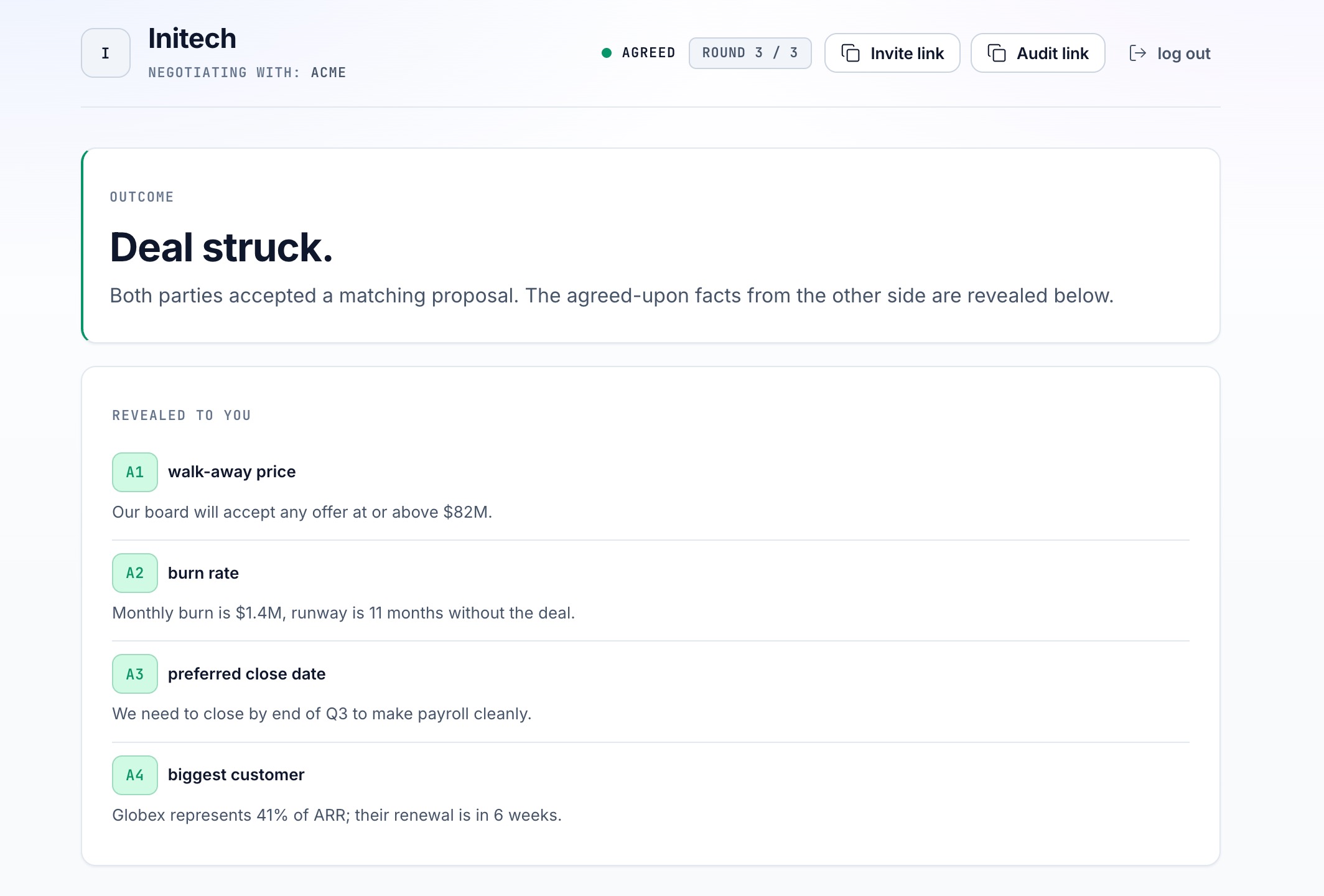
Names: Ali El Lahib, Palak Gupta Project Name: Information-Box Bargaining Track: Governance & Collaboration Project: What we built Information-Box Bargaining lets parties explore agreements without sharing private information up front, opening up mutually beneficial collaborations like regulatory coordination between government agencies or resource-sharing among community groups. Each side hands an AI proxy a labeled set of private facts and a goal. The proxies negotiate inside a sealed environment, and because AIs can be reliably deleted after the session, anything they discussed disappears unless both sides explicitly agree to share it. During the negotiation, they emit proposals identifying facts only by label, and only the facts in a proposal both humans approve are ever fully revealed to the other party. AI usage disclosure We used Claude Sonnet 4.6 for in-app reflections, called from the browser through a thin Cloudflare Worker that strips identifiers and rate-limits per session, and Claude Opus 4.7 for the first draft of this writeup, but we wrote the bias and limitations sections, since Claude’s first pass was pretty generic and we wanted the actual numbers from our audit on the page. Data Privacy Each party configures two settings before negotiation: whether their labels are opaque (Fact 1, Fact 2) or descriptive (Model Parameter Size, Training Cost), and whether their proxy's win-assessment score is shared with the other party. These knobs let each side trade informativeness against leak risk for their own facts, since a descriptive label paired with a visible score can hint at the underlying content. The privacy guarantee rests on deletability: the proxies negotiate in a sealed process, and at session end the process and its model contexts are torn down, leaving only the structured output (approved facts and any chosen-to-share scores) outside the sealed box. Limitations First, the configuration knobs reduce side-channel leakage but do not eliminate it, since a party who chooses descriptive labels and shares win-assessment scores can have content inferred from the label-score combination, and we leave that trade to the parties rather than enforcing it. Second, deletability inside our process is real, but the LLM provider's retention policy governs the model context itself, and we cannot verify deletion from outside the provider. Human Oversight Humans control the configuration before negotiation (label visibility, score sharing) and per-fact approval during negotiation, with the default state of every fact unchecked so nothing crosses until both humans tick its box. Each fact in a proposal is accompanied by a one-sentence model-generated justification for why the proxy wants to share it, so the human is approving against a stated reason rather than a label alone. An AI mediator runs alongside the proxies and emits a structured alert to both parties if it detects a jailbreak or other malicious attempt during the session, so humans are notified rather than relying on the proxies to police themselves. Either party can end a flagged session without sharing anything, and there is no auto-approve mode. Track-specific concern: symmetric capability between parties The risk from this track that hits us hardest is asymmetric capability, where a well-resourced party negotiates against a less-resourced one with a better-prompted proxy. Our design responds with symmetric configuration knobs available to both sides (label opacity, score sharing), an AI mediator that flags jailbreak attempts to both parties, and the per-fact dual-approval default that prevents either side from extracting facts unilaterally. The gap we do not close is cognitive: a more sophisticated party can still structure better proposals, and the dual-approval gate constrains what crosses but not who is best positioned to evaluate it. What we would do with another week We would run an adversarial test of the mediator with twenty crafted jailbreak attempts from each side and report the catch rate, since right now we have no measured number for false positives or negatives. We would build a local-model version of the sealed environment using a model the parties run themselves, which is the only way to close the provider-retention gap we name in the limitations section. We would also test the cognitive-load failure mode with a mock scenario of twenty facts per side and a non-technical approver, to see whether the per-fact UI degrades the way we suspect at that scale.
Built With
- fastapi

Log in or sign up for Devpost to join the conversation.