





Inspiration
Slower data retrieval from streaming and other cloud based application providers
How it works
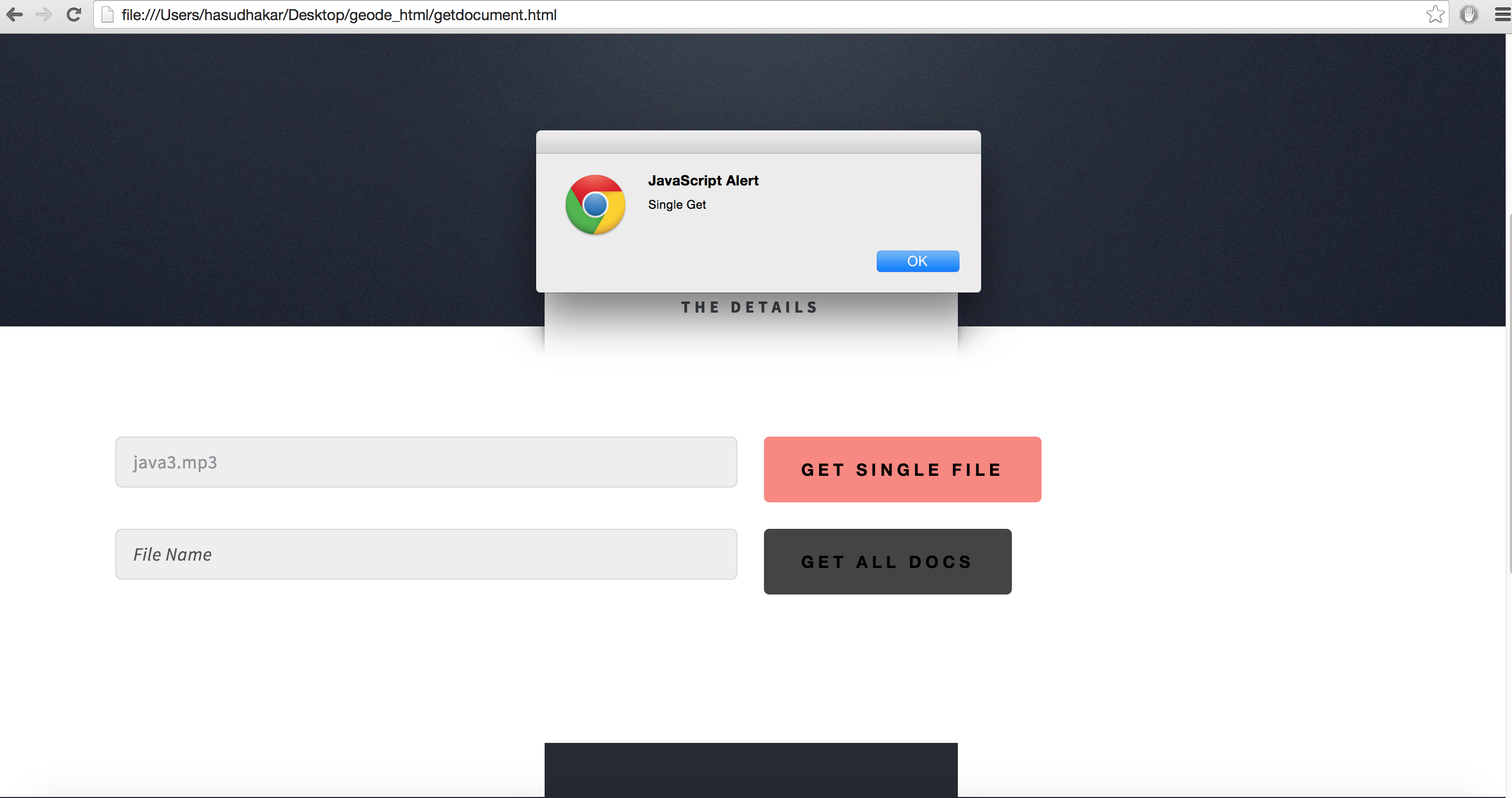
The frequently accessed data and files are stored in In-memory
Whenever the user needs a frequently accessed file.We check if the file is present in the geode region.
If present we retrieve it from the region thereby reducing retrieval time and overhead,thereby improving overall performance
For Youtube
We get the most trending videos from youtube and favorites from the users playlist and store it in In-memory database so that the access time is reduced
For Spotify
We get the favorites form the users playlist and users favorite songs from spotify and store it in the In-memory database so that the access time is reduced
For Dropbox/other cloud based service providers
We get the frequently accessed documents by the user and store them in the In-memory database so that the access time is reduced
Challenges I ran into
Getting the geode server up and running.
Integrating Javascript with geode
Accomplishments that I'm proud of
Learned to use In-memory databases
What's next for InDocs
Real time Integration with major cloud based service providers like Spotify,Dropbox,etc
The alternate video link is :http://youtu.be/BLvPcRKJbBU





Log in or sign up for Devpost to join the conversation.