-
GeoRisk
Inspiration
We were inspired by the growing complexity of global regulations and the challenge analysts face in making sense of thousands of pages of evolving legal and financial texts. With the rise of AI language models and cloud-native architectures, we saw an opportunity to transform compliance from a manual, reactive task into a proactive, data-driven process. The goal was to empower analysts, compliance officers, and financial institutions with automation that understands multiple languages and regulatory nuances.
What it does
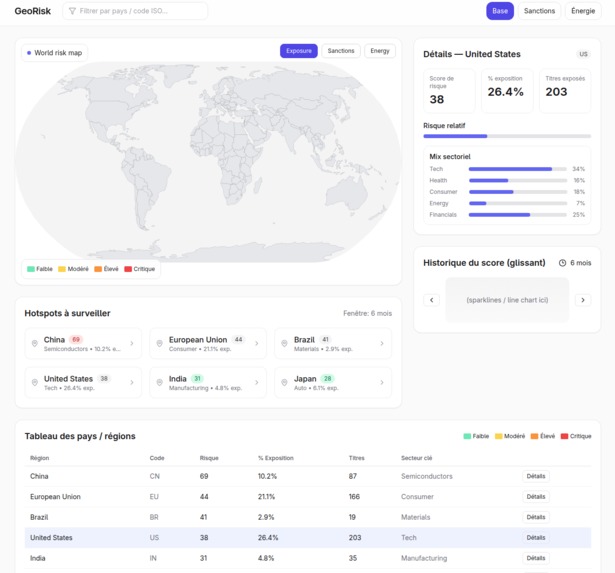
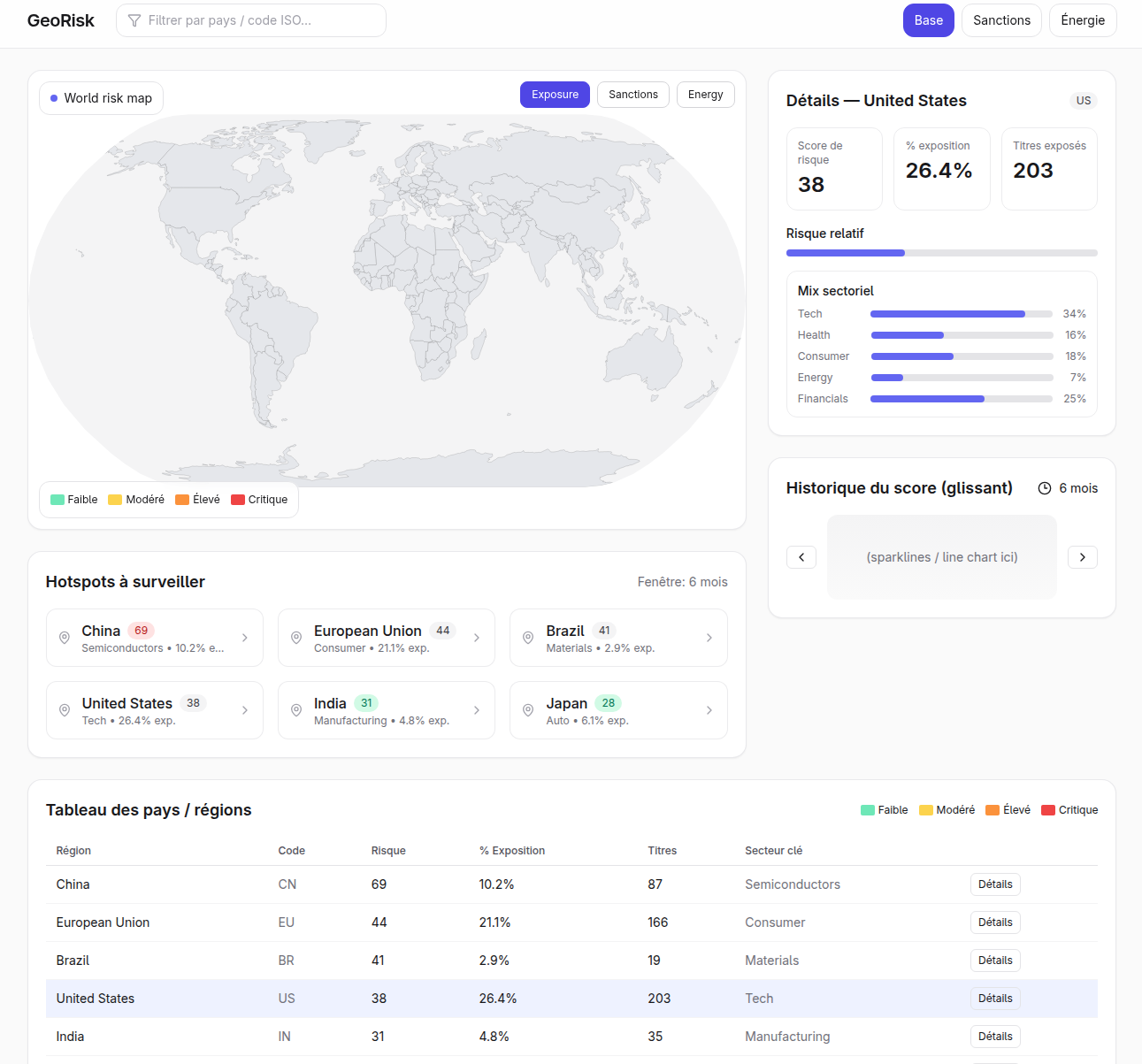
Indorex AI automates multilingual regulatory analysis for the S&P 500. It ingests laws, directives, and regulatory documents in any language, detects and translates them, extracts the entities, obligations, sectors, and dates involved, and links them to affected companies in the index. The result is a dynamic dashboard showing how new regulations impact each firm, complete with summaries, timelines, and compliance risk indicators, all generated automatically.
How we built it
We built Indorex AI as a modular, agent-based system on AWS Bedrock:
Amazon Comprehend detects the source language and performs entity recognition.
Amazon Translate converts all texts into standardized French for uniform processing.
Claude 3.5 Sonnet (via Bedrock) performs deep semantic extraction of regulatory clauses, identifying obligations, sanctions, and effective dates.
Aurora PostgreSQL and OpenSearch store and classify extracted data by sector, country, and entity.
QuickSight and Streamlit handle visualization and reporting.
An orchestrator built with AWS Step Functions coordinates the specialized agents: linguistic, regulatory, financial, and analytical.
Challenges we ran into
Multilingual precision: Maintaining extraction accuracy across English, French, Mandarin, and Japanese required iterative fine-tuning and prompt engineering.
Legal text ambiguity: Many clauses are context-dependent or reference other laws; we had to design hierarchical parsing to preserve meaning.
Scalability: Parsing hundreds of documents simultaneously demanded optimization in Bedrock API calls and database indexing.
Alignment between AI outputs and financial data: Matching regulatory impacts to the right S&P 500 tickers required entity disambiguation and custom rules.
Accomplishments that we’re proud of
Reduced average analysis time per report from 30 hours to 12 hours, a 60% improvement.
Created a multilingual pipeline that operates seamlessly in four languages.
Built a scalable architecture entirely serverless on AWS.
Developed specialized agents that collaborate autonomously to deliver human-grade reports.
Demonstrated the system on real EU, US, and APAC regulatory documents with high accuracy.
What we learned
We learned that regulatory language can be structured, but not uniform, AI must adapt dynamically rather than rely on static templates. We also realized the importance of data provenance and transparency: analysts trust AI insights only when they can trace them back to the source text. Finally, building on cloud-native AI platforms allowed us to experiment quickly while maintaining compliance-grade security.
What’s next for Indorex AI
Next, we plan to:
Extend coverage to ESG and cybersecurity regulations.
Integrate predictive analytics to anticipate which sectors will be most affected by upcoming laws.
Launch a Regulatory Impact API that lets financial institutions embed Indorex insights into their own dashboards.
Explore partnerships with compliance software vendors and index providers.
Built With
- api
- bedrock-claude-3-sonnet
- cloudfront
- cloudwatch
- cors
- d3.js
- data
- dotenv
- finnhub
- for
- ingestion
- json/csv/pdf
- kendra
- lambda-python
- lucide-react
- market
- morgan
- node.js
- react
- s3
- shadcn/ui
- tailwind-css
- typescript
- vite.js

Log in or sign up for Devpost to join the conversation.