



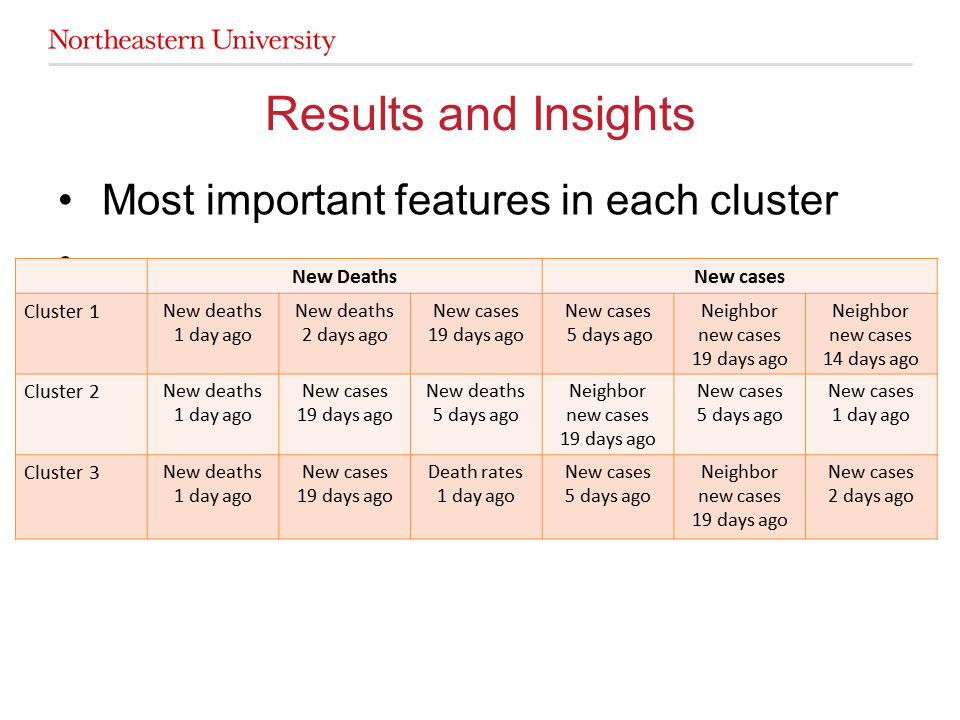

1) We want to know whether we need more than one regression models to predict the number of new cases and deaths at different time and region. If the answer is yes, how many regressors are necessary? Which part of the data are best predicted using which regressor? What are the important features for each regressor? To answer these questions, we apply the mixture of random forests algorithm to cluster the time-series data at different region into 3 goups. We train a random forest regressor for each of the clusters. The clustering results are not self-explanatory and need more processing. By observing the important features that are used for each regressor, we conclude that to predict the new cases and deaths accurately, we should not only observe the number of cases and deaths at the region of interest 1 or 2 days ago; we should also consider the data at the nearest neighbors and the data 2 or 3 weeks ago.
2) We want to observe what are the important features if we train one regression model to predict new cases of all regions at any time. We fit a Lasso Poisson regression model to the data. We observe that in addition to the past case number at the region of interest and its nearest neighbors, the quarantine data at the region of interest and its nearest neighbors are also important features for prediction.
3) We try to learn whether there is a certain relationships between the demographic factors and the transmission rate. Therefore, we first compute transmission rate in each region by assuming exponential growth. Then we find relevant factors by observing copula correlation, which is a nonlinear dependency measure . We conclude that factors of 'bad water', 'small house', 'urban', 'tap water', 'latitude' are relevant to transmission rates.


Log in or sign up for Devpost to join the conversation.