-
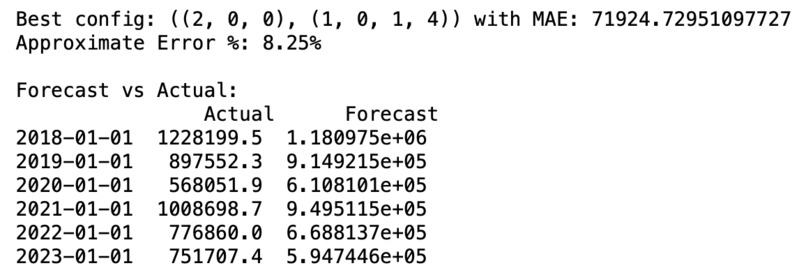
Tuned model performance
-
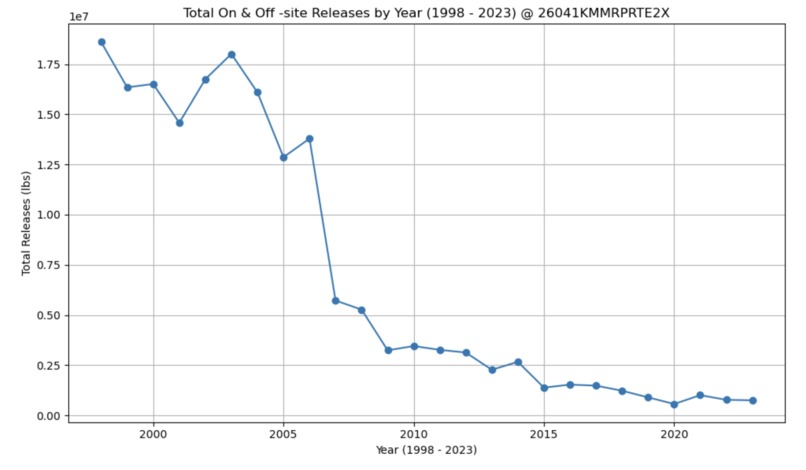
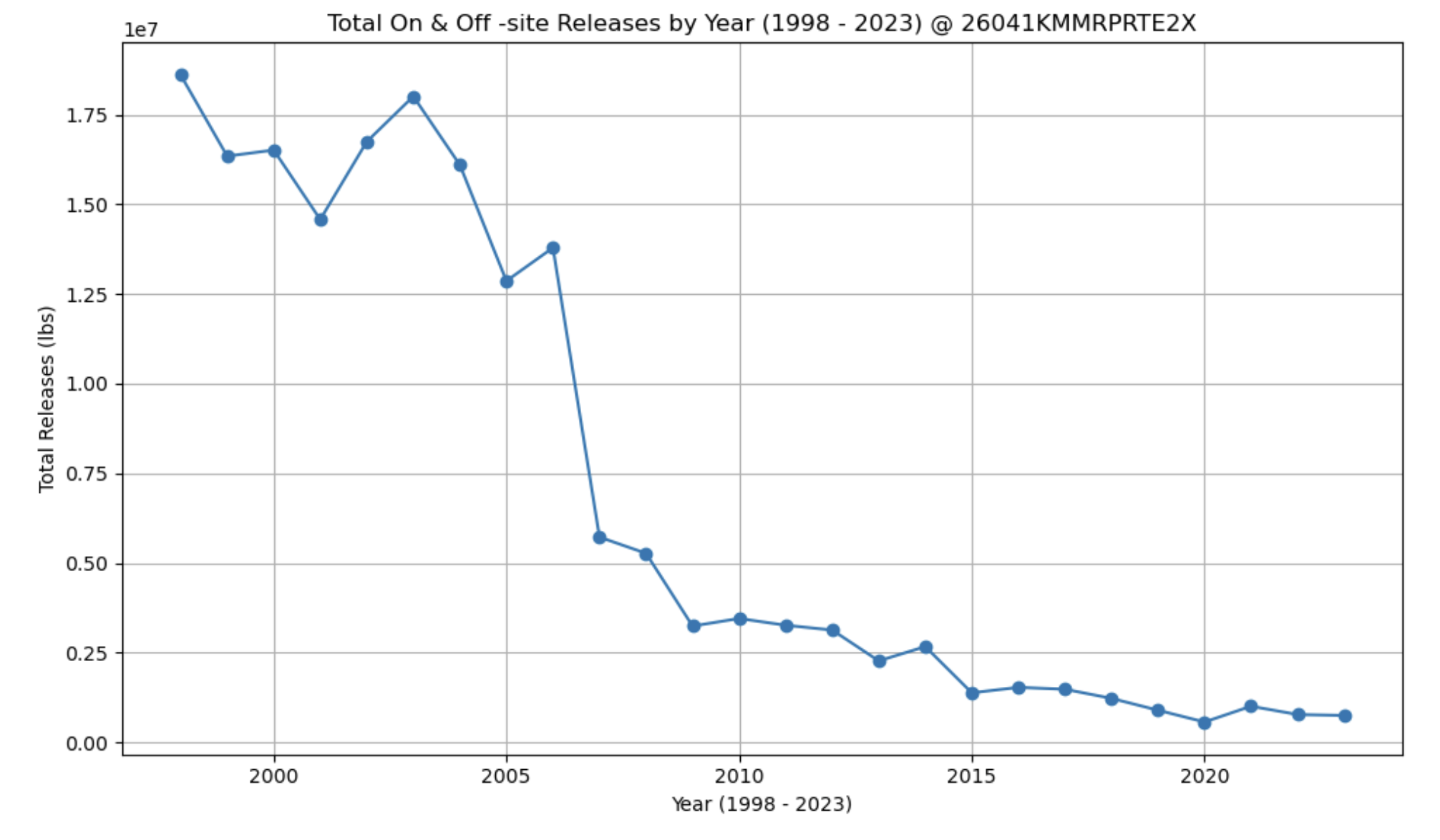
Visualizing the Dataset (Yearly trends for the given facility - Total waste releases)
-
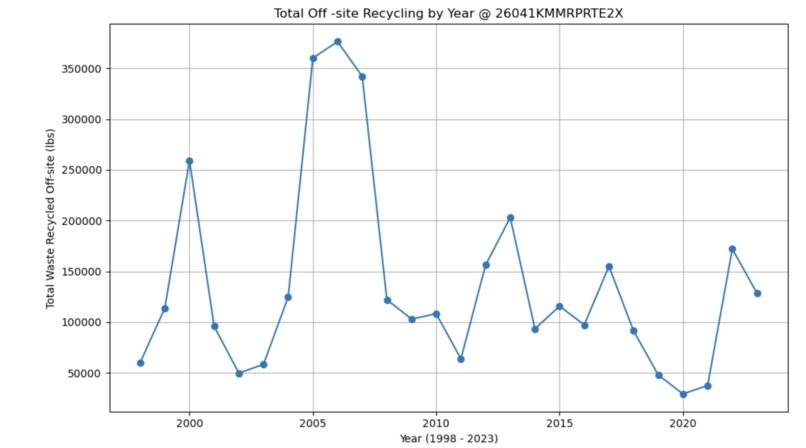
Visualizing the Dataset (Yearly trends for the given facility - Total recycling)
-
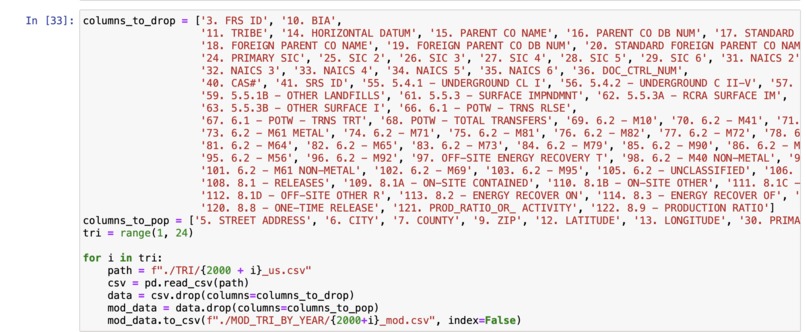
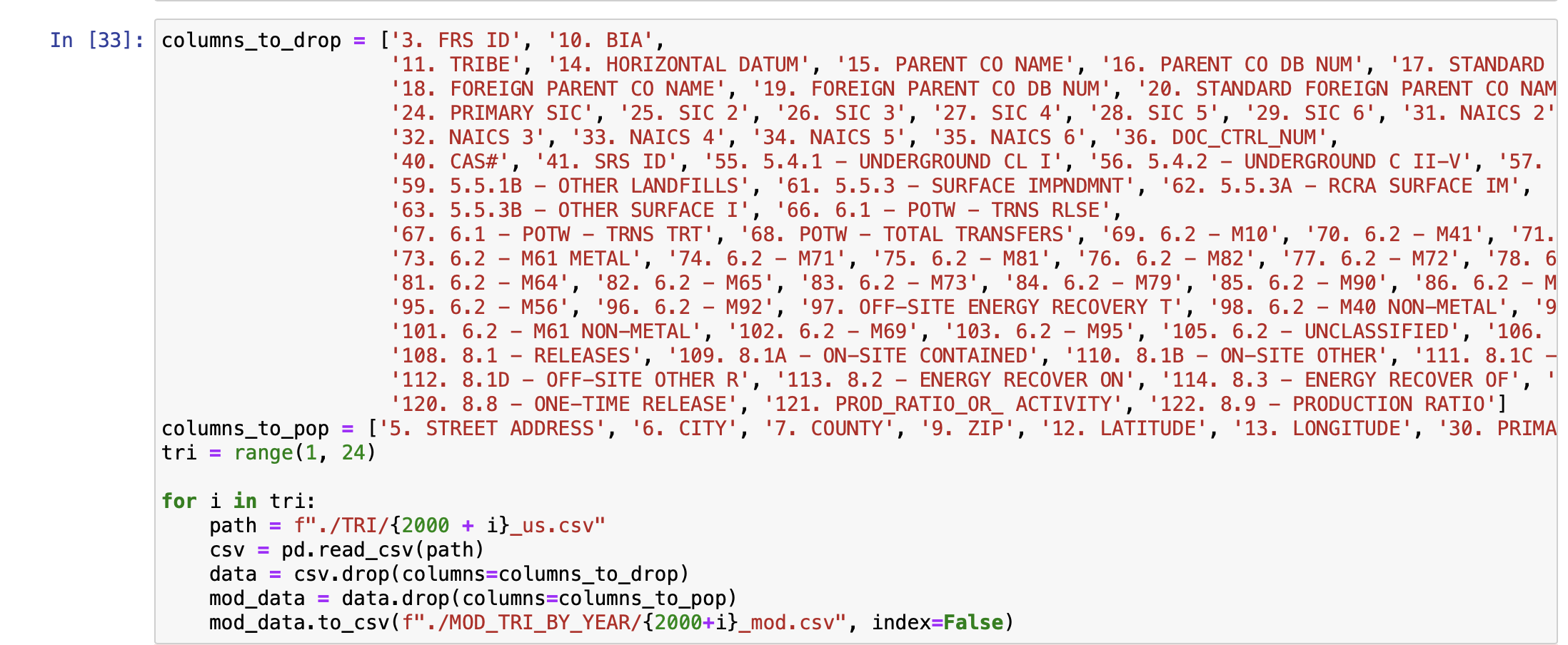
Modifying the dataset by removing columns
-
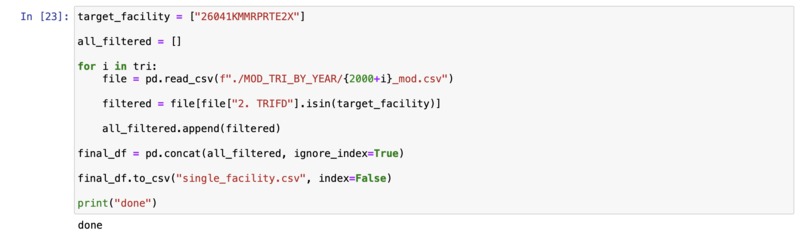
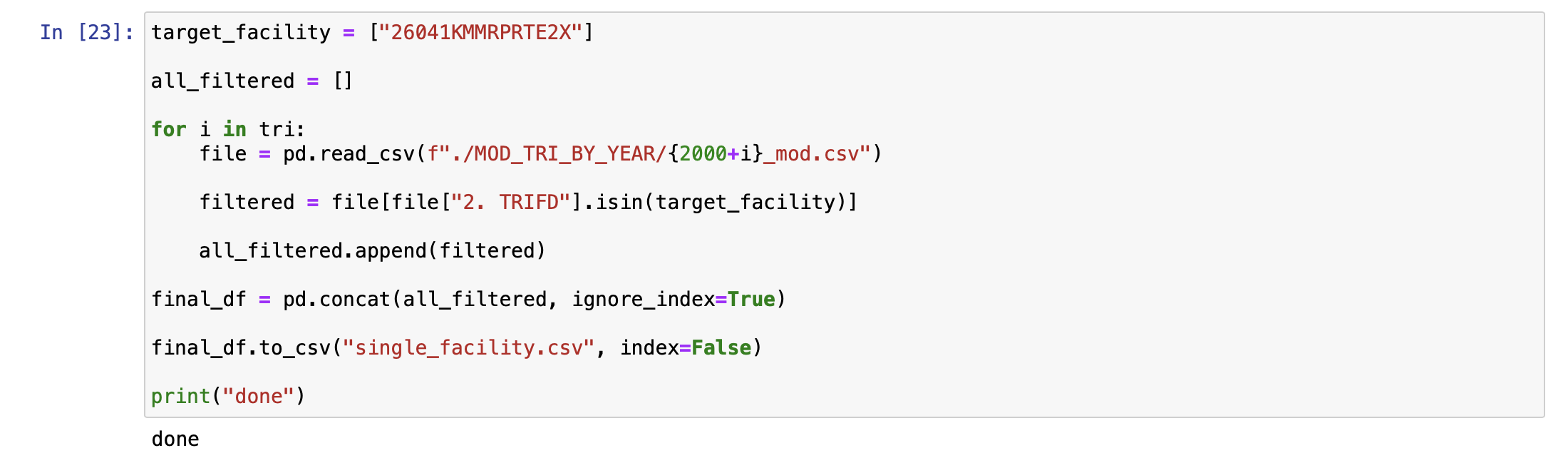
Extracting data for a target facility
-
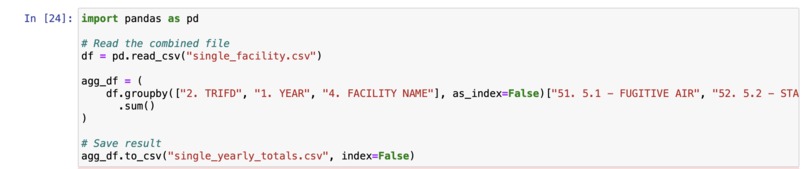
Exporting final data into csv



Inspiration
The inspiration behind this project came from an internship and apprenticeship which I had pursued a while back. In a previous summer, I interned under a professor at local university to explore ways to generate electricity through sustainable measures. This opened my eyes up to the urgency of sustainability related issues. Combining my passion of computer science and machine learning, I wanted to create some sort of app which makes use of machine learning in the sustainable technology world.
What it does
For my project, I wanted to focus on the "datathon" track and understanding the data I was modeling and predicting with. I used historical data of a single industrial facility from the EPA- Toxic release inventory. Using this historical data, I built a Seasonal Autoregressive Integrated Moving Average (SARIMA) model so that it would be able to make predictions of industrial waste totals in lbs(pounds) for future years based on previous historical trends it identifies. The Preliminary SARIMA model was not very accurate and the percentage error of the predictions against the training data set was around 20%. Following a grid search for optimization, the percentage error reduced to a mere 8% with a MAE ~ 70,000. This meant that the tuned SARIMA model was able to make predictions of total releases within industrial facilities with an error percentage of 8%. This means that the predictions were not too far off and the model can be used by facilities to employ the proper and required measures for that annual period.
How we built it
The machine learning model itself was built using python-3 in an Jupyter notebook. The process really started with the data manipulation however. I initially wanted to use the TRI as my data for the model. However, the TRI contains data from a single year and for 100,000+ facilities. I wanted to focus on a single facility so that the model could be tailored just for that given location. The first step was the remove the unwanted columns in the TRI. For this project, I only really needed the facility ID, and Release metrics. I removed the remaining columns to make the data easier to deal with. Once I had removed the unwanted columns from TRIs spanning from 1998 until 2023, I then extracted the rows which had to deal with one specific facility. With that new CSV, I added up all the totals from each year of that given facility. I was then left with a CSV which contained data from 1998-2023 with the yearly total releases of all chemicals and wastes. With the historical data now formatted and collected into one CSV, I moved forward with creating the machine learning model. I started with an Exponential Smoothing model. However, initially, this model performed poorly and the waste totals predicitons were going below 0 which was not possible. I then tried to use an ARIMA model and this performed a bit better. To tune the ARIMA model further, I turned to a SARIMA model which accounted for seasonal patterns as well. After running a grid search, I was able to identify the best p,d,q and seasonal configuration as: ((2, 0, 0), (1, 0, 1, 4)). After running a hyper tuned SARIMA model, I was able to achieve a percentage of just 8%.
Challenges we ran into
Some of the preliminary challenges I ran into was with the first models I tried to train. The Exponential Smoothing was hard to work with and was also producing negative numbers. I also ran into issues with data manipulation. TRI data is very large and it often takes a long time and a lot of computational power to parse through all the files and extract certain data frames.
Accomplishments that we're proud of
One thing that I am proud about is the extent to which I was able to manipulate the TRI data for my use. Furthermore, I am very proud about being able to reduce the accuracy to 8%. This process required trying different models : Exponential Smoothing, ARIMA and SARIMA. This process was extensive and on top of this I also had to explore different parameters to see which would be best. I am also proud of being able to run GridSearch as it was my first time doing such a thing for hyper-parameter tuning.
What we learned
By building this project, I learned a lot about data manipulation. I learned how to extract rows and columns from large csv files and export new csv files. Furthermore, I learned the most when it came to creating and building predictive models. I had never come across Exponential-Smoothing and it was interesting to see how the model works and makes its predictions.
What's next for Industrial Waste Predictor
the next steps for Industrial Waste Predictor is to increase the accuracy of the model to bring it below 5% or even 3%. I would also like to transform this into an open source app so that facilities are able to input their own historical data and are also able to see their own predictions.
Built With
- anaconda
- arima
- epa-toxic-release-inventory-(1998-2023)
- exponential-smoothing
- jupyter
- python
- sarimax

Log in or sign up for Devpost to join the conversation.