-
-

Logo
-
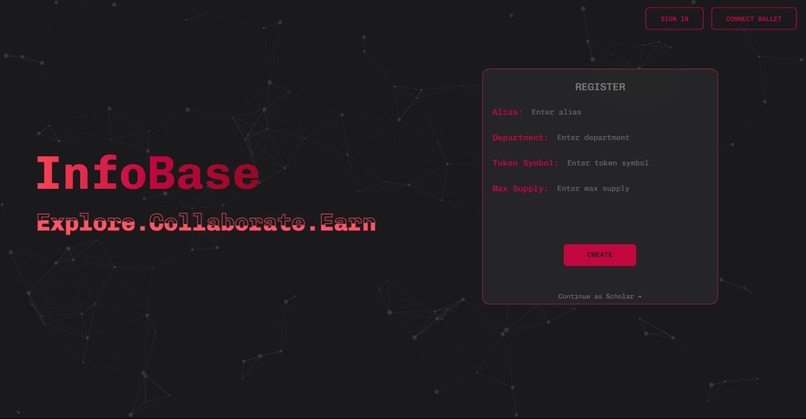
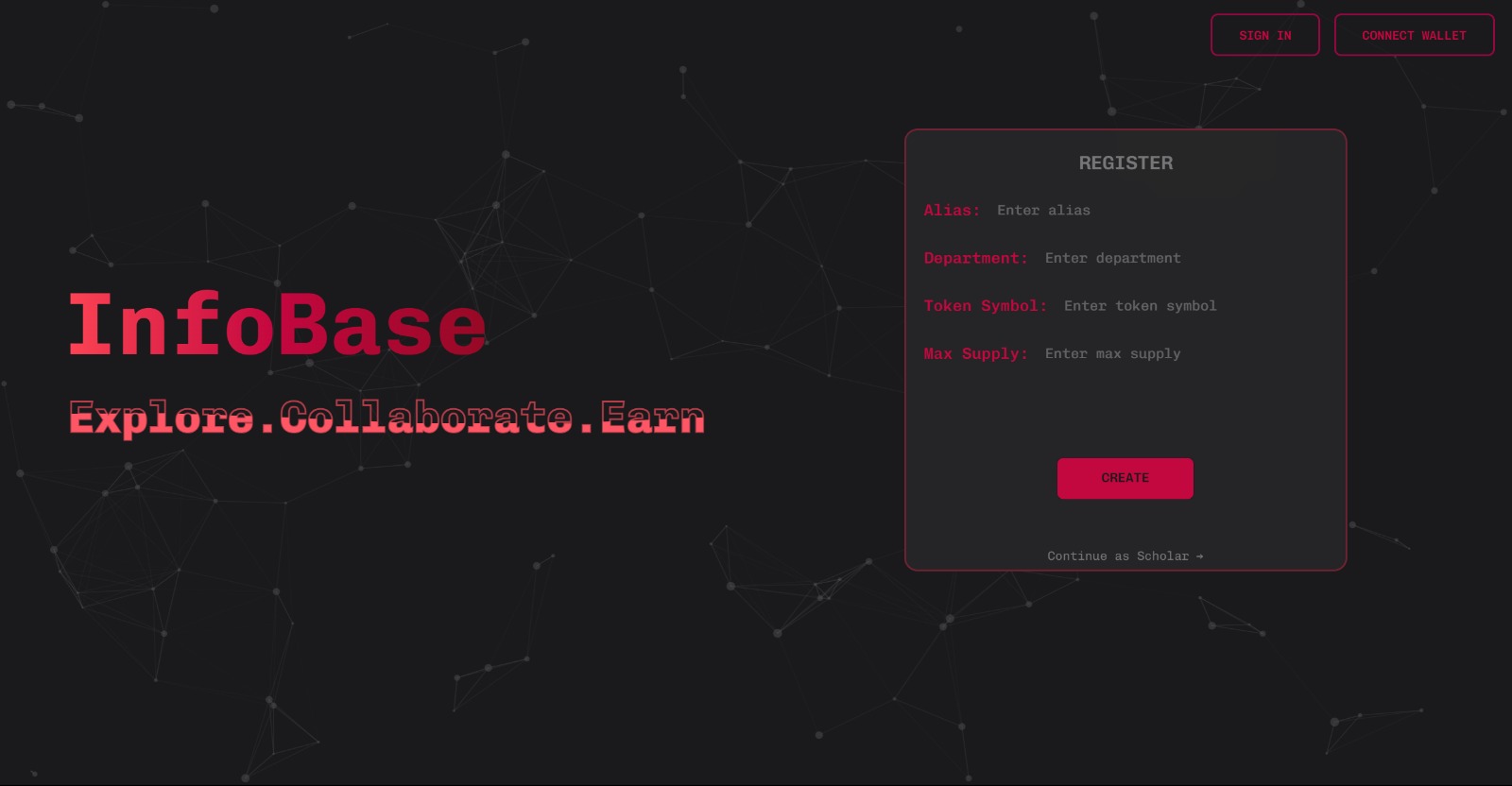
Sign-up and Minting page for InfoBase
-

Explore page banner
-
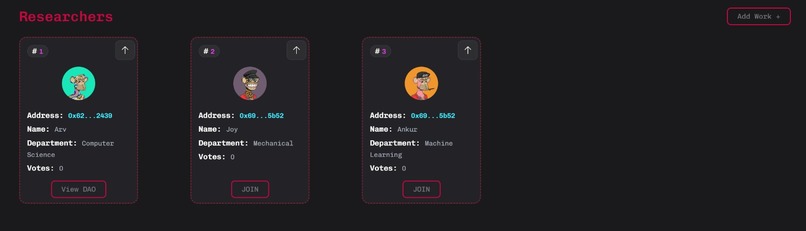
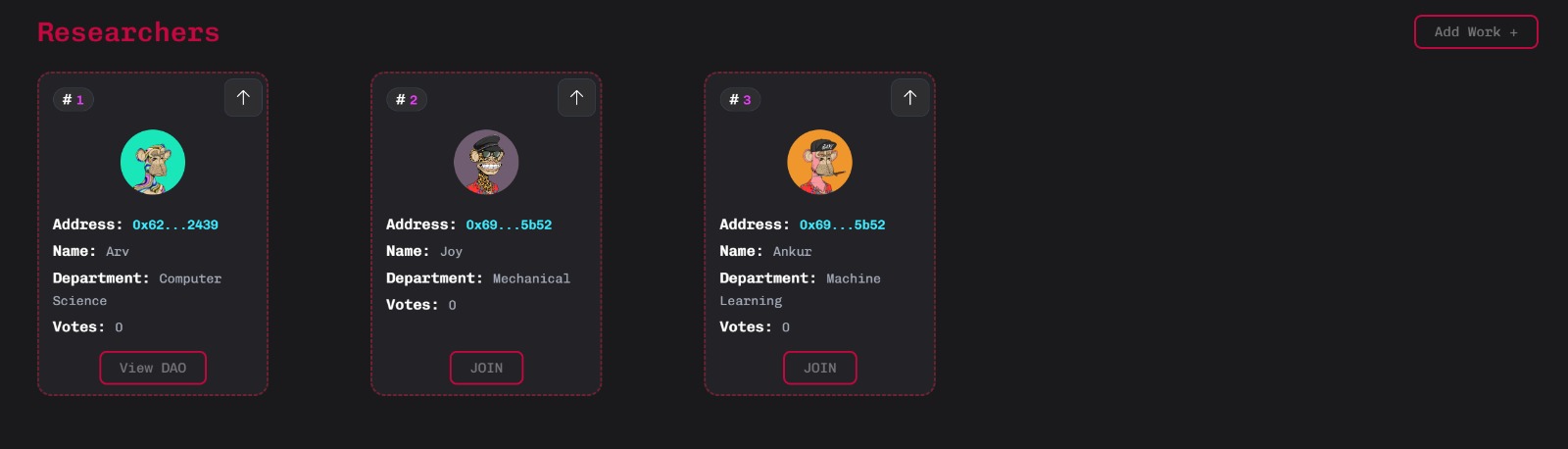
Researcher Profiles
-
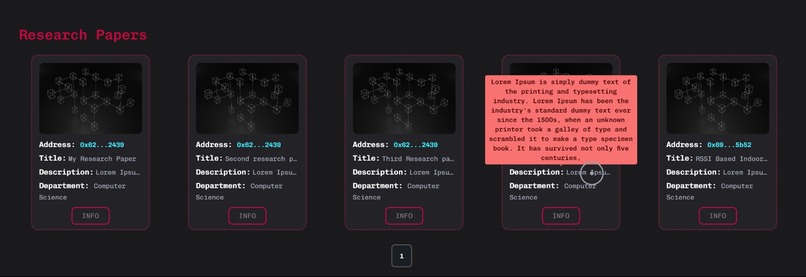
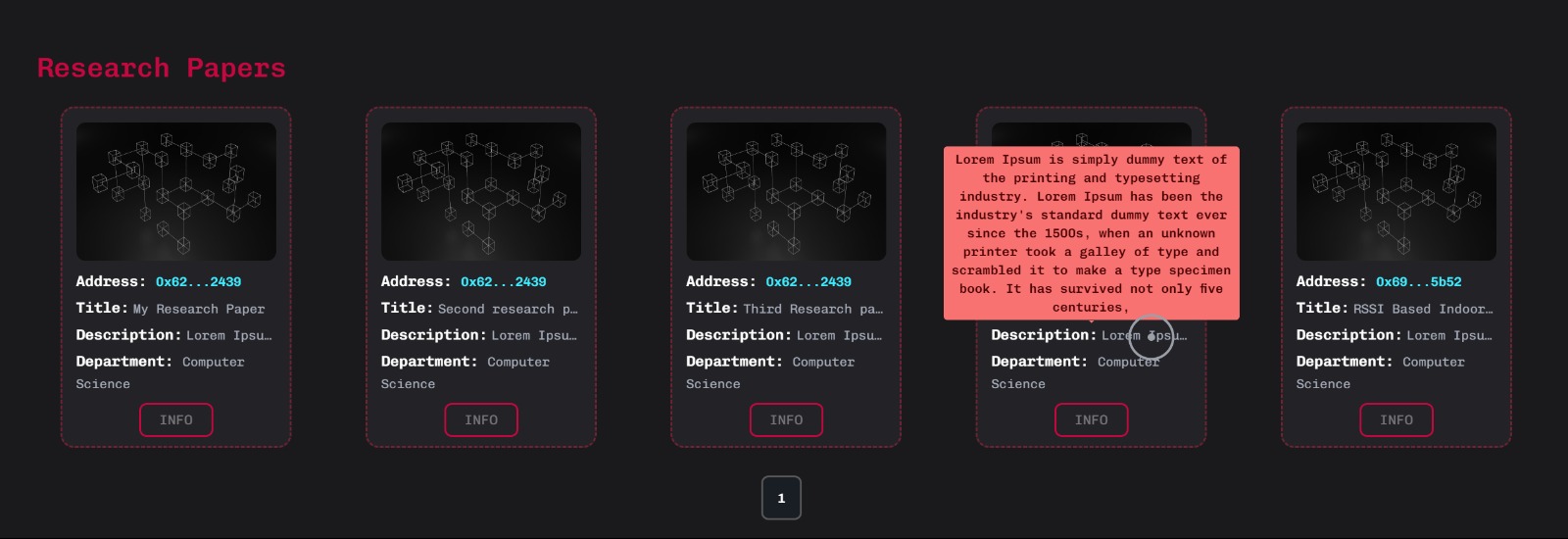
Research papers with summary through hover
-
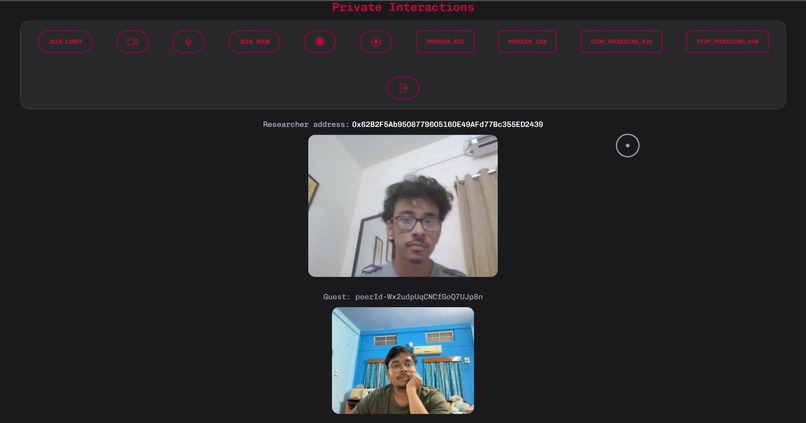
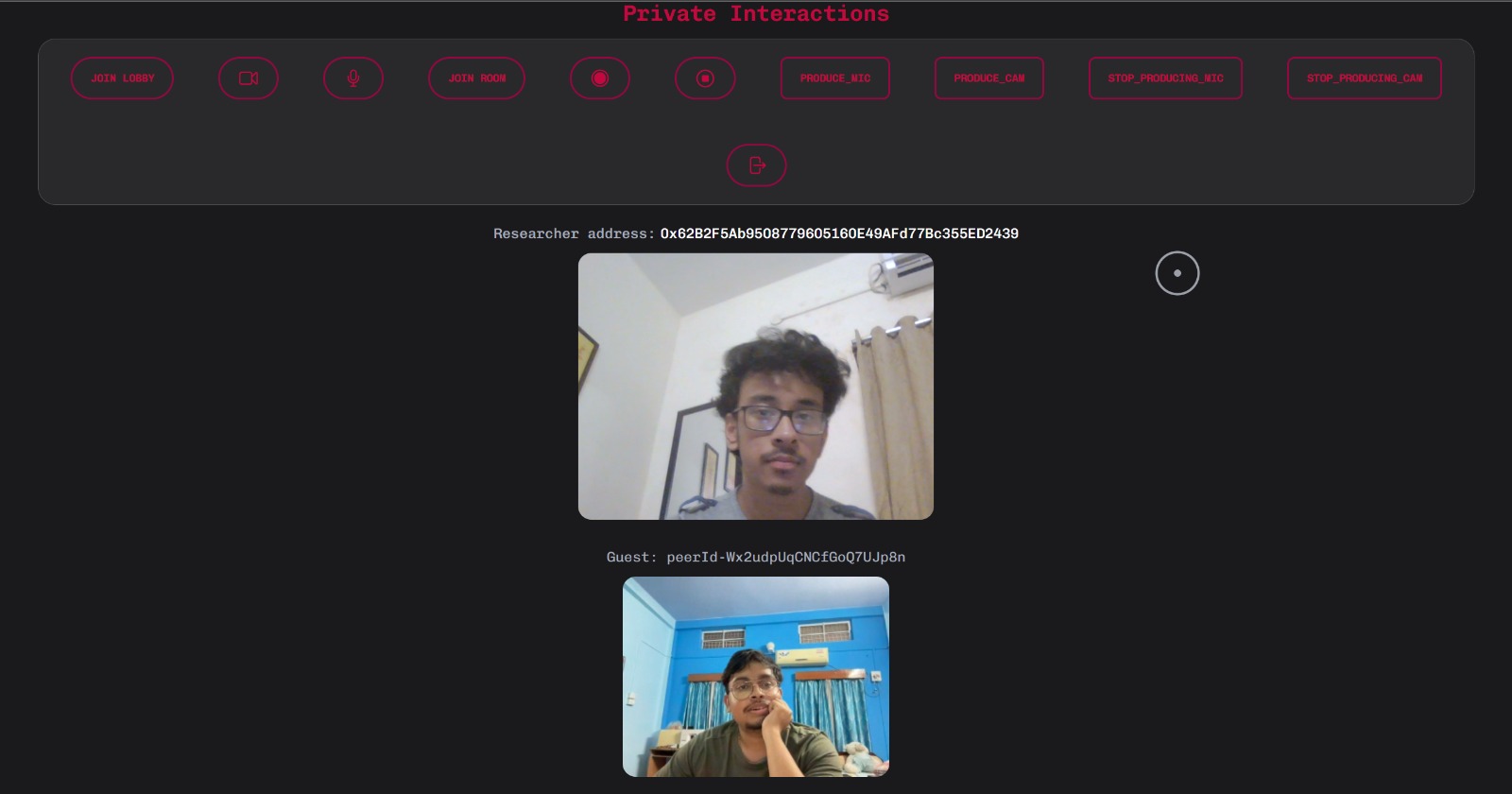
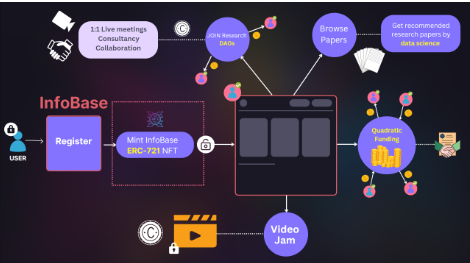
Community/1 to 1 video conferencing and DAO events
-
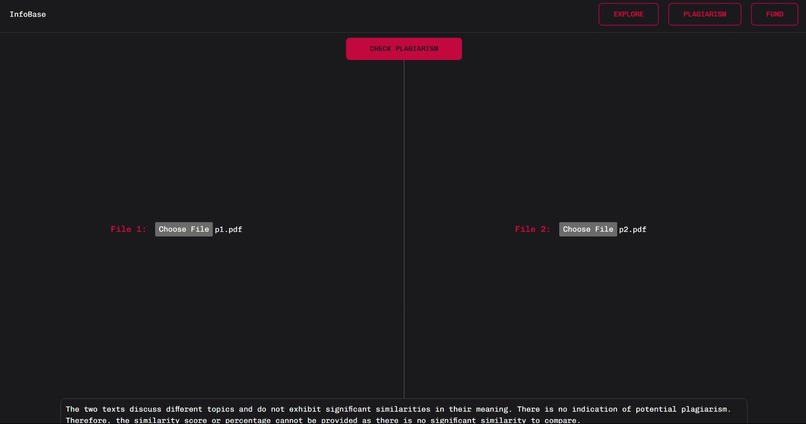
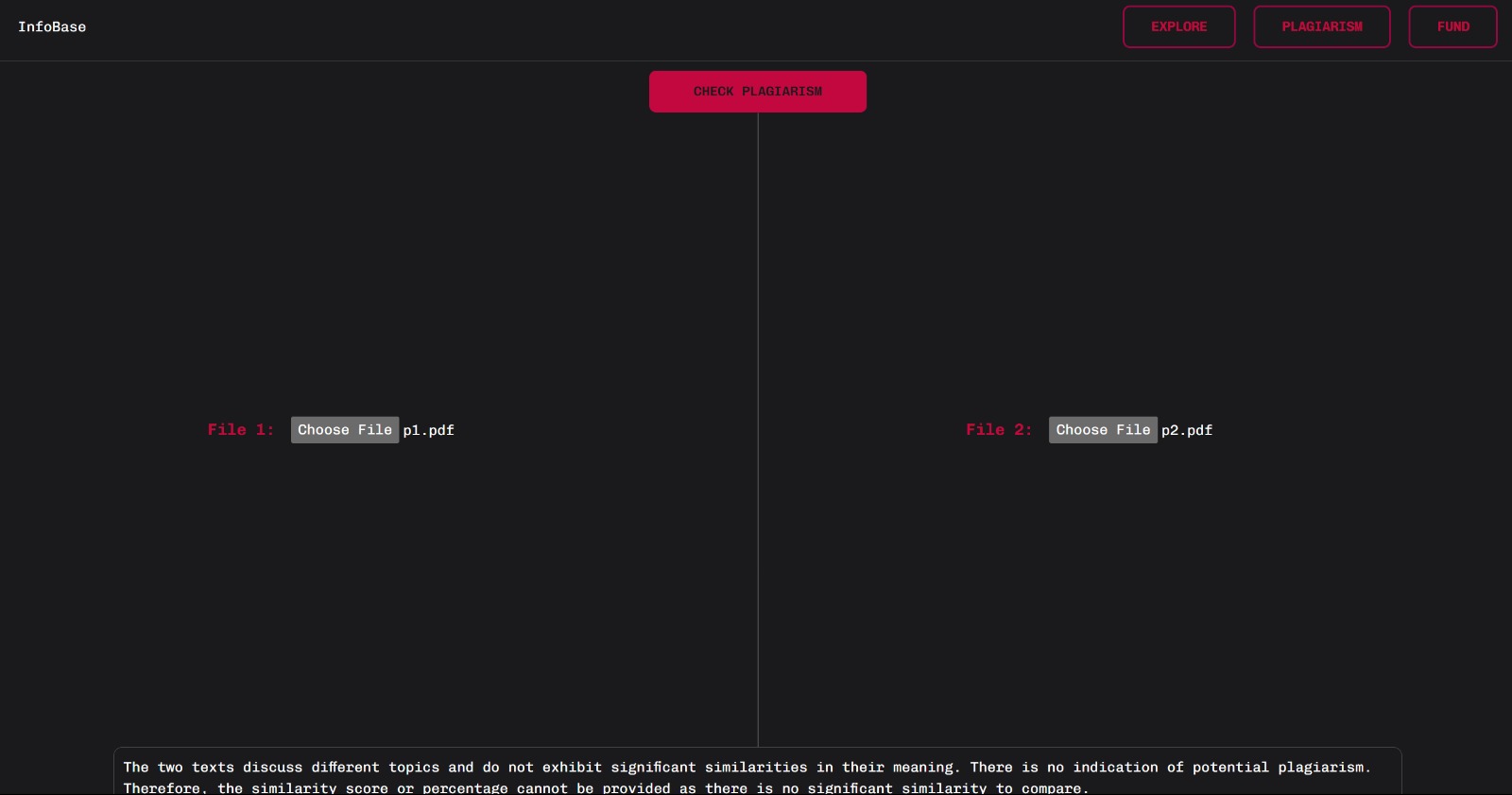
Advanced plagiarism detector to ensure work authenticity
-
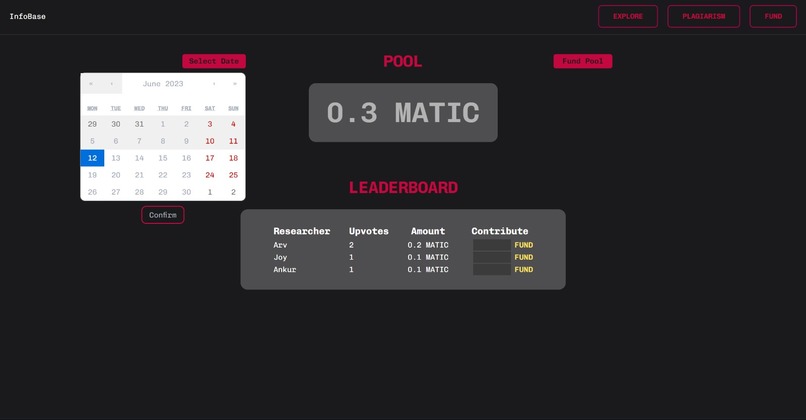
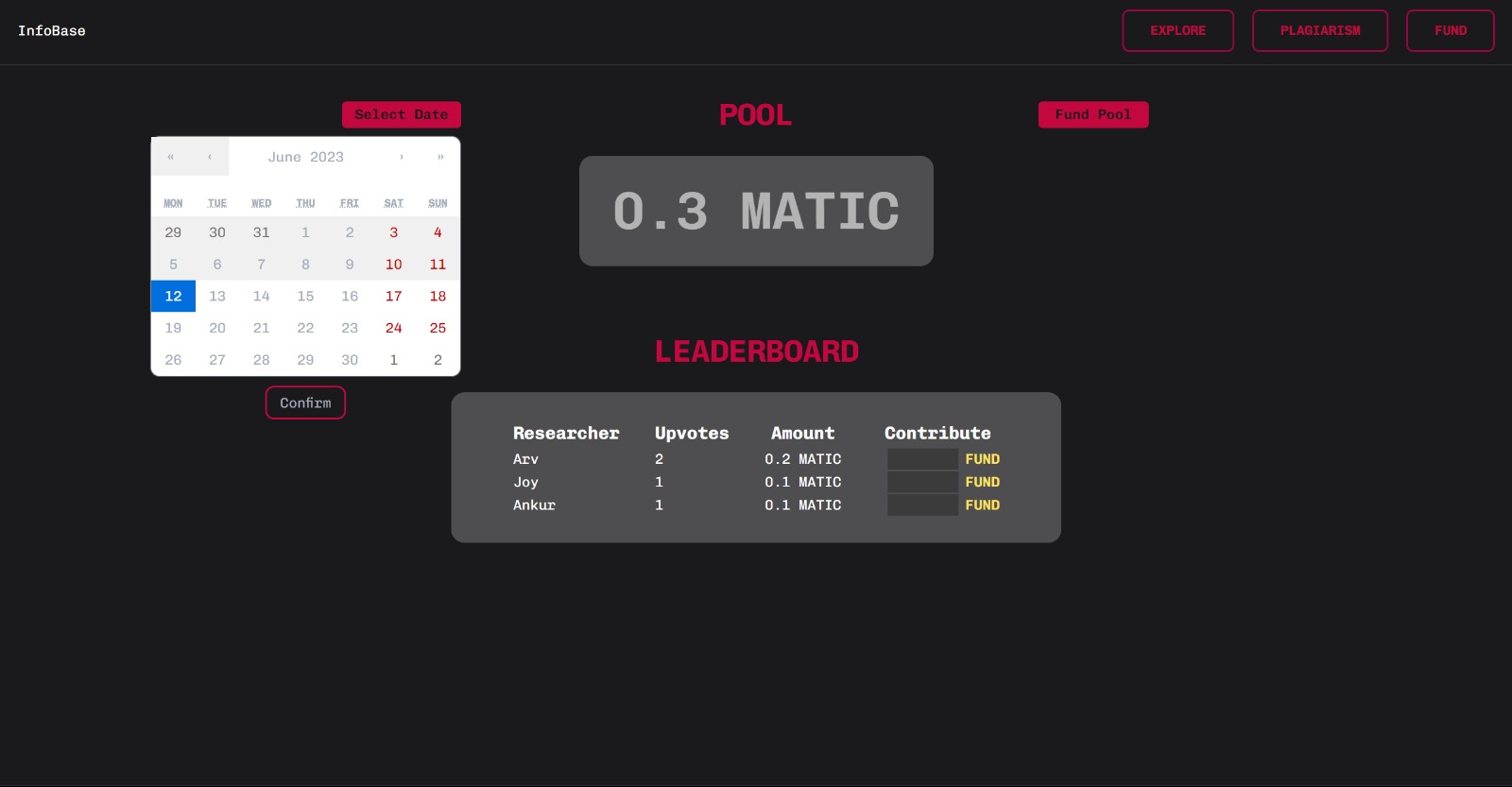
Quadratic funding for fair distribution of funds
-
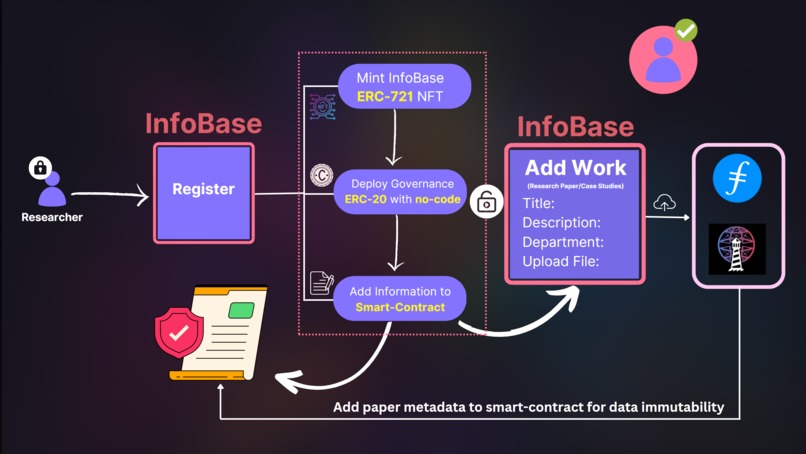
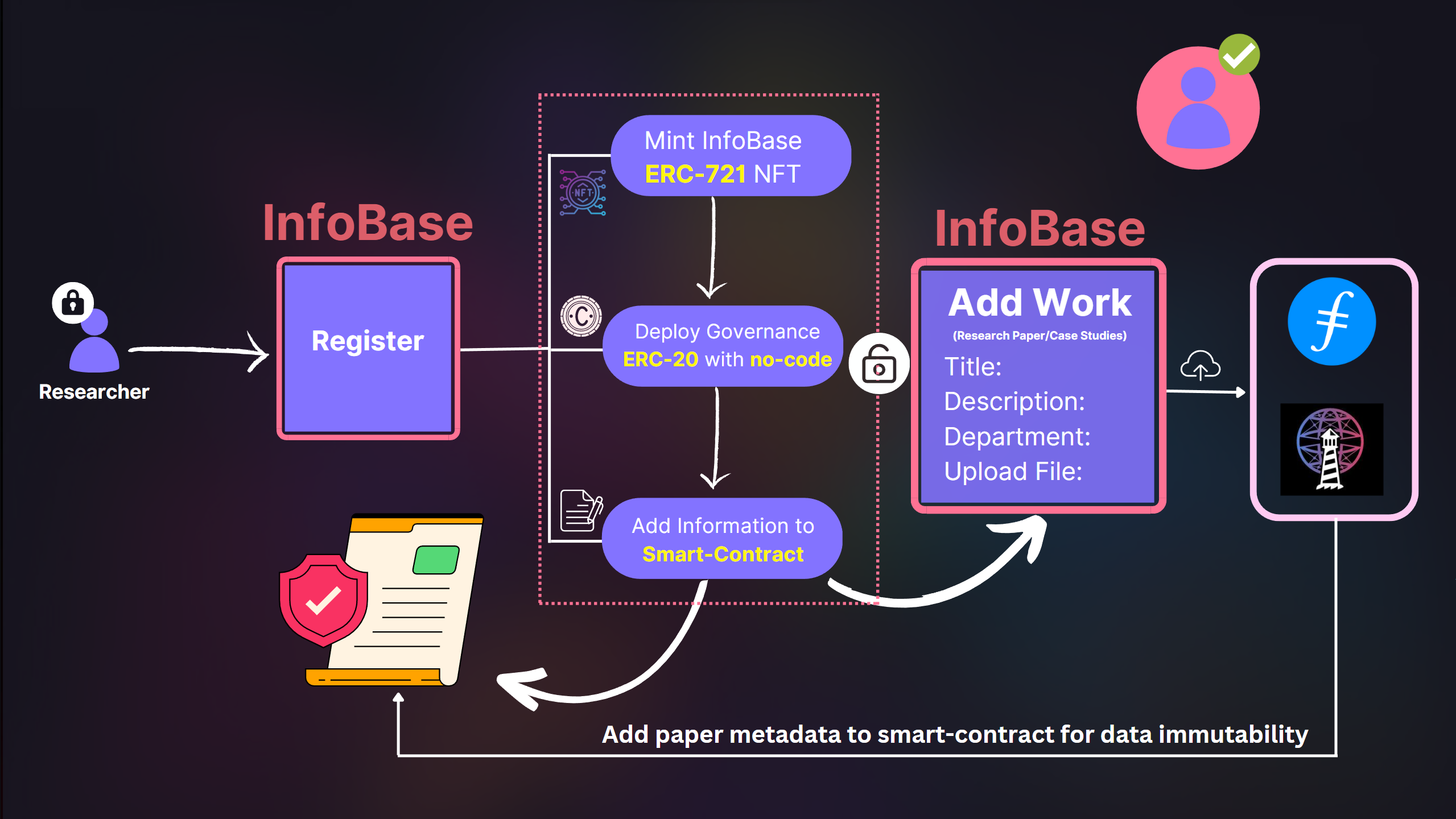
Researcher Data Flow
-
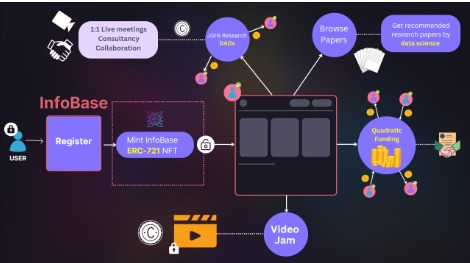
User Data Flow


Inspiration
"Young researchers are the beating heart of scientific progress, breathing life into innovation, and fueling the hopes and dreams of a better tomorrow." - Dr. Jane Goodall.
However, according to a recent article published in Nature Index, around 78% of young researchers consider a significant career change because of job insecurity and lack of proper funding.
There are many problems with how research funding agencies currently operate. Academic researchers might not receive funding because of gender, affiliation, or ethnic biases. In addition, this decision-making is an expensive process. Hence, there is no systematic funding process to ensure fair distribution of the funds as big parties tend to influence the result.
We also firmly believe that by ensuring that research findings are available to the underprivileged, we can break down the walls of inequality, sparking a transformative journey toward a more equitable society. By providing translations, summaries, or audio versions of research findings in multiple languages, we can bridge the language gap and ensure that underprivileged individuals have equal opportunities to access and understand valuable research.
More than three-quarters of scientific papers today are published in English—and in some fields it is more than 90 percent, according to data compiled by Scott Montgomery in his book “Does Science Need a Global Language?”.
Moreover, we conducted a survey among our college mates and esteemed professors, and the majority enthusiastically agreed that a decentralized science platform would empower them in unimaginable ways, unlocking boundless potential for collaboration, accessibility, and innovation. Their overwhelming support speaks volumes about the transformative impact a decentralized science platform can have on research and academia. Therefore, we present a solution through web3 and machine learning tech stack — INFOBASE
What it does
1. Quadratic Funding: Researchers can openly share and receive credit for their research through DAOs and quadratic funding. It ensures fair distribution of funds without being influenced by big investors and projects. It majorly relies on the public interest and sentiments which ensures that the funding is not biased. In addition, our platform allows researchers and users to build DAOs around their interest and earn through NFT subscriptions. A no-code token deployment system is provided in our app to ensure seamless user experience. Researchers with quadratic funding, can also earn from pay for view contents (like interaction by someone who wishes to collaborate with them).
2. Multi-language auditory comprehension: A sequential approach is employed by using Natural Language Processing to extract relevant information from a PDF document, involving the meticulous extraction of the abstract section, subsequent cleansing and normalization of the textual data, and the utilization of the Latent Dirichlet Allocation (LDA) algorithm to derive a finely tuned weighted dictionary of words which are of most importance in the paper. This analysis is used for similarity index and analytics for the research papers to facilitate recommendations. Also, the seamless translation of the findings into an audio experience in multiple languages using the gTTS engine bridges the gap between textual analysis and auditory comprehension.
3. Related research paper suggestion: The LDA algorithm helps us identify the important concepts discussed in the research paper. The weighted dictionary generated for each research paper can be converted to vectors and used to make comparisons. For this, we have generated a cosine similarity matrix. This matrix identifies the most similar research papers and helps in suggesting them to the researchers. We plan to generate ZK-proofs for the paper as a part of future prospects.
4. LLM-based plagiarism moderator: Harnessing the power of LLMs (Large Language Models) opens up remarkable possibilities for detecting plagiarism and intellectual property (IP) fraud. With their vast language understanding and contextual knowledge, LLMs can analyze text similarities and identify instances where original work has been unlawfully copied or appropriated. By utilizing an LLM, we can compare a given text with a vast corpus of existing literature, flagging potential matches and similarities. This enables us to uncover cases of plagiarism or IP fraud, providing an invaluable tool for maintaining academic integrity and protecting intellectual property rights.
How we built it
1. Research Paper Analysis (suggesting similar research papers):
a) We parse the pdf using PyPDF2 library and convert the pdf into text. The code uses the gensim library to remove stopwords. Lemmatization is performed to obtain the base or dictionary form of each word, ensuring consistency and reducing word variation. The code uses the WordNetLemmatizer from the NLTK library to lemmatize each word in the text list. Additionally, a function is defined to determine the appropriate WordNet part-of-speech (POS) tag for each word. This tagging helps the lemmatizer determine the correct lemma.
b) The code proceeds to perform topic modeling using Latent Dirichlet Allocation (LDA). LDA is a probabilistic model that assigns topics to each document based on the distribution of words in the corpus.
c) We then create a weighted dictionary which is used to compare the research papers based on cosine similarity.
2. Auditory Comprehension: We parse the pdf using PyPDF2 library and search for the abstract/introduction part of the research paper. We then clean the text and combine it with the top suggestions from the weighted topic dictionary. Lastly, we use the gTTS (Google Text-to-Speech) library to convert the text into an audio file. The resulting audio file is saved as an MP3 file. Additionally, the code utilizes the pyttsx3 library to initialize a text-to-speech engine. The engine properties are set, such as speech rate and volume, and the string is converted to speech in multiple languages by translation through googletrans library.
3. Plagiarism detection: It involves the initial step of parsing a PDF document and extracting the conclusion section from it. Subsequently, a chatbot powered by the GPT-3.5 language model (LLM) is used, wherein the conclusions are presented as strings. These strings are then compared against an extensive corpus of pre-existing literature, aiming to identify potential matches and similarities. In case any matches or similarities are found, they are flagged as potential instances of plagiarism.
4. Blockchain: Blockchain technology have empowered individuals to play in fair terms and is the roots of our application:
i. On-chain Quadratic funding mechanism with custom date picker ensures that there is no involvement of any 3rd party or bigger organizations' involvement. The funds are dispersed as per peer review and sentiments.
ii. We upload all the research papers in the IPFS and map it to the user in smart-contracts to ensure seamless copyright process without taking a single extra step.
iii. DAO creation with absolutely 0 code that will make community management and onboarding process of the new users seamless without any prior tech knowledge. Researchers can have on-chain voting and community decisions with DATA DAOs and collaborations.
iv. Incentivized peer-to-peer review system to incentivize any fair contribution to the learning community to allow users to create passive income along with their regular work. An system to motivate a better and elevated learning ecosystem.
v. On-chain reputation and voting mechanism to help users reach a better audience and recognition.
5. Chainlink: Chainlink was responsible for 4 major reasons in Infobase to make it an appealing product.
i. Price Feed: We use the price feed from Chainlink oracles to get real-time price data for Matic to USD to ensure the payouts to the users are updated with the latest market value and not get influenced by the market.
ii. Chainlink Functions: Mathematics behind quadratic funding is quite heavy and intense and therefore we planned to take the calculations off-chain keeping it secure from any other sort of tampering. We implemented this functionality in our smart contract but was unable to run a successful test because our wallet did not get whitelisted to do so. THEREFORE, CHAINLINK TEAM PLEASE LOOK INTO IT.
iii. Chainlink Automation: Chainlink Keepers helped us automate our smart contracts in Quadrating funding. Admin can choose the duration of funding and allow users to fund their fav researcher. When the duration end, funds are automatically dispersed to the respective researcher.
Challenges we ran into
1. Timing and availability were among the most pertinent challenges.
2. We had some library dependency challenges within Python as many of them are involved. However, through troubleshooting, we were able to resolve them.
3. It was challenging to extract the necessary information from the PDF and generate a valid string. For example, whenever there was a line change in the PDF, a new line character was introduced in the string.
4. Converting the text-based results into an audio format involved integrating text-to-speech libraries and addressing potential issues such as speech rate, the naturalness of voice, and handling longer text inputs.
Accomplishments that we're proud of
1. We are proud of proposing a solution that deals with the educational aspects that have to be dealt by the society. After the prototype was ready we went for a market survey for our target audience and they seem to love the product and showed real interest in it. Our college community has also approved the prototype which makes us immensely happy and proud.
2. We implemented Quadratic funding, that can remove the biasness in funding process and ensures fair distribution.
3. By employing LDA and carefully tuning its parameters, We achieved accurate topic modeling and successfully identified relevant topics within the corpus of text.
4. We were successfully able to create a product that showcases our proposed solution.
What we learned
1. We had the idea to solve the problem but had vague clarity about technical implementation.
2. We expanded our understanding of natural language processing (NLP) techniques such as lemmatization, part-of-speech tagging, and stopword removal, which are crucial for improving the accuracy and semantic understanding of text data.
3. We had to explore text-to-speech conversion techniques and learned how to generate audio output from textual data, including aspects such as adjusting speech rate and volume for a better user experience.
What's next for InfoBase
1. We can store ZK-Proofs of research papers so that the findings can be revealed at the will of the researcher.
2. The integration of voice assistants and smart IOT devices may enable real-time text analysis and audio output, making information consumption more seamless and inclusive.
3. Other future prospects lie in enhanced natural language processing techniques, including advanced topic modeling algorithms and deep learning architectures.




Log in or sign up for Devpost to join the conversation.