-
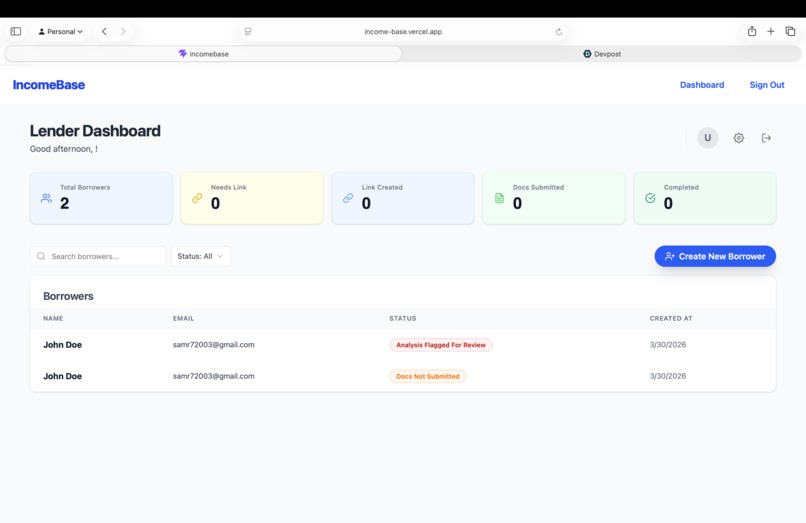
Lender Main Dashboard
-
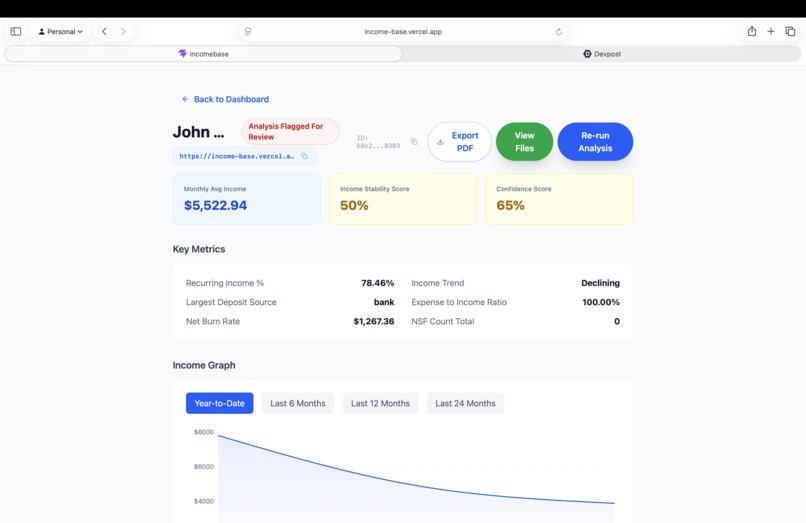
Individual Borrower Details
-
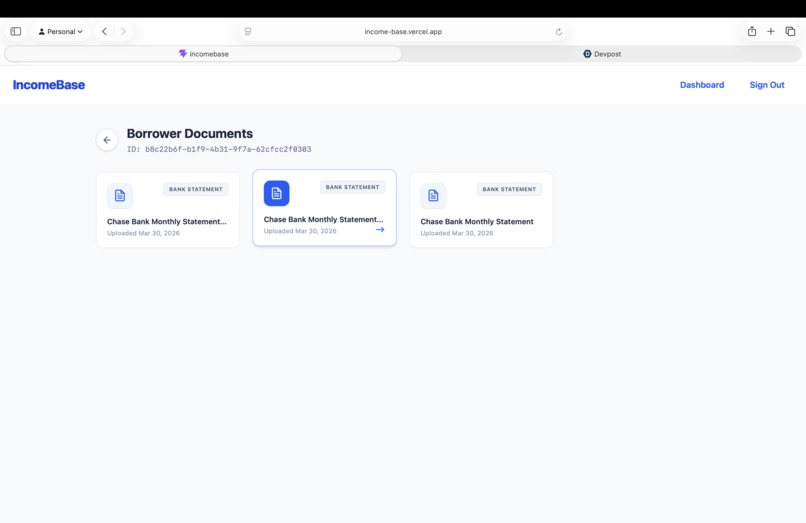
View Individual files
-
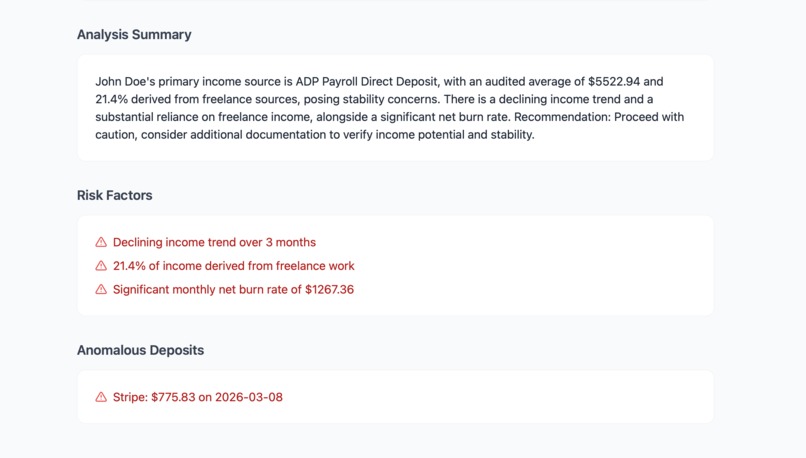
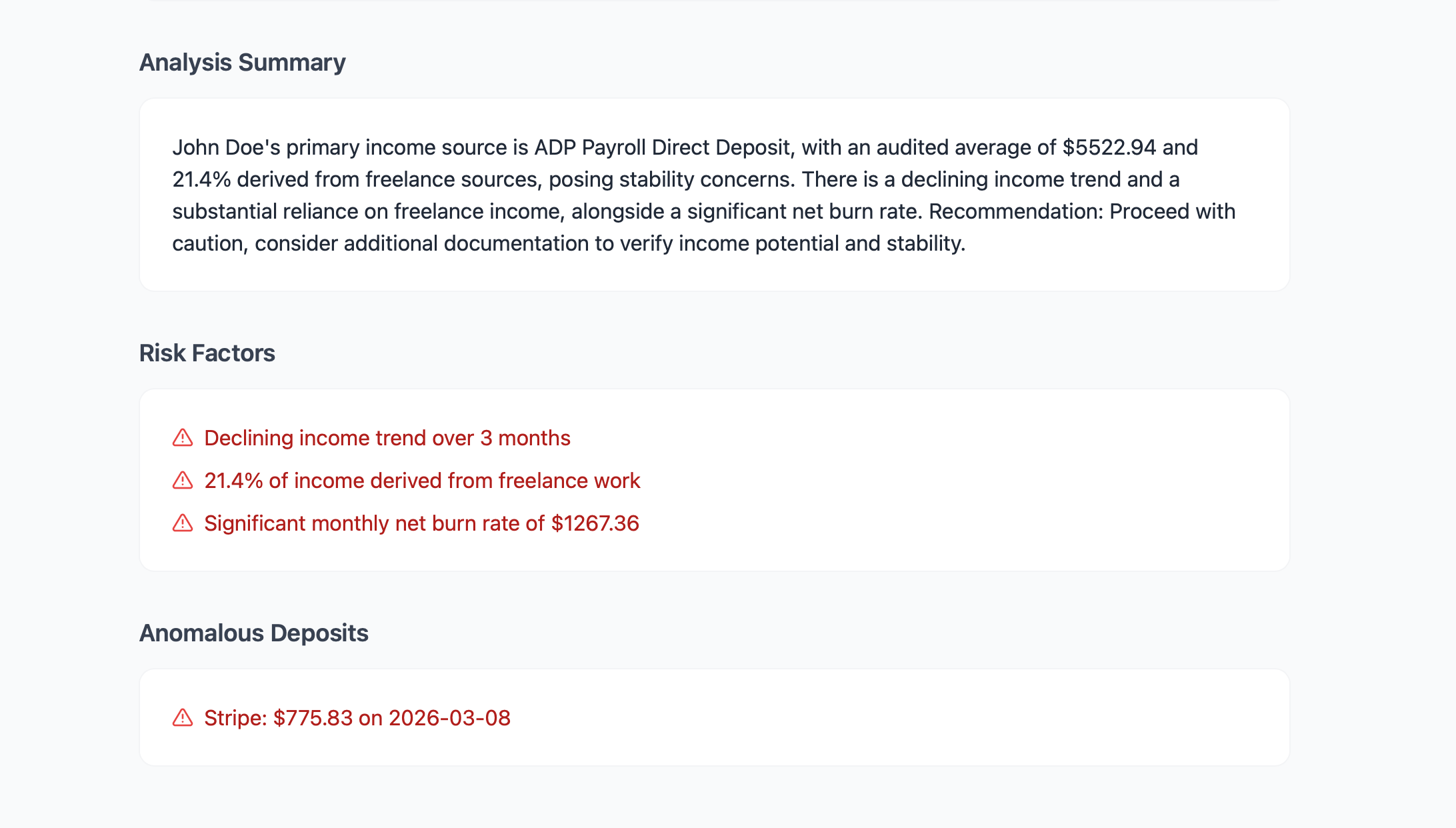
Analysis Summary
-
Inspiration
The gig economy and freelance workforce are booming, but the lending industry is still stuck in the past. If you are a W-2 employee, getting approved for a loan is straightforward. But if you are self-employed, applying for a mortgage or a business loan is a nightmare.
Borrowers have to hunt down fragmented tax returns, bank statements, and 1099s. Underwriters then spend hours manually staring at messy PDFs, trying to reconstruct complex income streams. It's a slow, inconsistent, and highly error-prone process. We realized that with recent advancements in AI and document parsing, we could completely automate the most painful part of loan origination. That's why we built IncomeBase.
What it does
IncomeBase is an enterprise AI underwriting engine for self-employed borrowers. We provide a two-sided platform:
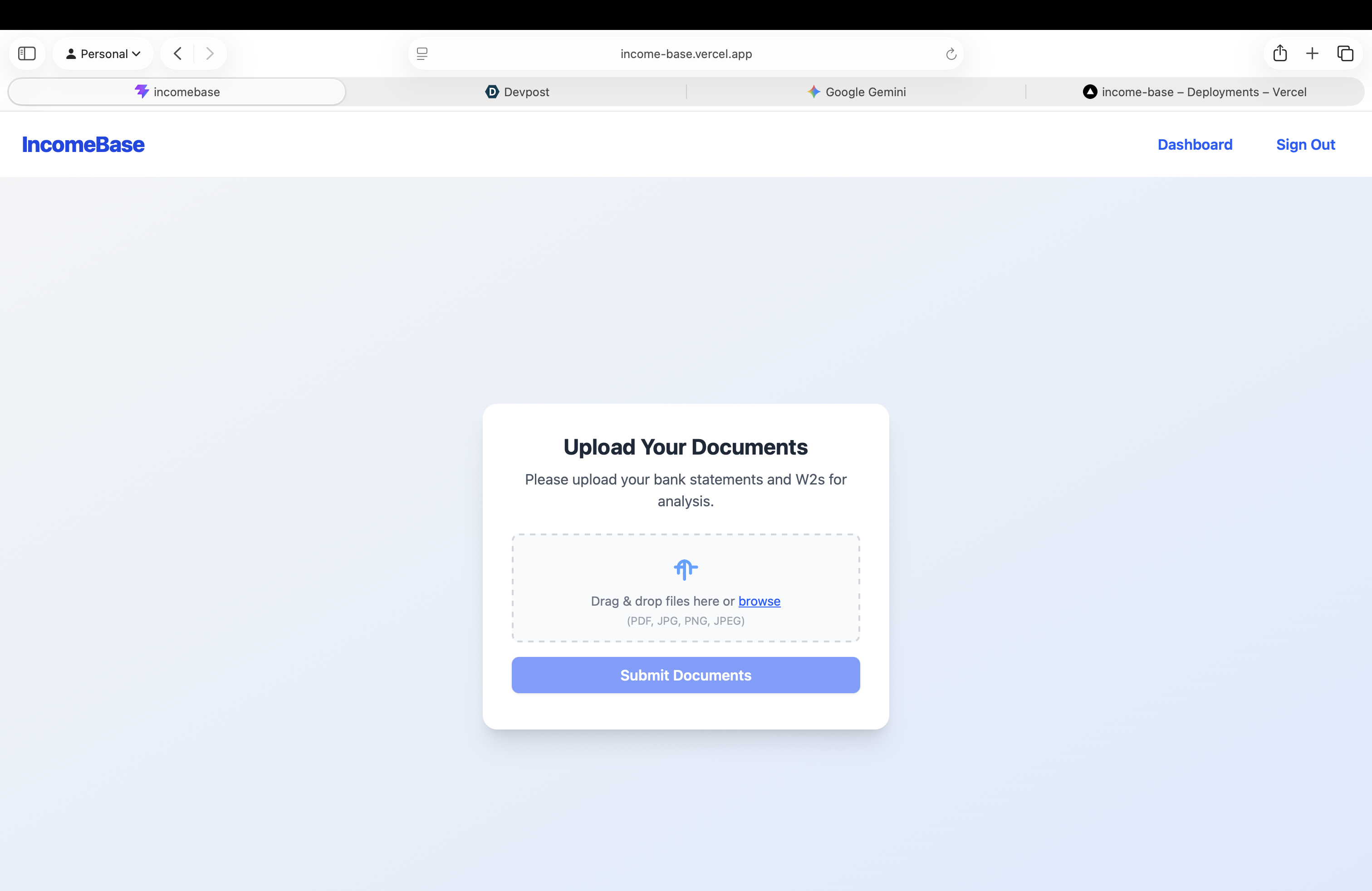
For the Borrower: A frictionless, secure upload portal that uses AI to verify identity and check documents for completeness in real-time (catching a missing page before the underwriter ever sees it).
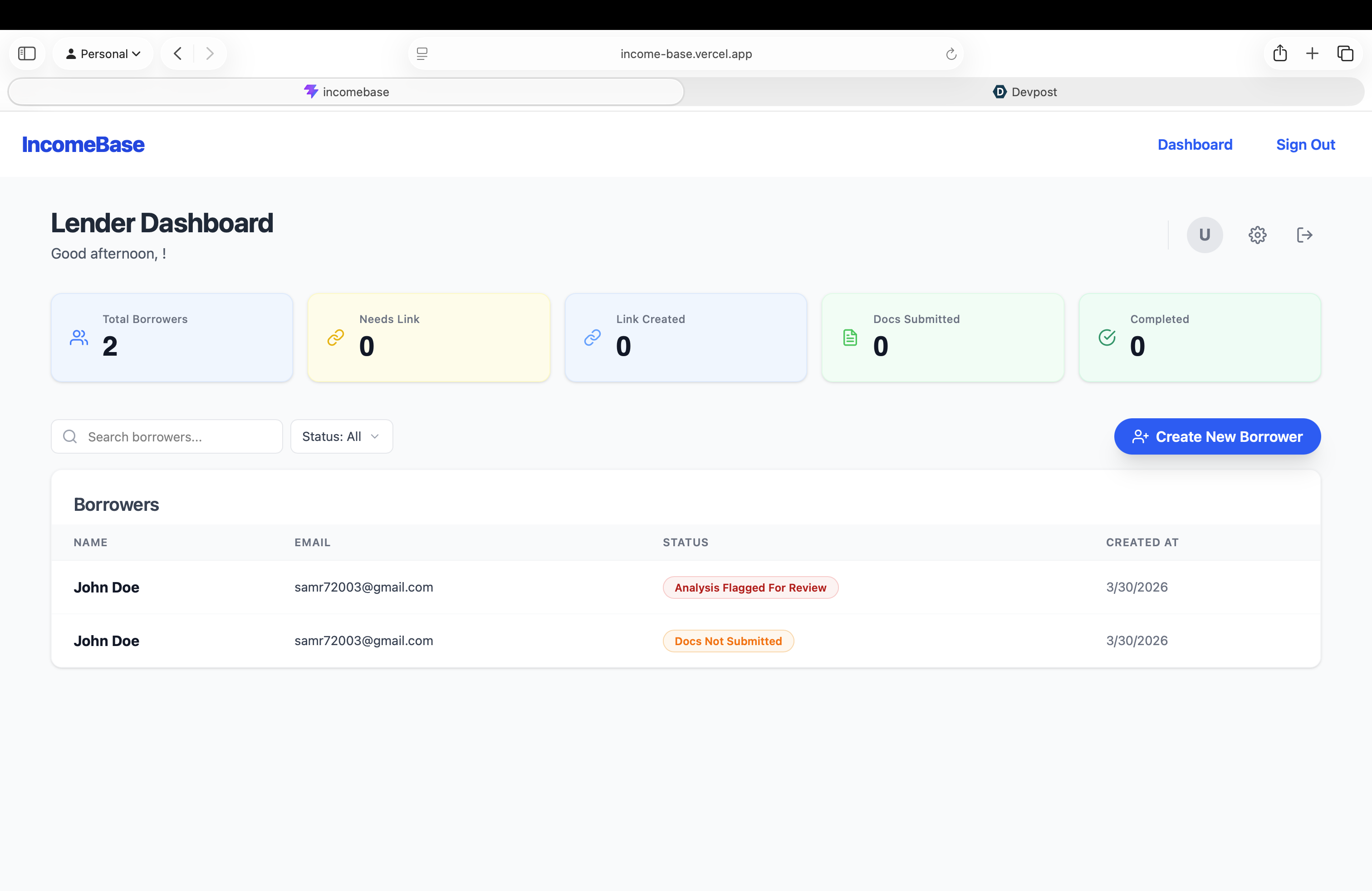
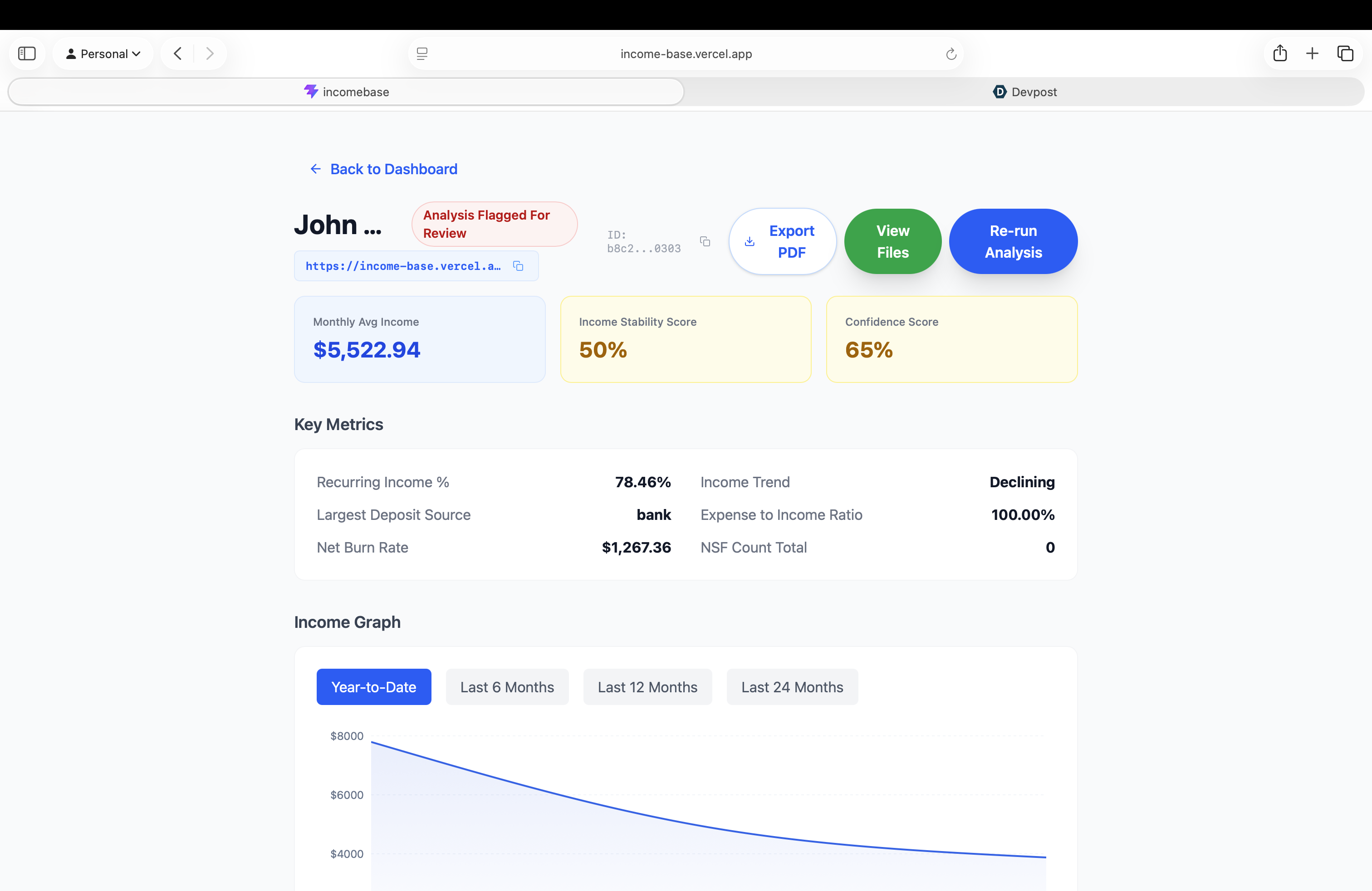
For the Underwriter: A dashboard that instantly transforms unstructured, messy financial documents into a standardized, one-click income analysis.
Instead of manual math, our AI calculates complex underwriting metrics on the fly, such as the monthly qualifying income:
$$\text{Qualifying Income} = \frac{\sum_{i=1}^{n} (\text{Gross Revenue}_i - \text{Allowable Business Expenses}_i)}{\text{Months in Period}}$$
How we built it
We architected IncomeBase for speed and reliability:
Backend: We built an asynchronous Python API using FastAPI. This handles the heavy lifting of routing documents and managing AI agent state.
Frontend: The user interfaces (both the borrower portal and the lender dashboard) are built with React, Vite, and Tailwind CSS to ensure a snappy, modern user experience.
Database & Auth: We utilized Supabase (PostgreSQL) for secure, scalable data storage and robust user authentication.
AI Engine: We used LLM agents to handle the ingestion, classification, and data extraction from unstructured PDFs and images, strictly returning the parsed financial data in structured JSON for our backend to process.
Testing & Deployment: We ensured reliability with pytest and deployed our frontend on Vercel and our FastAPI backend on Render.
Challenges we ran into
Taming Unstructured Data: Financial documents come in every shape and size—from pristine digital PDFs to blurry smartphone photos of tax returns. Tuning our AI agents to reliably extract data without hallucinating numbers was our biggest hurdle.
Strict JSON Schemas: We quickly learned that LLMs love to be conversational. Forcing the AI to output only strict, predictable JSON that our FastAPI backend could parse required heavy prompt engineering and validation loops. Here's an example of our validation approach:
from pydantic import BaseModel, validator
class IncomeData(BaseModel):
gross_revenue: float
business_expenses: float
months_in_period: int
@validator('months_in_period')
def validate_months(cls, v):
if v <= 0 or v > 12:
raise ValueError('Months must be between 1 and 12')
return v
Handling Latency: Processing multiple heavy PDFs through an AI pipeline takes time. We had to implement asynchronous endpoints in FastAPI and design our frontend to handle loading states gracefully so the user didn't think the app had crashed.
Accomplishments that we're proud of
Real-time Feedback Loop: We are incredibly proud of the "upload gatekeeper" feature. Having the AI instantly tell a borrower, "Hey, page 3 of this bank statement is missing," saves days of email back-and-forth between the lender and the applicant.
Seamless Full-Stack Integration: Successfully connecting a Vite/React frontend to a Supabase database and an async Python backend—all deployed live during a hackathon—was a massive technical win for us.
What we learned
Prompt Engineering is Code: We learned that treating AI prompts as rigid, version-controlled code is essential for building deterministic software.
Architecture Matters: Separating our frontend client from our heavy Python processing backend allowed us to iterate much faster and debug issues in isolation. The key formula we optimized for was:
\(\text{Development Velocity} = \frac{\text{Feature Iterations}}{\text{Debug Time} + \text{Integration Overhead}}\)
What's next for IncomeBase
More Document Types: Expanding our AI models to handle a wider variety of edge-case tax schedules (Schedule C, Schedule E, K-1 forms, etc.).
Direct Plaid Integration: Allowing borrowers to link their bank accounts directly alongside their document uploads for automated cross-referencing and fraud detection via Plaid's API.
Loan Origination System (LOS) Export: Building APIs to push our verified income reports directly into enterprise systems like Encompass and Calyx Point.



Log in or sign up for Devpost to join the conversation.