-
-
INEVitable — Where Google Maps ends, Inevi begins. Multi-agent spatial AI with six specialized agents.
-
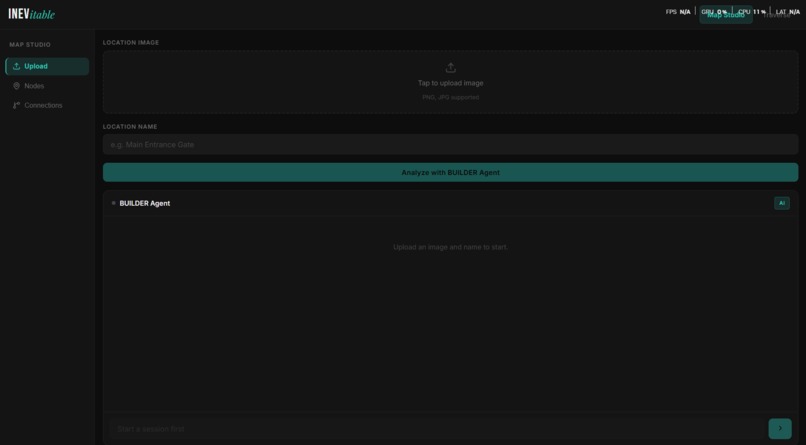
Map Studio — Upload a location photo and let the BUILDER agent analyze and extract visual keywords automatically.
-
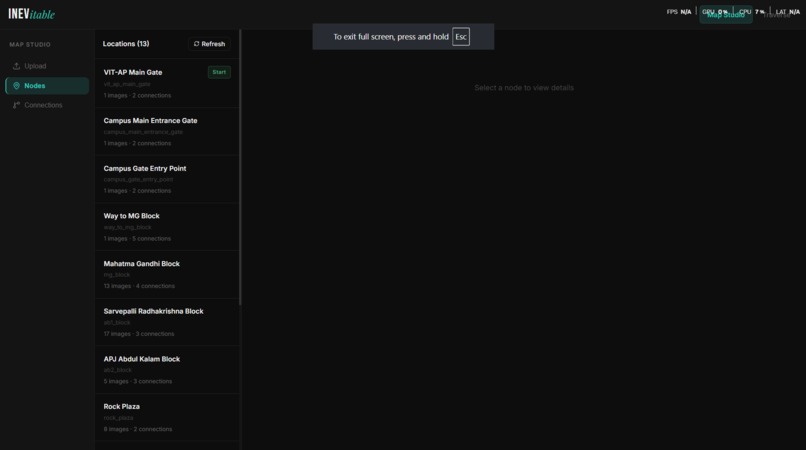
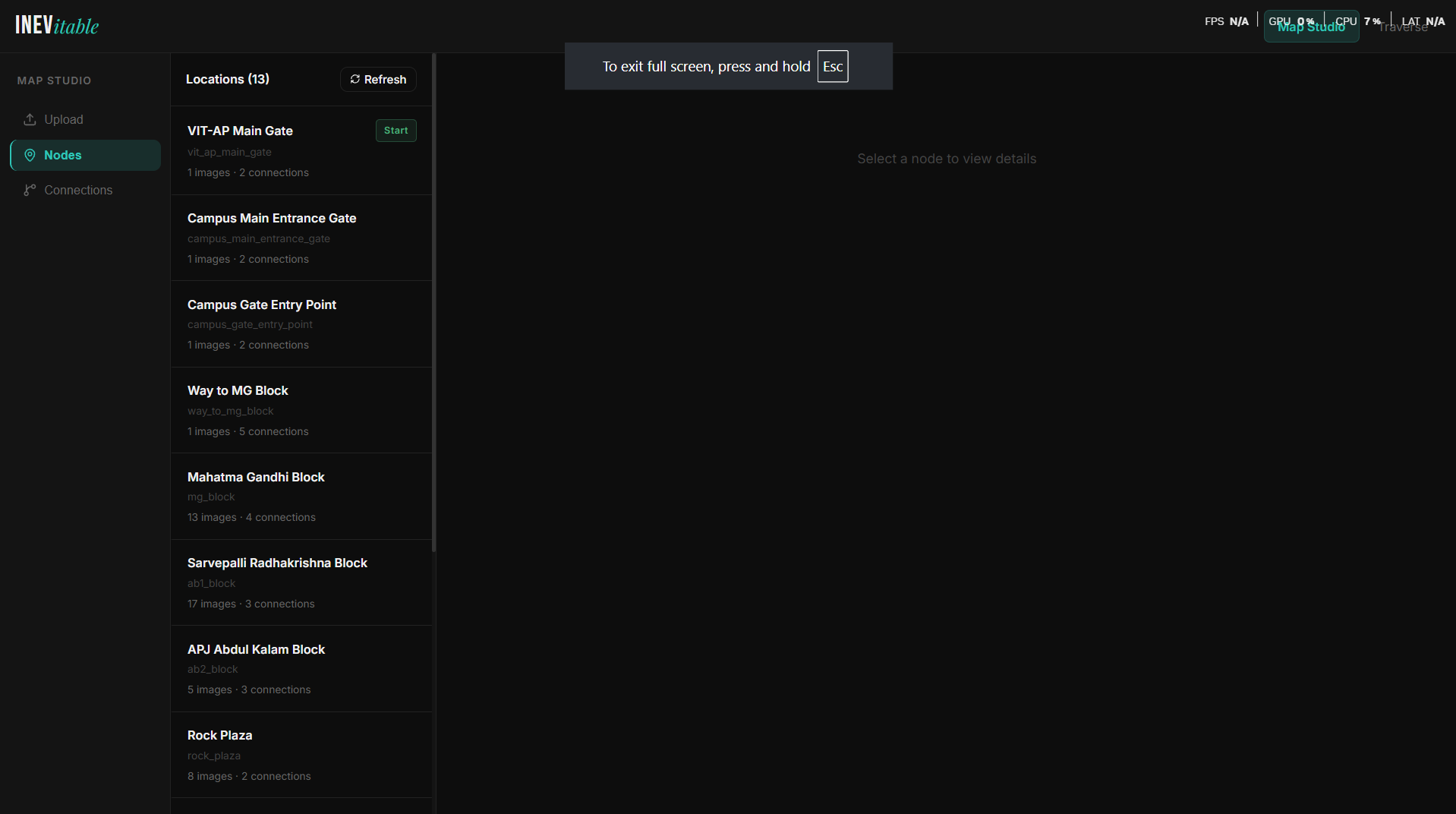
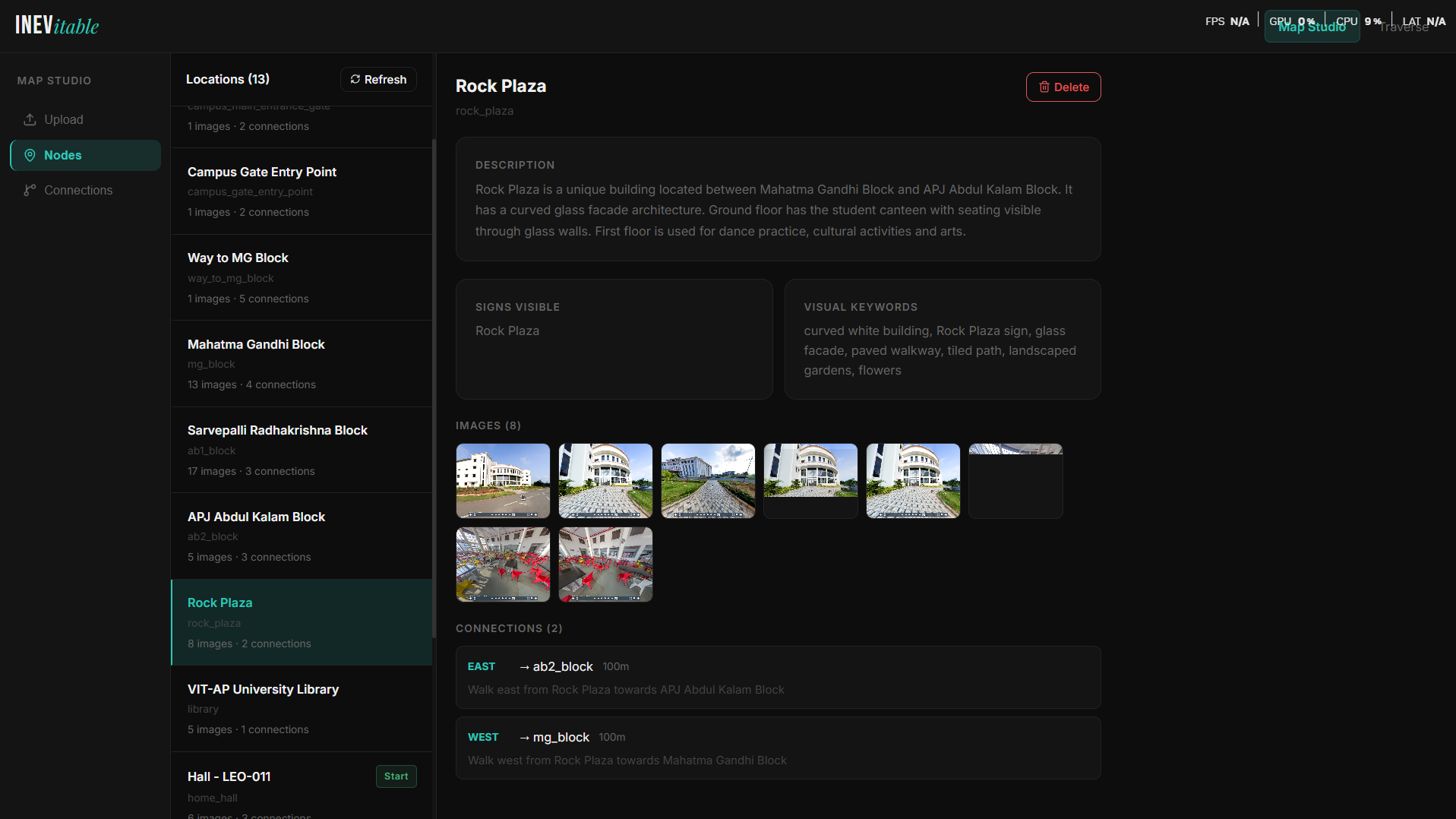
13 locations mapped across VIT-AP University campus — each node stores images, connections, and visual metadata.
-
13 locations mapped across VIT-AP University campus — each node stores images, connections, and visual metadata.
-
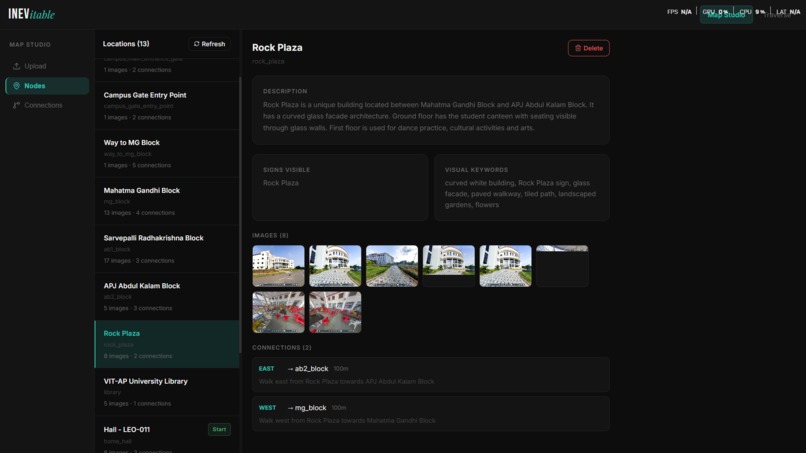
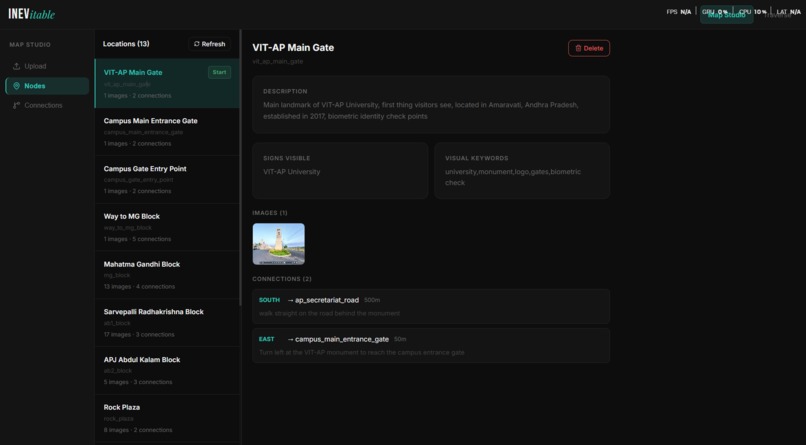
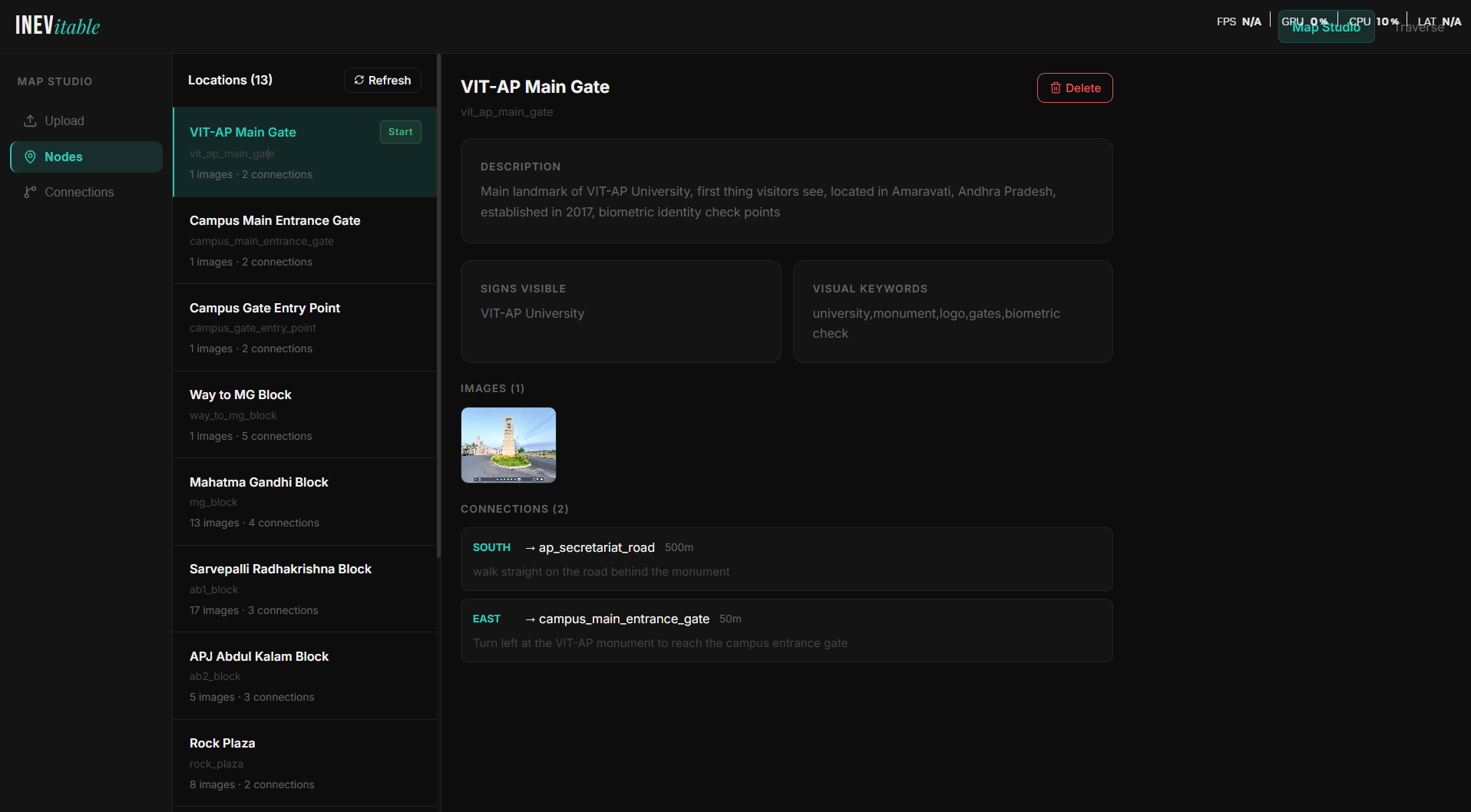
VIT-AP Main Gate node — description, visible signs, visual keywords, reference images, and directional connections.
-
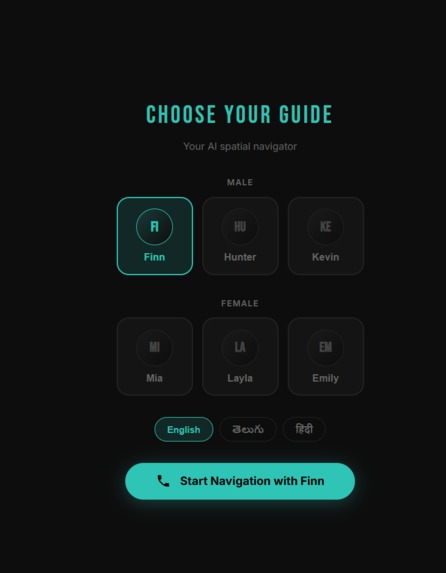
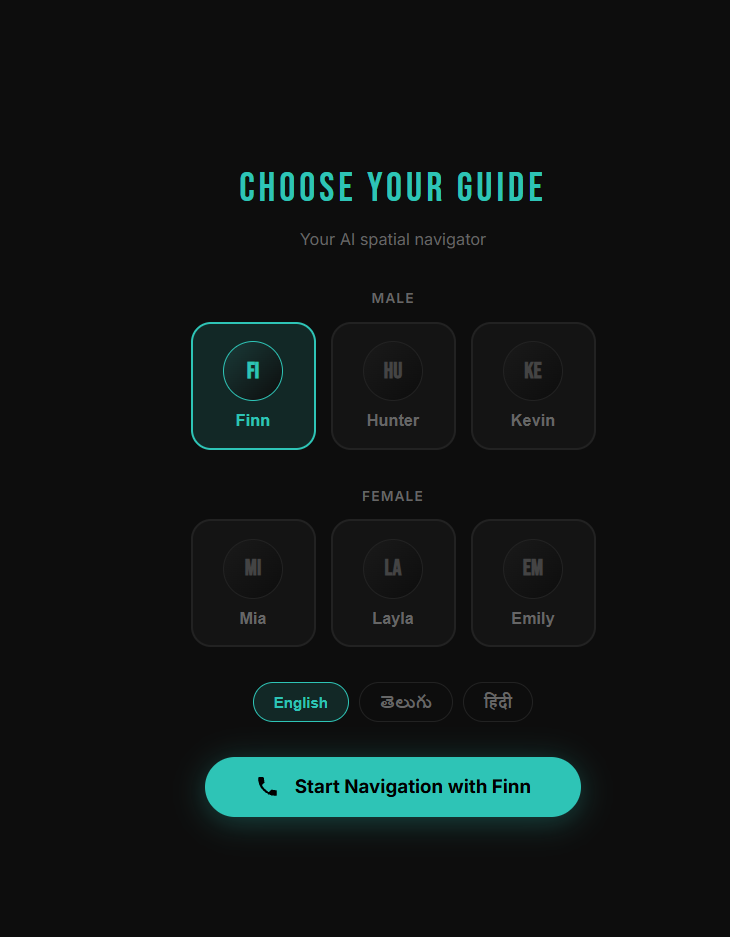
Choose Your Guide — Six AI avatars available. Multilingual support — English, Telugu, Hindi.
-
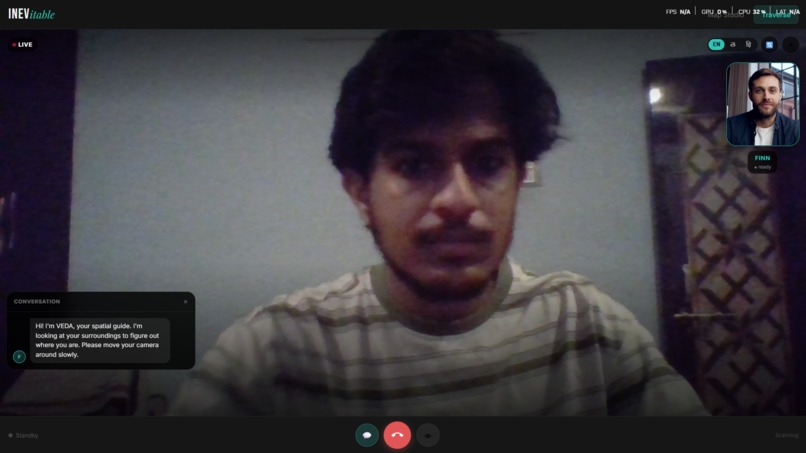
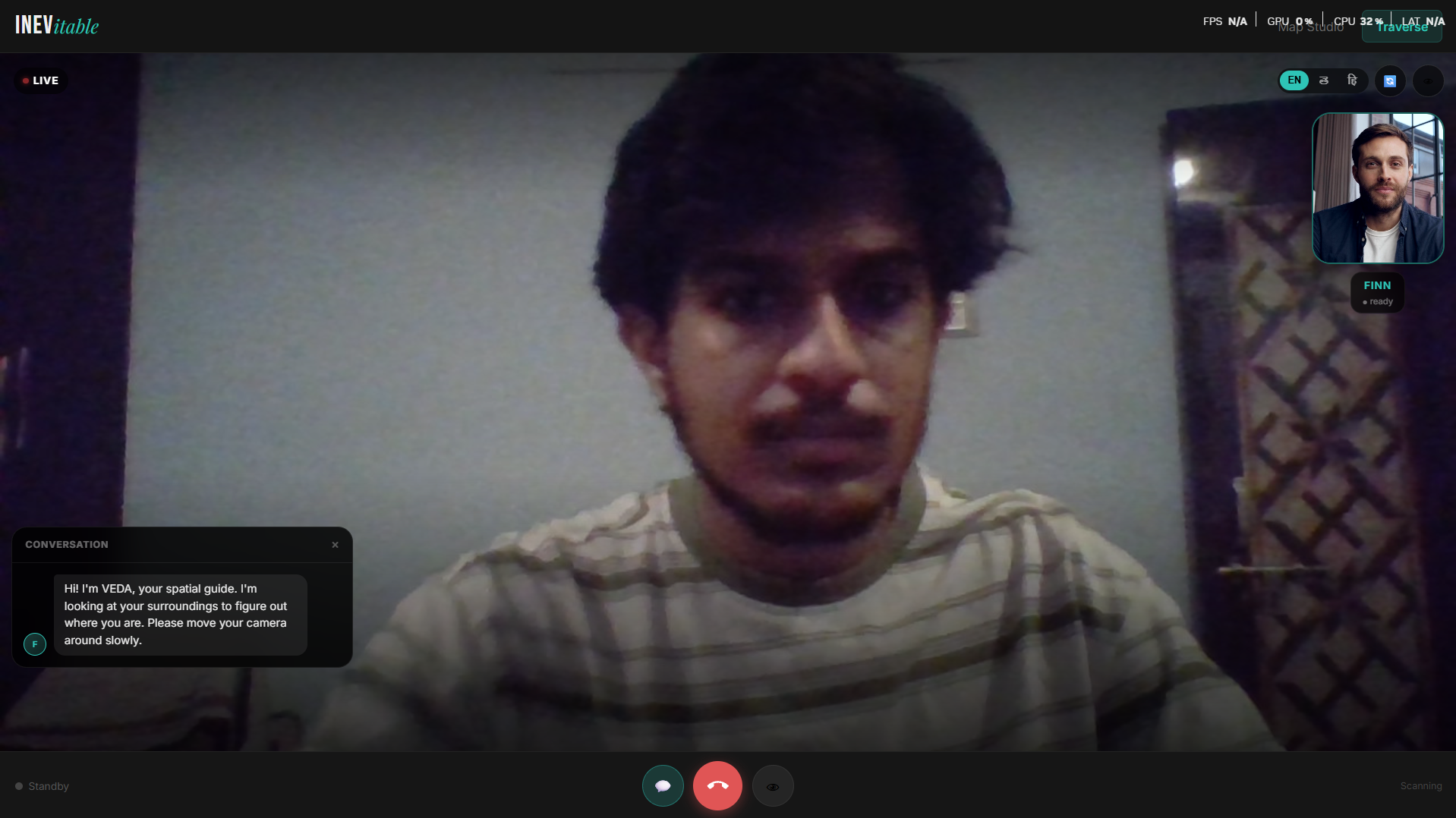
Traverse — A live video call with Finn, the AI guide. VEDA speaks navigation instructions in real time.
Inspiration
I study at VIT-AP University — 30,000 students, dozens of departments, and a layout that confuses everyone on their first day. Freshers miss exams because they cannot find the right block. I missed places myself that I only discovered months later.
I kept thinking: when we are stuck, we call someone. They see what we see, tell us where to go, we follow. What if that someone was an AI?
No beacons. No QR codes. Just your phone and a live AI that has already learned the building. That thought became Inevi.
What it does
Inevi is a live AI navigation call. Open the app, choose your guide, start the call. Point your camera — the AI sees what you see, figures out where you are, and talks you through every step to your destination in English, Telugu, or Hindi.
Space owners use Map Studio to map their building once. Upload photos, describe locations, connect the spaces. Anyone who visits can then call the AI and get guided — no hardware, no maintenance.
Six agents work together in real time — IRIS sees the frame, LOKI finds your location, SAGE identifies your destination, NOVA plans the path, VEDA speaks the response, BUILDER helps you map new spaces.
How we built it
We built Inevi over two weeks as a two-person team using a multi-agent architecture where each agent has one job and does it well.
Six AI agents, one orchestrator:
IRIS uses Groq Llama 4 Scout Vision to analyze every camera frame and produce two outputs — a background description for location matching and a scene description for conversation context.
LOKI takes the background description and compares it against reference images stored in S3, using visual keywords, signs, and spatial features to identify the user's current location with a confidence score.
SAGE handles knowledge retrieval. When the user says a destination, SAGE runs a similarity search across all locations in the knowledge graph — scoring by word overlap, then passing the top candidates to an LLM for final confirmation.
NOVA calculates the route using BFS graph traversal through Aurora DSQL, which stores every location as a node and every walkable path as an edge with direction and instruction.
VEDA generates the final spoken response in English, Telugu, or Hindi — one or two natural sentences, like a real guide would say.
BUILDER powers Map Studio — a conversational interface where you upload a photo, name the location, and answer questions. It extracts visual keywords, signs, and facts automatically to build the knowledge graph.
AWS Infrastructure: Aurora DSQL stores the spatial knowledge graph. DynamoDB manages live navigation sessions with an in-memory cache so the frame pipeline and speech pipeline never conflict. S3 stores all location reference images as public URLs for visual comparison.
Challenges we ran into
Coordinating six agents in real time without state conflicts was the hardest part — solved with an in-memory session cache on top of DynamoDB. Frame stacking was next — a processing lock drops new frames while one is already in flight. Getting the avatar to speak only VEDA's words required an idle guard that continuously interrupts the avatar's own LLM between our responses.
Accomplishments that we're proud of
85-92% location detection confidence using only a phone camera with no GPS, no beacons, and no hardware. A six-agent pipeline that coordinates vision, location matching, and multilingual speech in under 6 seconds. An experience that genuinely feels like a video call with someone who knows your building.
What we learned
The orchestrator is harder than any individual agent — six working agents can still produce a broken system if coordination is wrong. Skip LLM calls whenever possible — keyword-first detection cut our API usage in half. In real-time systems, refs beat state and memory cache beats database reads.
What's next for Inevi
The map building experience needs to go deeper — richer connections, better visual descriptions, and more contextual knowledge per location so the AI can explain spaces the way a real guide would.
GPS handoff from Google Maps — detect when the user enters a building and seamlessly switch from outdoor to indoor navigation using the nearest known location as the entry point.
AR overlay — draw directional arrows and labels directly over the live camera feed.
Add a person to the call — invite someone who knows the space to join live and guide alongside the AI.
Presentation mode — the AI leads a group through a campus, museum, or historical site with pre-planned narration and stops.
The goal is simple: make Inevi feel less like an app and more like having a knowledgeable person always on call.
Built With
- amazon-web-services
- anam-ai
- aurora
- aws-dynamodb
- dsql
- fastapi
- groq
- llama-3.3-70b
- llama-4-scout
- next.js
- postgresql
- python
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.