-
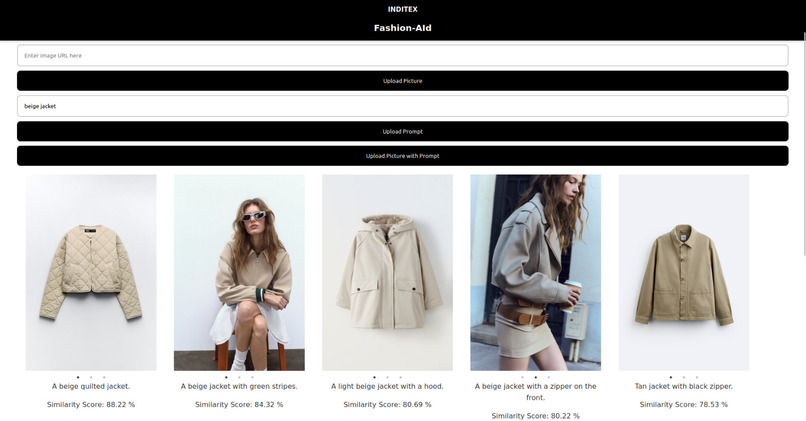
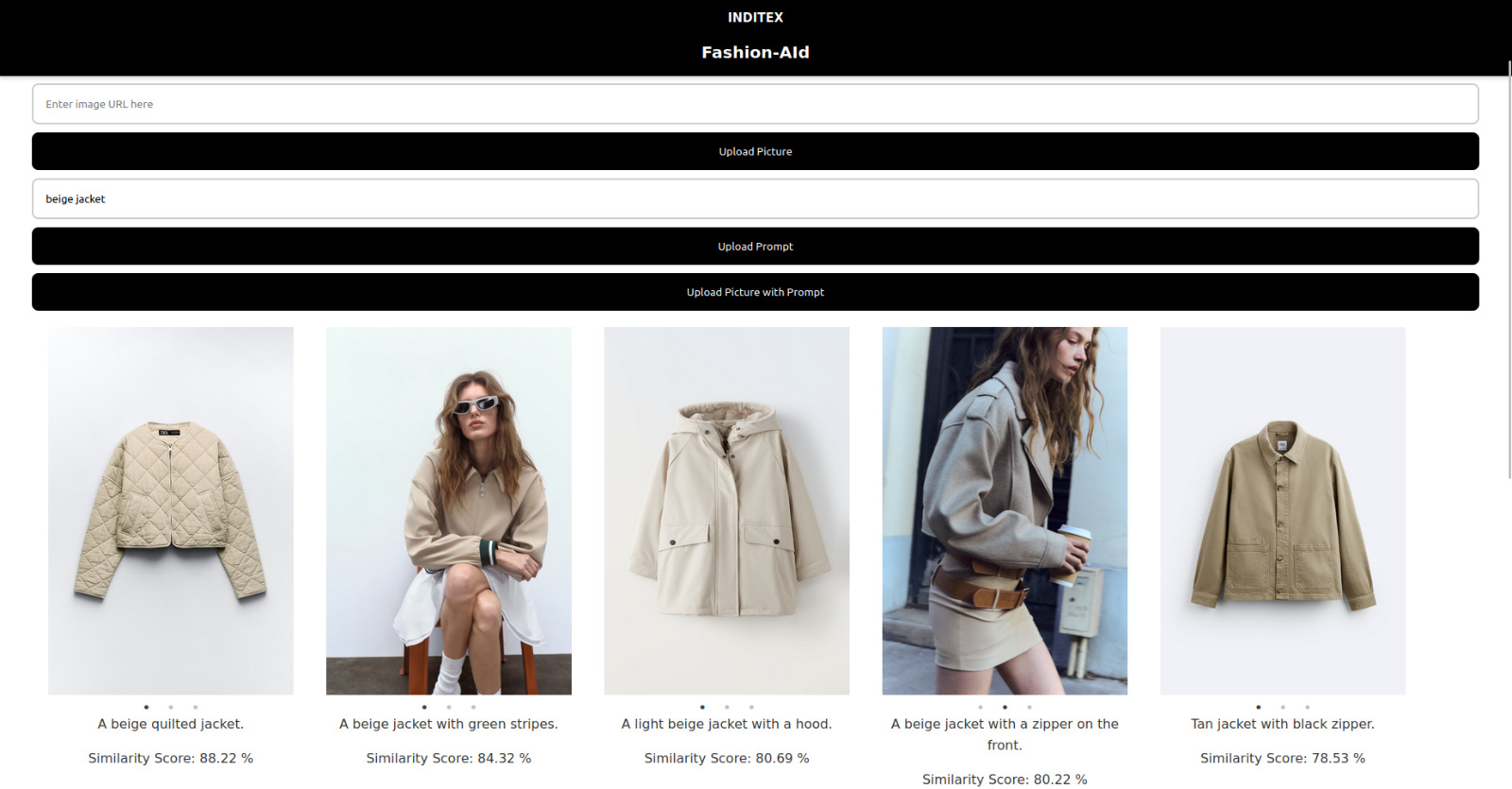
Similarity Search for Text Input
-
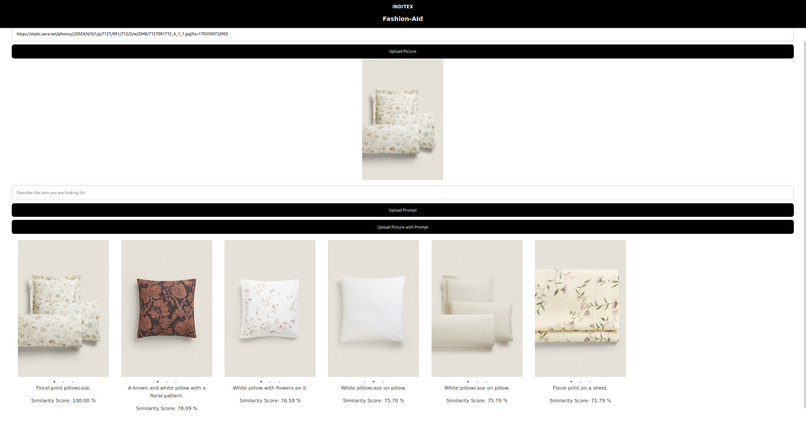
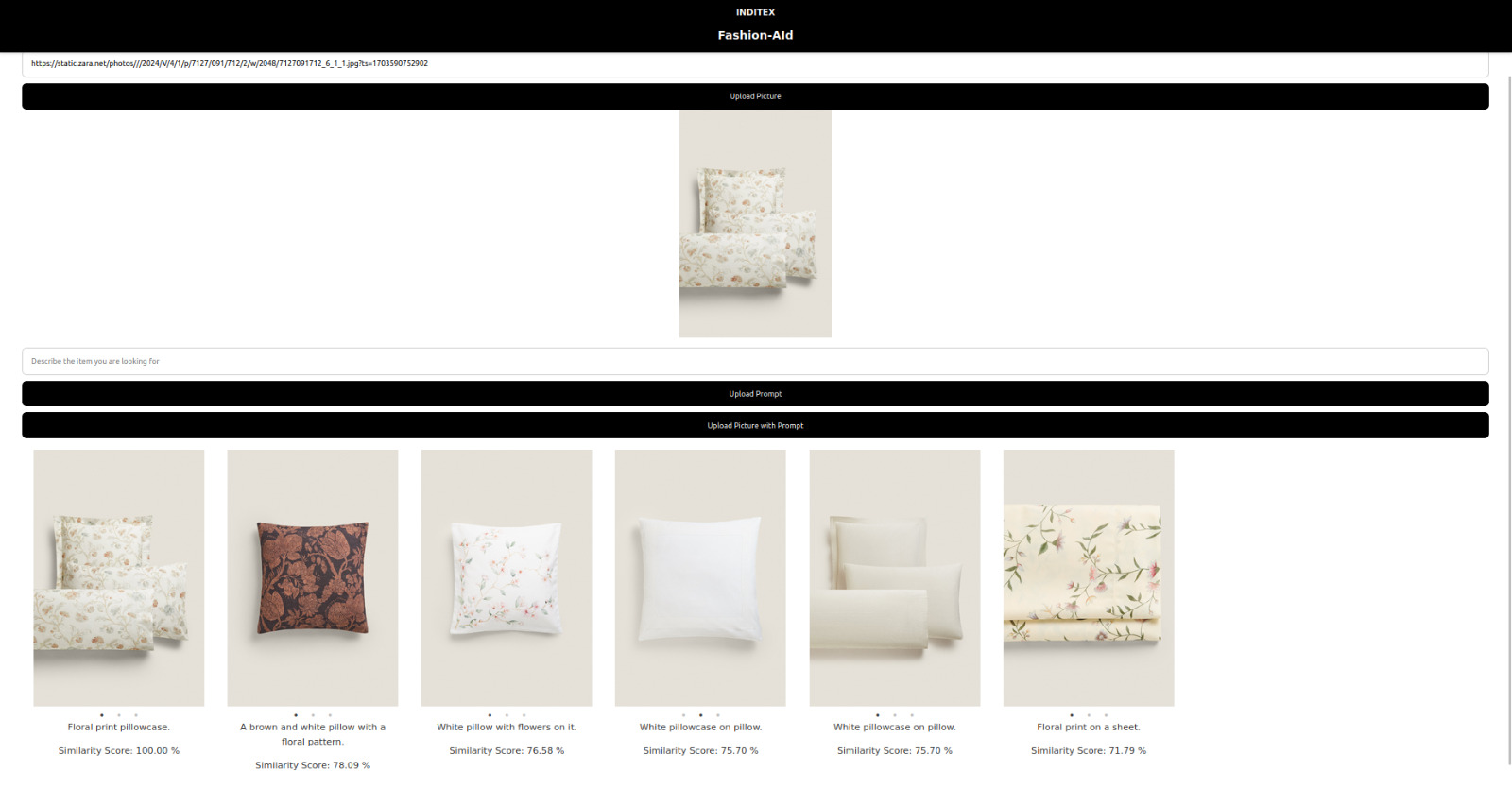
Similarity Search for Image Input
-
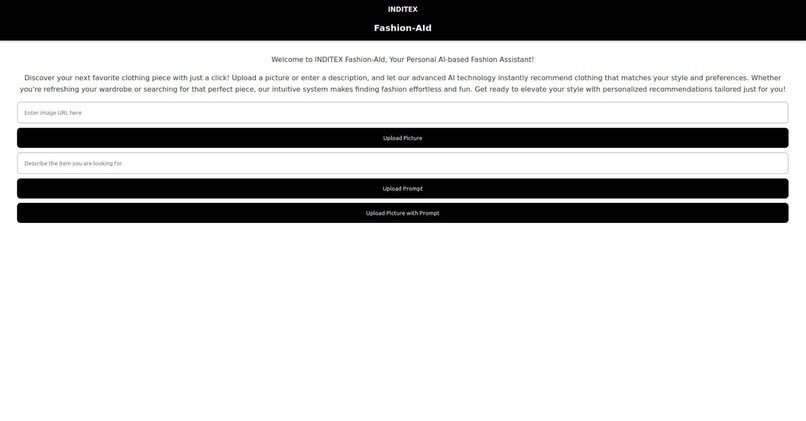
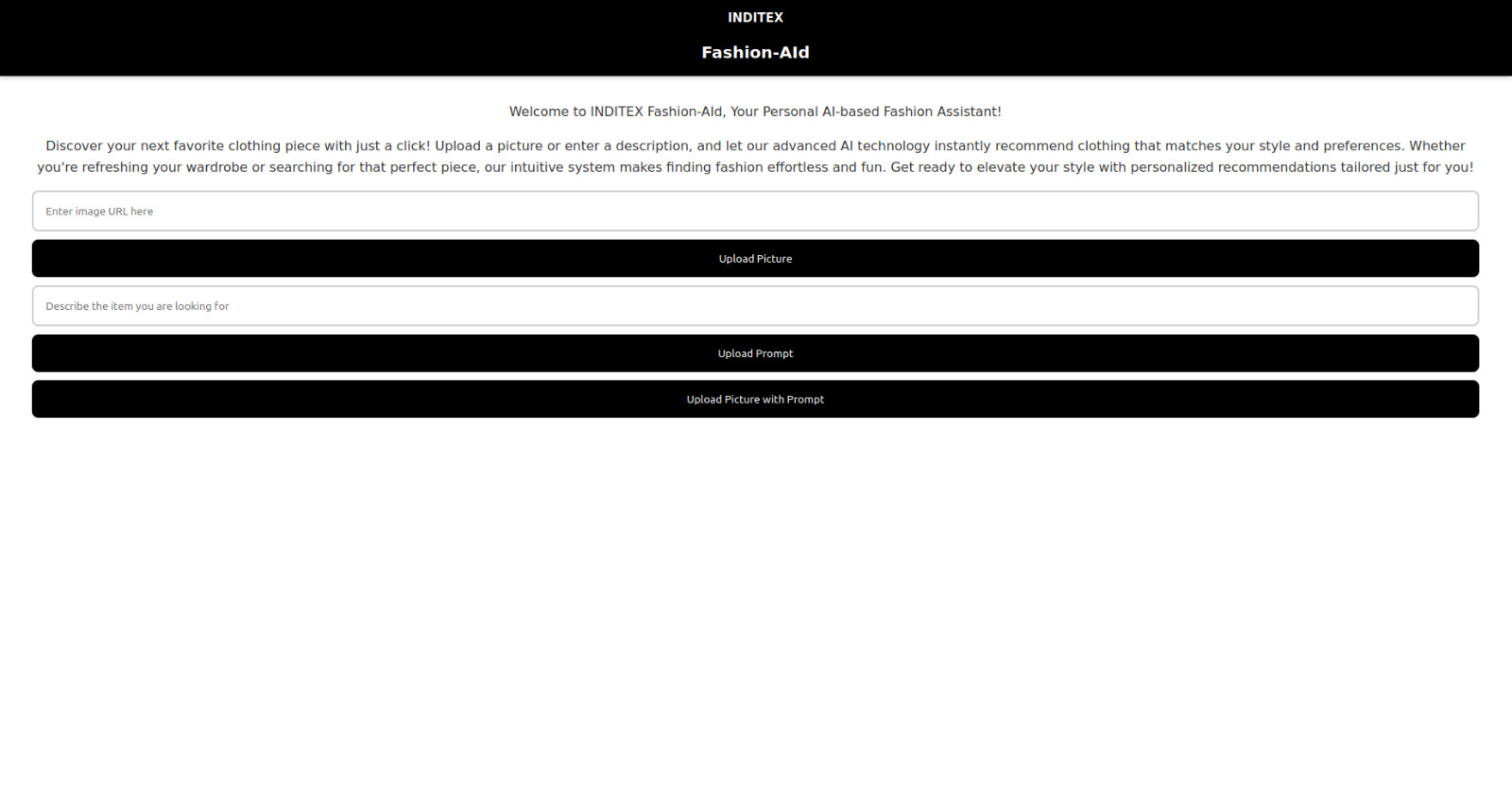
Website User Interface
-
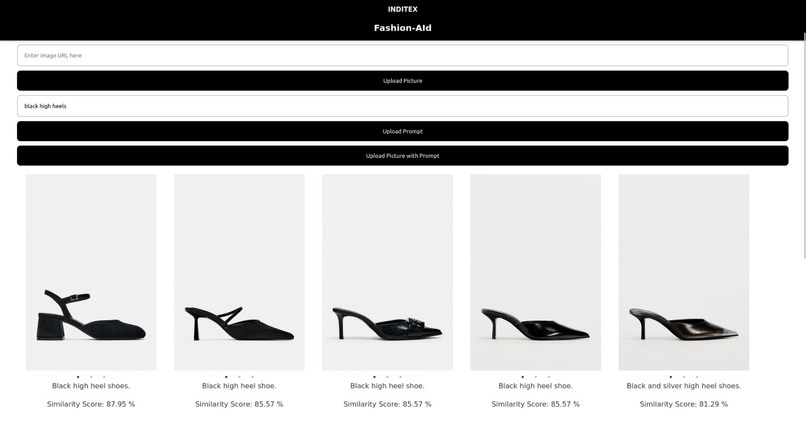
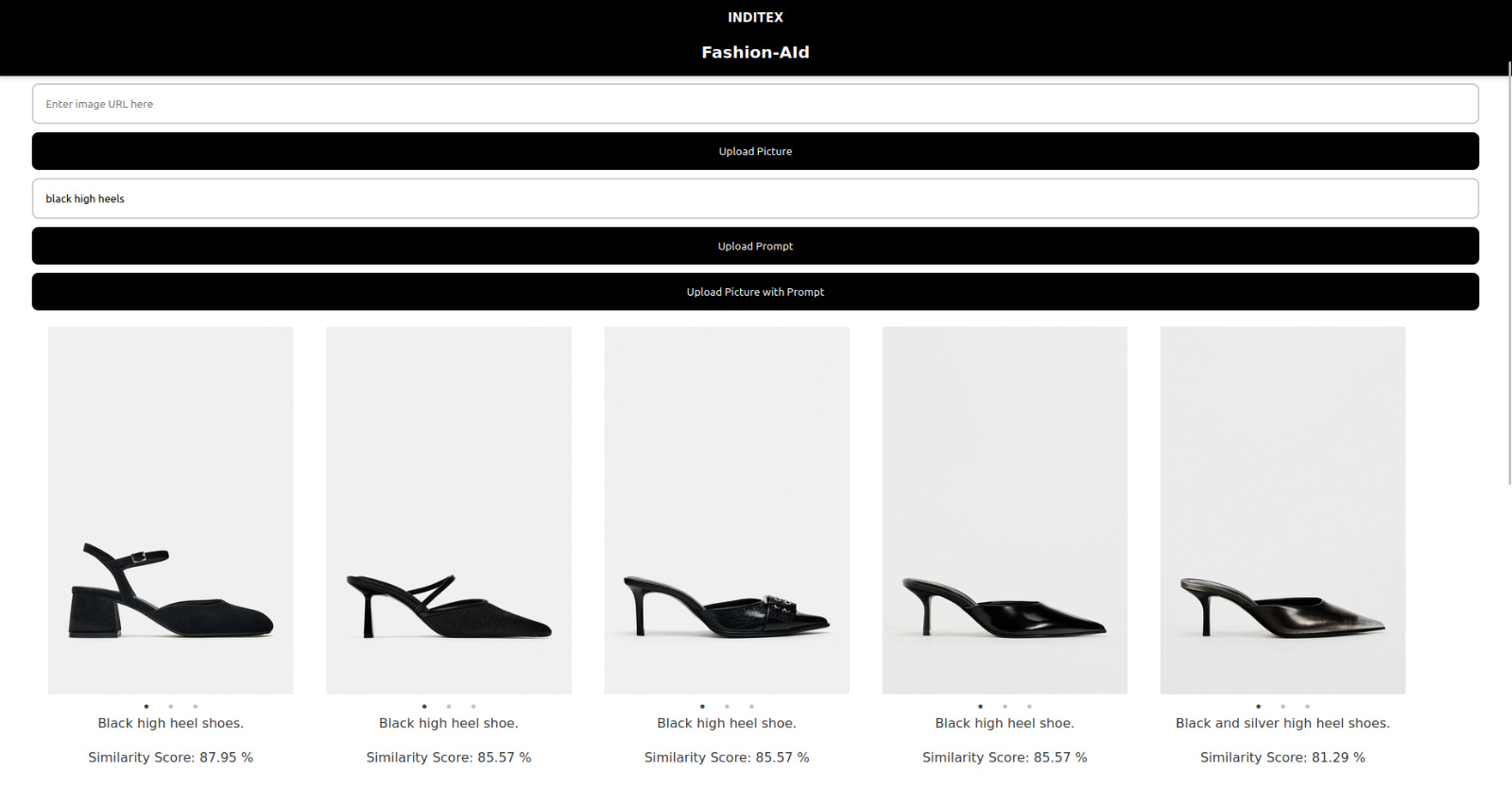
Similarity Search for Text Input
Inspiration
Fueled by a passion for applying machine learning to solve practical challenges, our team embraced the task of creating an effective AI-driven clothing similarity algorithm. The goal was simple yet ambitious: develop a tool that can recommend items similar to those a user has already viewed or purchased, enhancing the shopping experience through technology and enabling innovative solutions such as recommendation systems or targeted marketing.
What it does
With FashionAId users can upload a product image or describe a product in text. The system analyzes these inputs and returns the closest matching items from our inditex database. Each recommendation includes the description of the product and the similarity score, based on this description.
How we built it
Our system's backbone is a Python-based backend. We leverage a RAG (Retrieval Augmented Generation) Architecture by Product Fashion Images with the tiny Llava-1.5b model into high dimensional vector embeddings and saved them to a vector database to get efficient similarity search via cosine similarity. Our results are showcased through a easy-to-use React-developed frontend, offering users an intuitive and engaging interface.
Challenges we ran into
Initially, we employed the BLIP model, which was effective but not efficient. Transitioning to Llava improved both the accuracy and the processing time. Among many other hurdles we faced, the process of setting up the Llava model for precise image description posed significant challenges, e.g. specific OS requirements and time-consuming Linux installations. The prompt engineering process was also very challenging. Establishing and extracting other non-AI-based features was considered, however proved to be either non-beneficial or computationally infeasible.
Accomplishments that we're proud of
Despite being newcomers to developing recommendation systems, we managed to exceed our expectations. The accuracy, functionality and scalability of our system stand as a testament to our hard work and dedication over an intense, project-focused weekend.
What we learned
This project was not only our first hackathon but also a deep dive into the complexities of image-to-text conversion and similarity calculations in a real-world application. The experience has enriched our understanding and proficiency in these advanced technologies.
What's next
Moving forward, we would aim to refine our system by adding more features with custom weighting. This enhancement will allow us to prioritise certain attributes over others, tailoring recommendations even more closely to user preferences and improving the overall effectiveness of our tool. Also the leveraging of larger Llava models promise further performance improvements.
Built With
- chromadb
- flask
- huggingface
- javascript
- llava
- multimodal
- python
- rag
- react.js
- vectordb

Log in or sign up for Devpost to join the conversation.