-
-

Gemini Vision Navigator
-
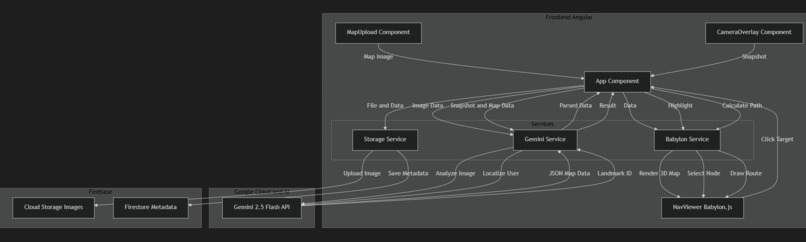
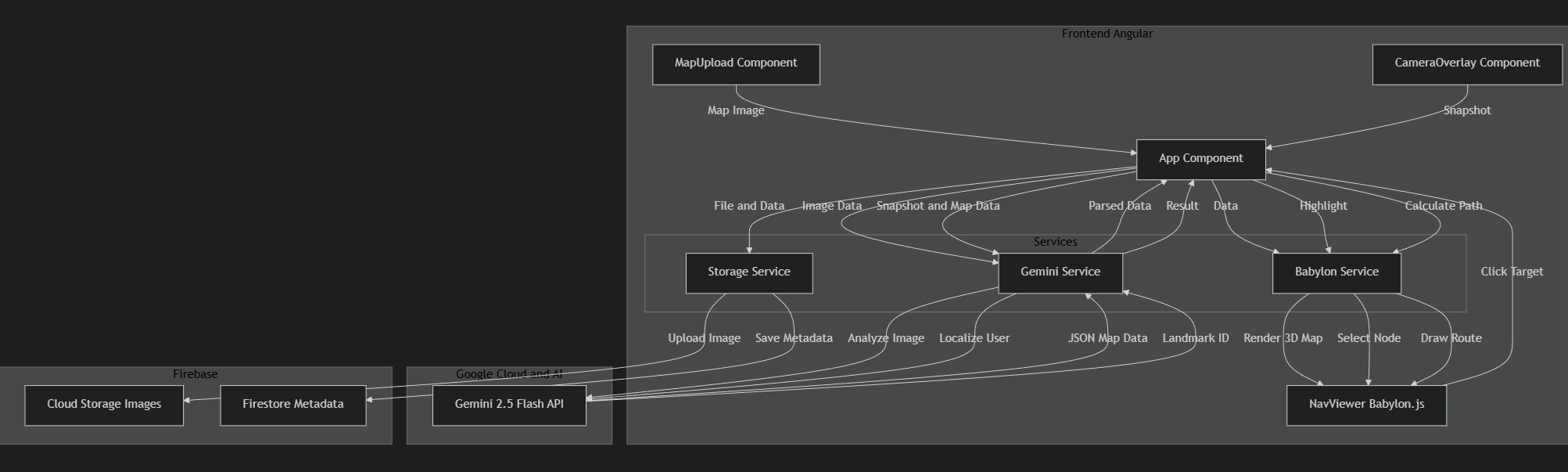
Architecture Diagram
-
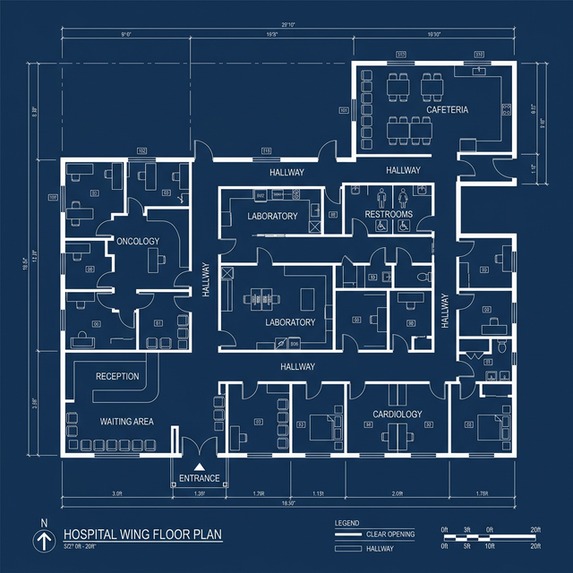
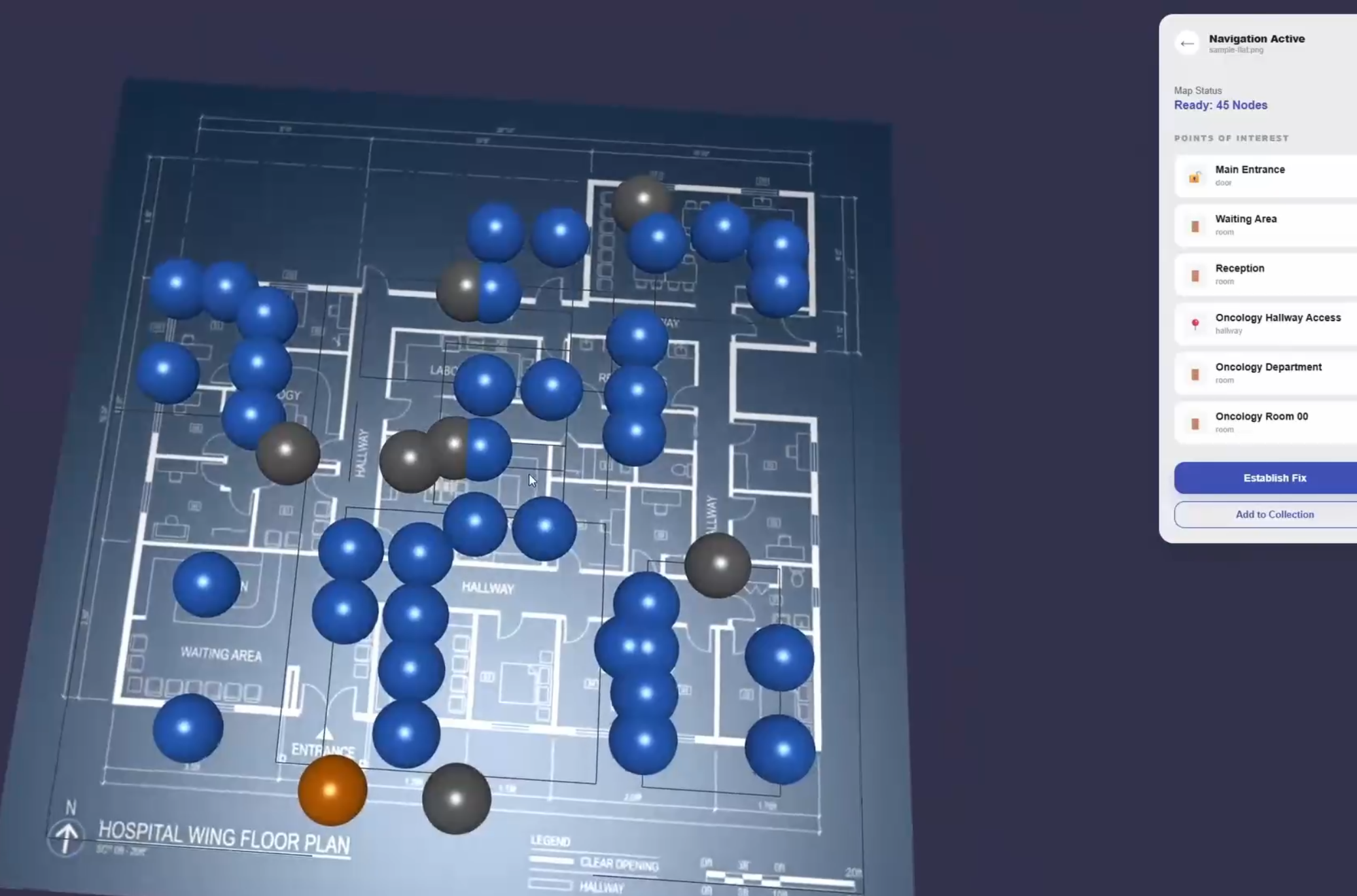
Sample - Complex Floor Plan
-
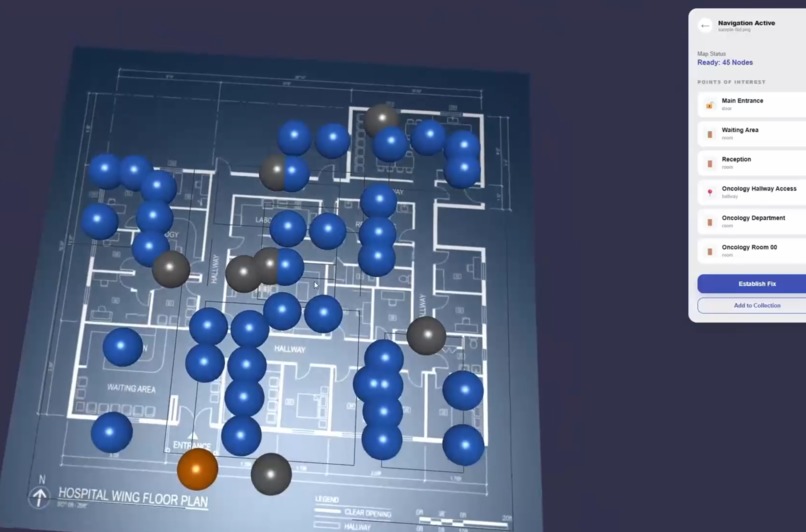
Node Generation - Complex Floor Plan
-
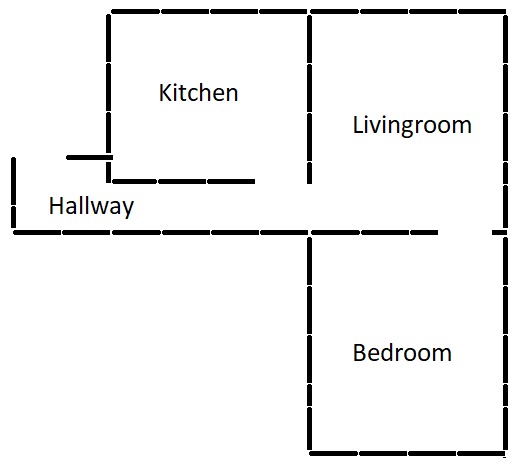
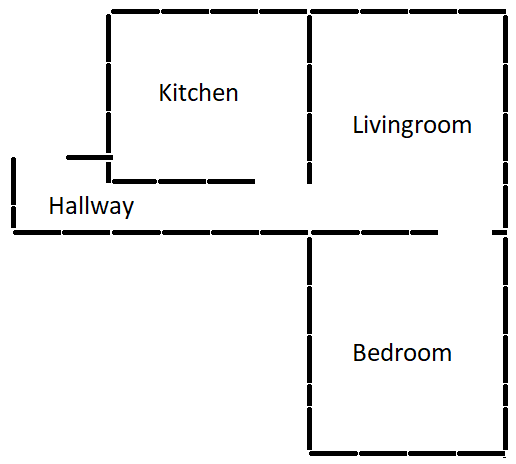
Sample - Simple Floor Plan
-

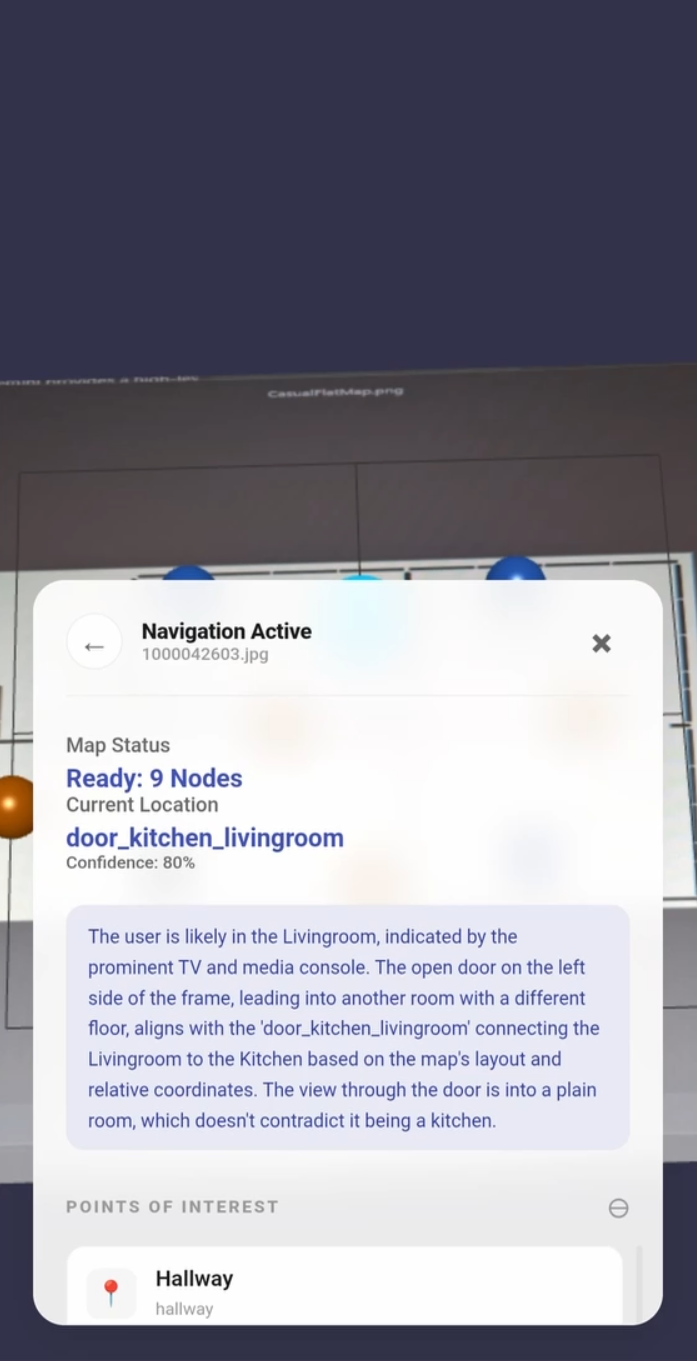
Determine Location - Simple Floor Plan
-
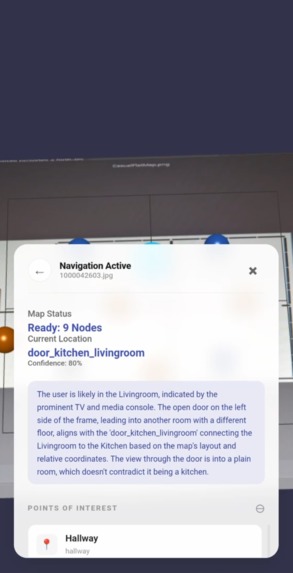
Localisation - Simple Floor Plan
-
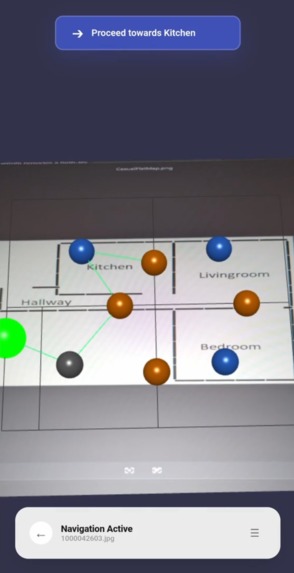
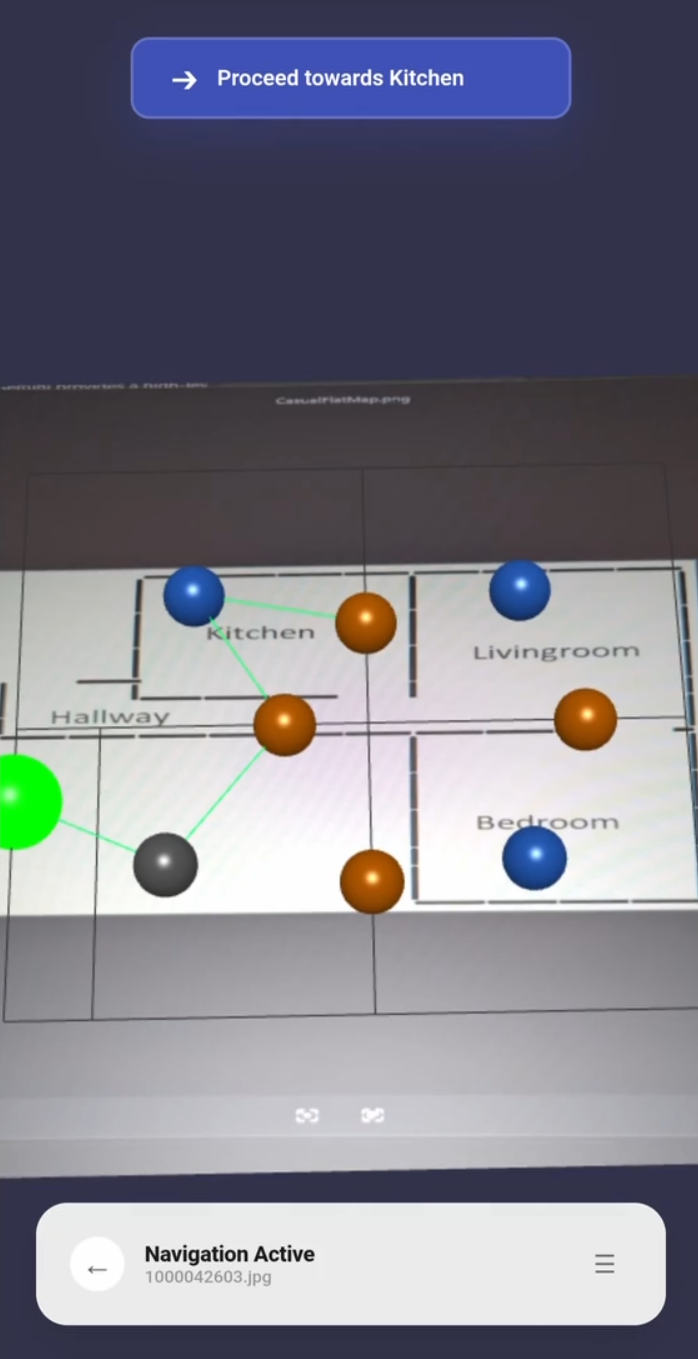
Navigation - Simple Floor Plan
-
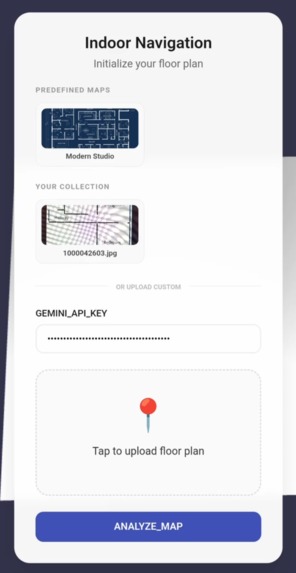
Saving User Data - Simple Floor Plan



Inspiration
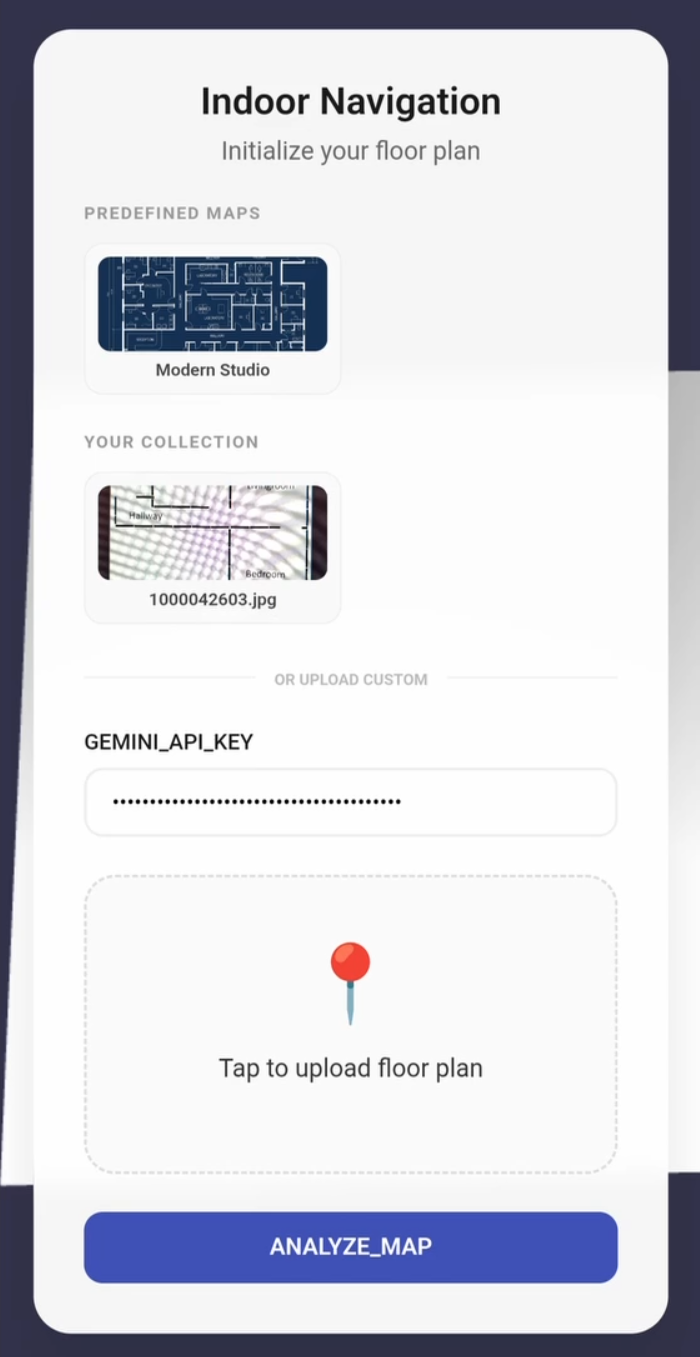
Standard GPS fails indoors and existing indoor navigation often requires expensive hardware like Bluetooth beacons or AR anchors. Looking at traditional AR indoor navigation, e.g. with Quest3 results in quite the complex setup, placing virtual walls, setup occlusion or locate the user with markers or QR codes. I wanted to see if I could solve this "last-mile" navigation problem using nothing but a smartphone camera and the spatial reasoning power of Gemini 2.5 Flash.
What it does
Gemini Vision Navigator is an "anchor-less" PWA. Users upload a 2D floor plan, which Gemini automatically parses into a navigational graph. By taking a simple camera snapshot, Gemini localizes the user within that map. The app then renders a 3D interface using Babylon.js to guide the user to their destination with a clear, visual path.
How we built it
Framework: Angular for a modern, reactive PWA. AI Engine: Gemini 2.5 Flash via the Google GenAI SDK for image analysis and zero-shot localization. 3D Visualization: Babylon.js for translating 2D data into an interactive 3D map. Backend/Cloud: Cloud Firestore for navigation metadata and Google Cloud Storage for map assets. Security: A custom SSL workflow to enable camera access on real mobile devices during development.
Challenges we ran into
Graph Extraction: Teaching the AI to accurately identify "walkable" connections between rooms solely from a static image. Strict Contexts: Navigating browser security restrictions that block camera access on non-HTTPS origins, which led us to implement a custom SSL and local network broadcasting setup. Data Serialization: Handling complex Mermaid diagrams and JSON schemas to ensure architectural clarity and API reliability.
Accomplishments that we're proud of
Zero-Shot Localization: Achieving high-confidence user positioning without pre-mapped visual markers or hardware anchors. 2D-to-3D Mapping: Successfully projecting static 2D pixel coordinates into a dynamic 3D WebGL environment for better spatial awareness. Mobile-First Design: Creating a HUD that feels native and responsive.
What we learned
I learned that Multimodal LLMs like Gemini 2.5 Flash are surprisingly adept at spatial reasoning. It's not just about "guessing" a room name; the model can genuinely understand the layout of a building and relate a first-person visual snapshot back to a top-down schematic.
What's next for Gemini Vision Navigator
Continuous Tracking: Integrating the WebXR Device API or device orientation sensors to provide smooth, real-time interpolation between Gemini "check-ins." Manual Node Editor: A user interface to let administrators "tweak" the AI-extracted graph before publishing a map. Accessibility: Voice-guided navigation instructions for visually impaired users or AI smartglasses without display.
Built With
- angular.js
- babylon.js
- firebase
- gemini
- gemini-flash
- google-cloud

Log in or sign up for Devpost to join the conversation.