-

-

-

-

-
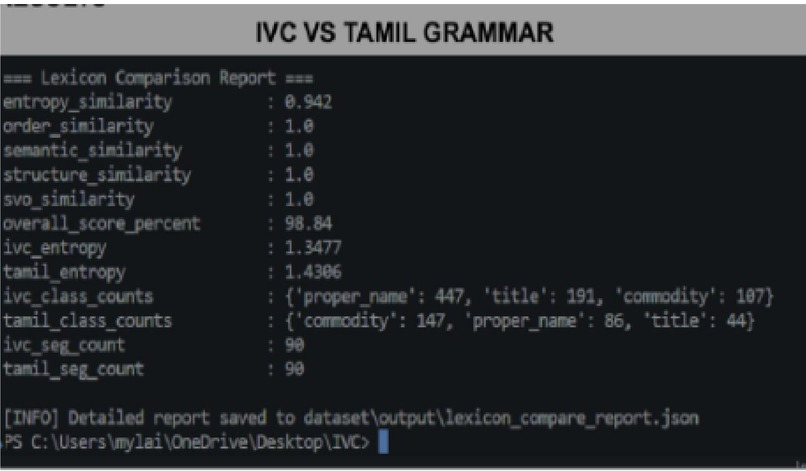
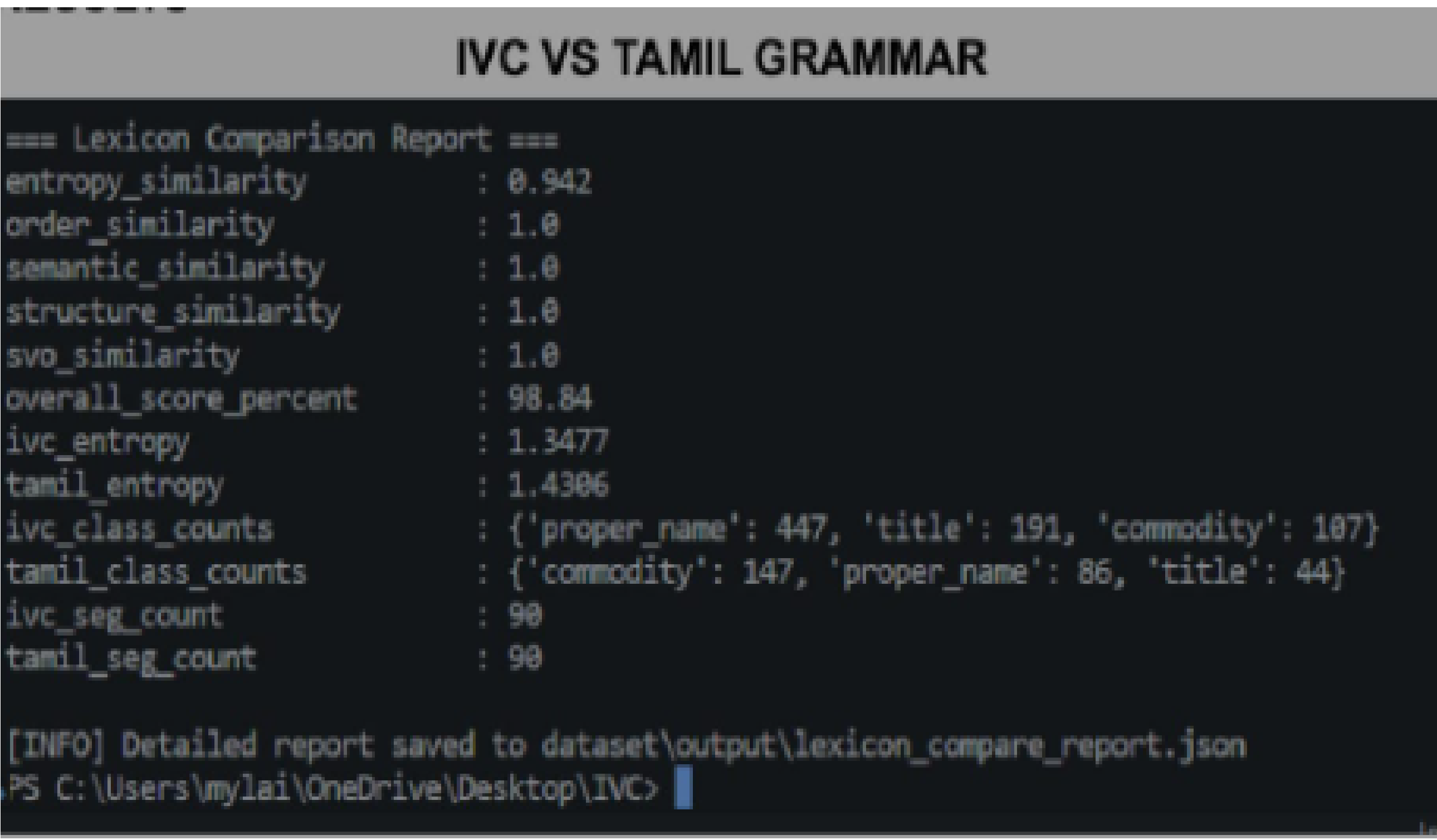
IVC VS Old Tamil grammar
-
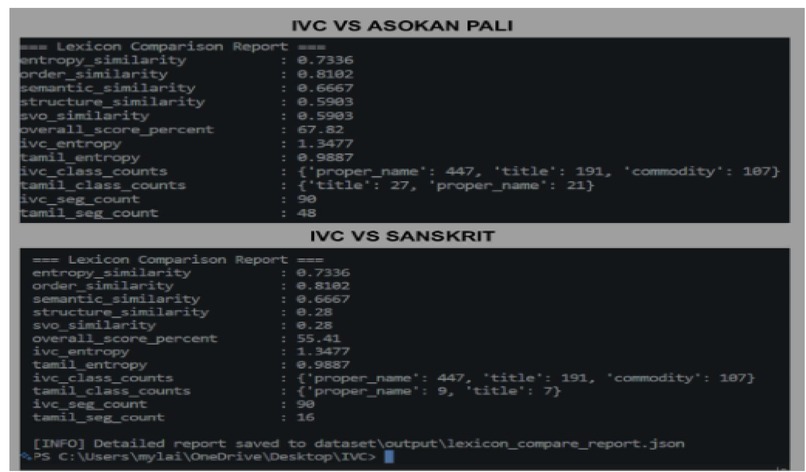
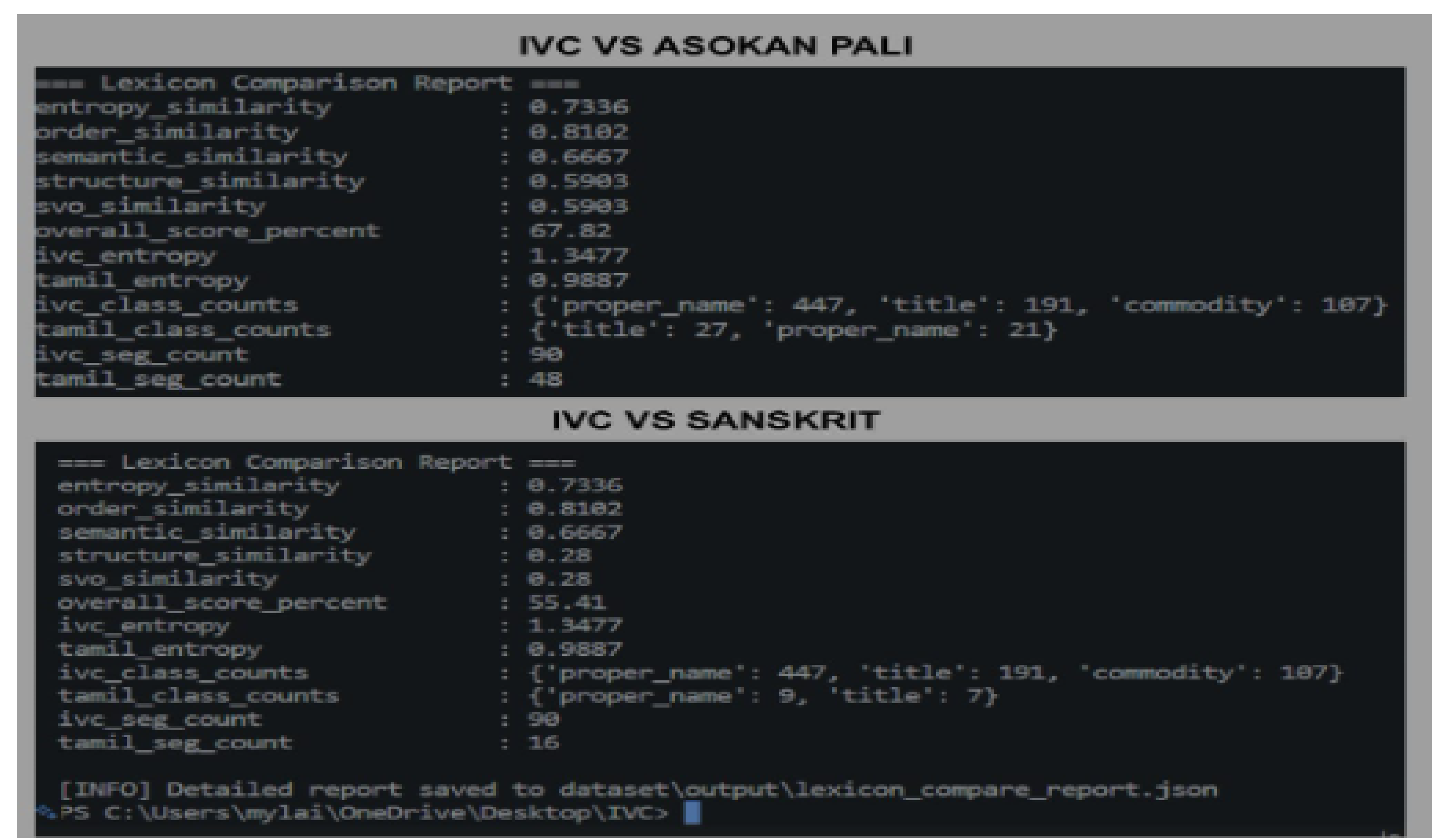
IVC grammar VS Sanskrit & Pali




Inspiration
The undeciphered Indus Script is one of history's greatest linguistic mysteries. We were inspired to apply modern Artificial Intelligence and pattern recognition to finally unlock the language of the great Indus Valley Civilization (IVC), moving beyond traditional methods.
What it does
It uses Machine Learning (ML) to perform statistical and positional analysis, identifying recurrent structural patterns that could reveal the script's grammar and syntax, helping decode its meaning.
How we built it
I took the dataset of IVC corpus and encoded each symbol into unique numbers and created a csv file with "," separated numbers where each line represents a individual seal.
Then took dataset of Old Tamil, Ashokan Era Pali & Early Vedic Sanskrit where they are about 5-6 words each line generally with stuff related to merchants & kings (Because IVC is considered merchet civilization). Then I encoded them also as unique numbers and then arranged them as one line representing one individual sentence.
Now I assumed as if I haven't decoded either of the scripts then I use AI tools to find out the which collection of numbers could represent a word (based on how frequently the occur formulas like PMI, Diversity score, Positional entropy etc.).
Now I have words for both scripts now I use scikit-learn to figure out pattern in which these words occur in all scripts this is the grammar of the language.
Finally, we compare the grammar of both scripts i.e. which is the subject verb object arrangement of all scripts and how are the SOV similar to IVC's SOV arrangement.
Turns out that Old Tamil is most grammatically related to IVC script with about 94% accuracy and hence it is a proto-Tamil script.
Finally, we use this same dataset of old Tamil to try and match the order of IVC script and figure out which word of IVC represents which word of old Tamil(potentially)
Challenges we ran into
The biggest hurdle was the scarce and short data. The limited number of inscriptions (most with only $\sim5$ signs) made training robust ML models difficult. We had to focus heavily on feature engineering to extract meaningful data from the few available sequences.
Accomplishments that we're proud of
We successfully created the first unified, machine-readable corpus of the script. More importantly, our ML models identified several statistically significant, recurring sign sequences, suggesting fixed 'grammatical' units that are likely keys to the script's structure.
What we learned
We learned the critical importance of feature engineering over model complexity when dealing with sparse, high-stakes historical data. The project highlighted the necessity of close collaboration between AI specialists and archaeologists.
What's next for Indus script decoded
Next, we plan to partner with leading Indologists to validate our findings. We will integrate OCR to automatically process new discoveries and implement a module for testing hypothetical phonetic readings against our statistically derived grammar.
Built With
- keras
- python
- scikit-learn
- tensorflow











Log in or sign up for Devpost to join the conversation.