
Inspiration
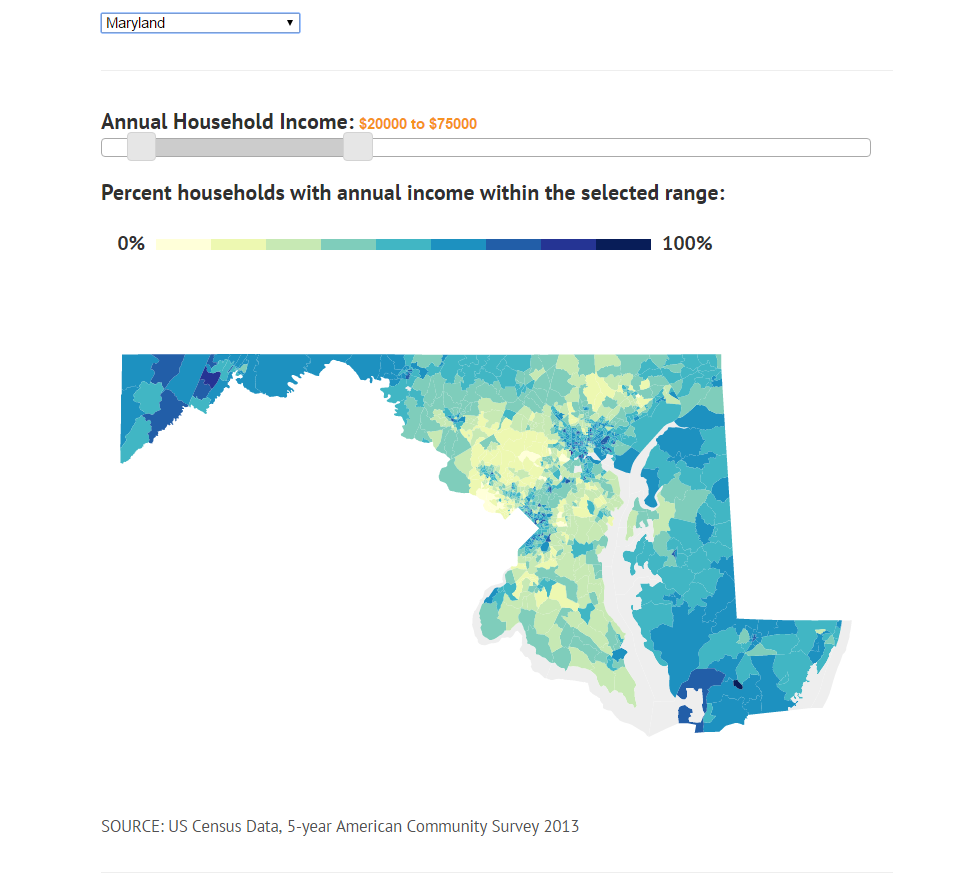
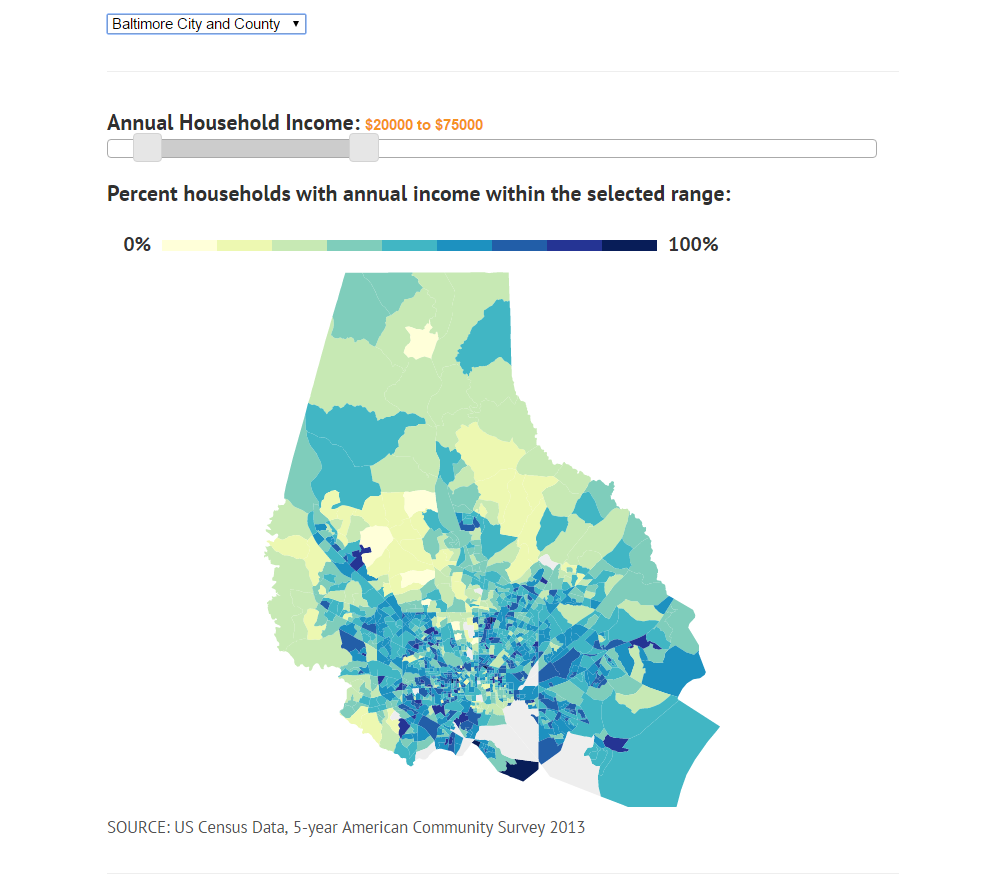
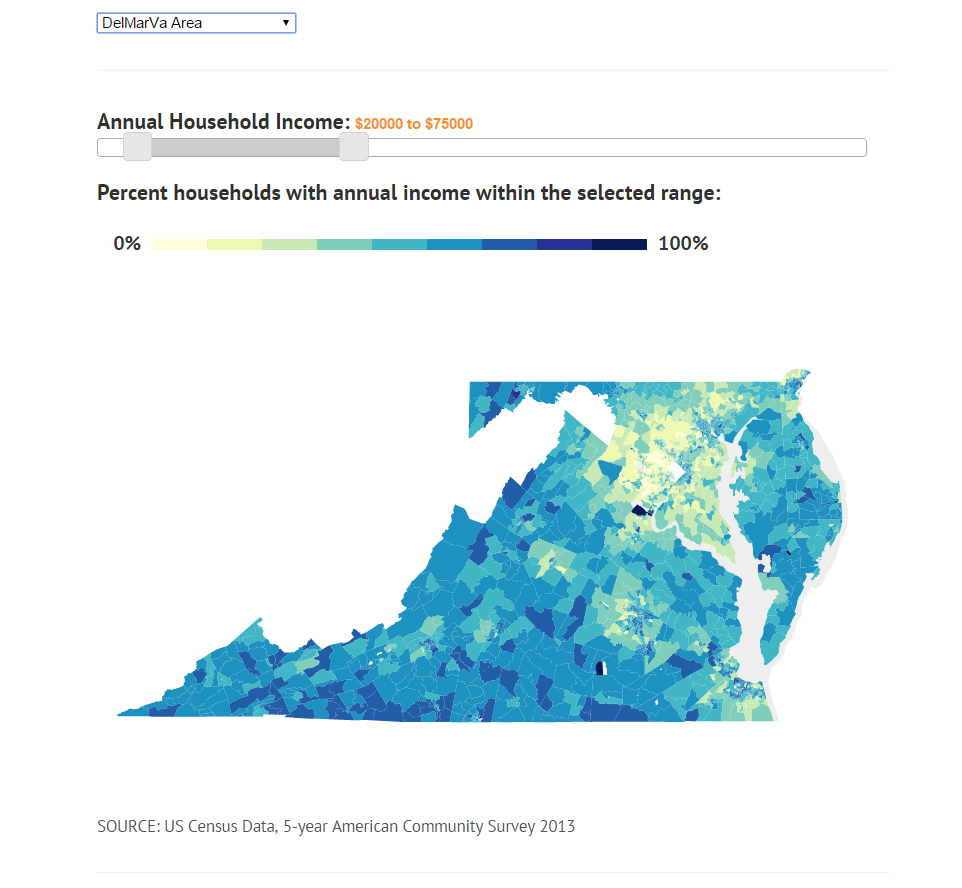
Maps of income often only portray average or median income, providing only a partial view on the distribution of income in a particular geographic area. Additional insight can be gained by considering the entire distribution of incomes.
This project was inspired by the need to better identify the range of incomes earned by households in different parts of the country.
Additionally, I wanted to automate map creation as much as possible. From gathering and processing data to generating the map, I wanted everything to be done in code where possible.
There are a number of use cases possible for this data, but I had two specific cases in mind:
1. Identifying low-income areas where many people are likely to be eligible for tax credits.
This use case is in support of an earlier project of mine: The Baltimore Tax Credit Map
2. Finding areas where housing might be found that matches a family's income
This use was inspired by the challenge of trying to understand suitable places to live for a given income level, especially when moving to a new city.
Visual styling and implementation was influenced by a recent WaPo visualization by Christopher Ingraham and Lazaro Gamio and this choropleth by Mike Bostock.
What it does
The project is a series of interactive maps that allow users to view the relationship between income and location. Users can choose an income range and see where in the a given city, county, state or larger region that people with annual household incomes in that range live. Exploration is encouraged and quickly reveals high income, low income, and middle class areas. Maps will be included for several major urban areas, though more can be generated on demand.
How I built it
The project consists of two primary components:
1. Data gathering and cleaning
Python scripts were written to gather income data from the US Census. This effort was assisted by use of the Sunlight Foundation Census API. Additionally, collection of necessary TIGER shape files was automated with Python.
Data from the census was cleaned and organized using pandas. TIGER shapefiles were processed and filtered using geopandas. The end of this stage results in a census data file in csv format and a separate shapefile formatted as geojson.
2. Map visualization
Map visualization was done using d3.js.
Challenges I ran into
TIGER shapefiles for tracts and block groups are packaged for each state as a whole. Often, we are interested in only mapping one or two counties and thus it is necessary to filter out only the regions of interest. I managed to accomplish this using the Python module geopandas and filtering the shape data to only include regions that were specified by the user.
d3 is often counter-intuitive and difficult to work with. The number of challenges I ran into with d3 are too many to list.
Accomplishments that I'm proud of
On acquiring data:
At this point, I'm very proud of wrangling the US Census and TIGER shape data into submission. There is a wide variety of information available from the US Census website, but understanding exactly what's available and how to get it is challenging.
Even using an API, it can be difficult to figure out exactly what information is available. The American FactFinder site was very helpful in this regard. Once the desired data has been identified, the proper FIPS codes and Variable codes have to be found in order to automate data acquisition. Just managing to figure out how to automate this process was an accomplishment.
On visualization:
I'm proud of the entire visualization. Admittedly, a lot of it was only made possible by scouring and modeling off of similar projects, but just getting all the parts working together was a challenge. This is one of my few projects with any real amount of interactivity or significant UI elements. Getting maps to render properly is challenging. Styling the shape fills based on data is challenging. Having everything update properly when sliders and selections change is also challenging.
Honestly, I'm still amazed the visualization works at all.
What I learned
This is perhaps the most modular and reproducible mapping effort I have made to date. Other than looking up county codes and census attribute codes, map generation is fully automated without any reliance on manual tools. I have tested the code and found that it readily extends to multiple scales. I also learned to manage my time pretty well given the ground that had to be covered for this project in less than 48 hours.
What's next for Income Explorer
For data gathering, I intend to polish up my existing python code to make it more readily extensible to acquiring data from many metropolitan areas as well as attributes beyond household income.
On the visualization side, I plan to add additional interactive elements such as shape highlighting on mouseover as well as detailed tooltips. Site design and styling can use improvement as well.
Built With
- census-api
- d3.js
- geopandas
- javascript
- jquery
- pandas
- python


Log in or sign up for Devpost to join the conversation.