-
-
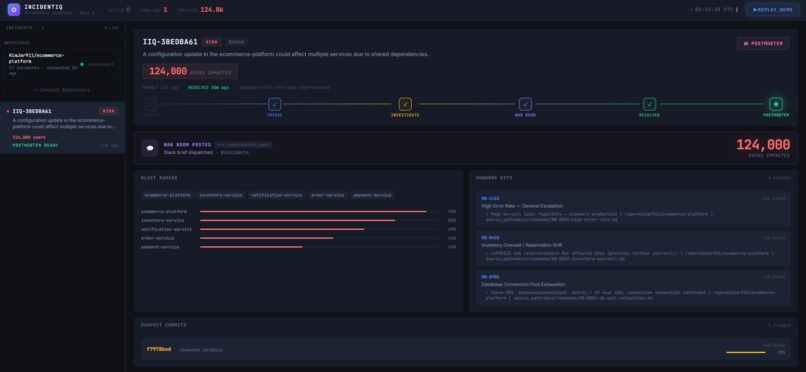
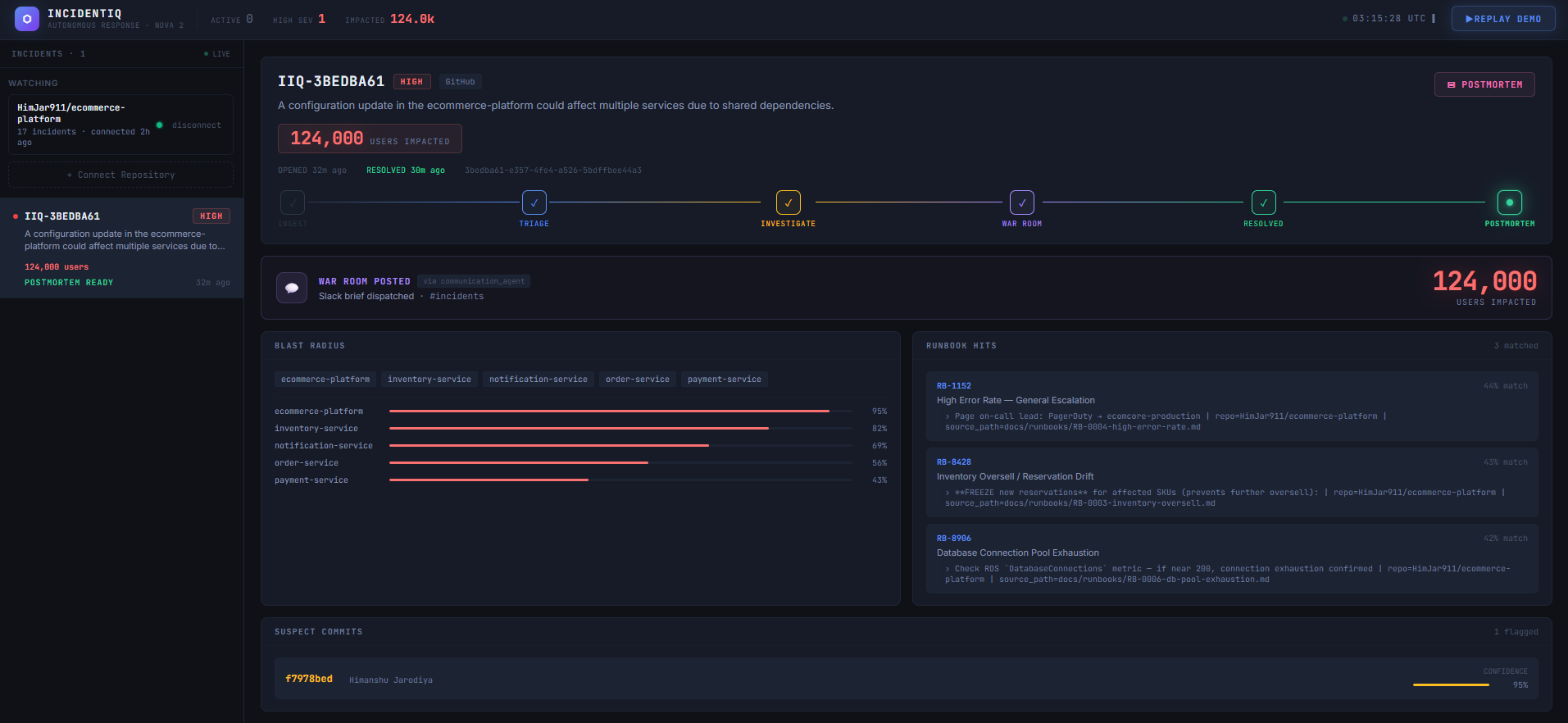
HIGH severity, 124,000 users affected, 5 services in blast radius, 3 runbooks matched, all in under 10 seconds.
-
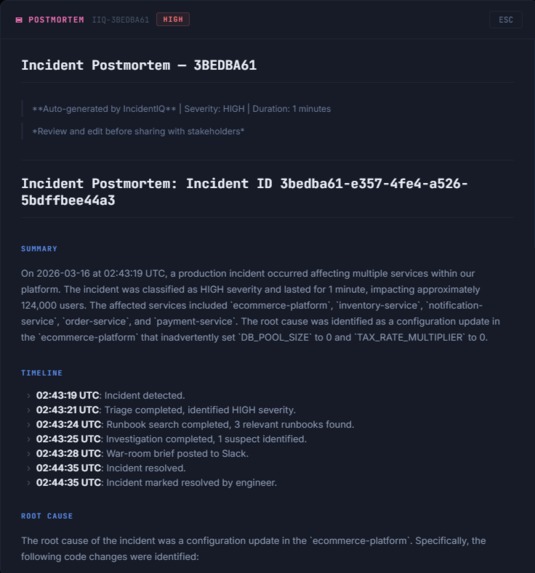
Auto-generated postmortem — timeline, root cause with exact code lines, and verified fix commit. Zero human effort.

The Problem
Every engineering team knows the drill. A bad commit hits production. Someone gets paged at 1am. They hop on a call with five other half-asleep people and nobody knows what broke. They're staring at logs, pinging services, trying to piece together what happened while every minute that passes means more users affected, more revenue lost, more regulatory exposure. By the time they figure it out, it's been 45 minutes. Sometimes longer.
The frustrating part? This is a solved problem. The information needed to diagnose the incident is all there — in the git history, in the codebase, in the service dependencies. Nobody's connecting the dots automatically. I built IncidentIQ to do exactly that.
What It Does
IncidentIQ is an autonomous incident response system. You connect a GitHub repo and from that point on, every push to main gets evaluated. The ones that matter trigger a full automated pipeline that detects the risky commit, investigates the actual changed lines, calculates blast radius from the real service dependency graph, estimates how many users are affected, posts a Slack war room brief, and generates a full postmortem after resolution.
The whole thing runs in under 10 seconds.
What Inspired Me
I kept seeing the same thing on engineering Twitter. Screenshots of 2am incident calls, engineers scrambling to understand what broke, postmortems written from memory days later. It's not a people problem — engineers are smart. It's an information problem. The right data exists, it's just scattered across git history, service configs, and runbooks, and nobody's assembling it automatically at 2am when you actually need it.
I wanted to build something that meant the on-call engineer wakes up to answers, not questions.
How I Built It
The core is a multi-agent pipeline running on AWS ECS, powered by Amazon Nova.
The push filter is a two-layer gate. The first layer is instant — file pattern matching that skips README edits, test changes, and docs. The second layer is a Nova Lite semantic call that asks: is this push worth paging an engineer? Only genuinely risky commits make it through.
The investigation agent fetches the actual unified diff from the GitHub API before calling Nova Pro. This was the key insight — most tools just look at filenames. IncidentIQ reads the changed lines themselves. Nova Pro can then cite specific line numbers, identify the exact variable that broke, and explain the business impact. Two bugs in one commit? It finds both.
The repo analyzer runs at onboard time and builds a real picture of the system. It parses HTTP call patterns in the codebase to build a service dependency graph. It scans the README and infrastructure config to estimate daily active users, anchored to explicit numbers if the README mentions them. It finds runbooks in the repo's docs folder and uploads them to S3 and a Bedrock Knowledge Base so they can be searched semantically when an incident fires.
The fix commit detector runs when an engineer marks an incident resolved. It fetches commits since the incident, has Nova read each diff, and only marks a commit as the verified fix if it's confident the diff actually reverses the original bug. Not just "next commit equals fix."
The postmortem agent pulls everything together — timeline from DynamoDB, root cause from the investigation agent, engineer resolution notes from the dashboard, verified fix commit from the detector — and generates a complete document automatically.
The Challenges
Making the investigation actually read the diff was the first real challenge. Early versions just passed filenames to Nova and got generic responses like "config file was modified." The breakthrough was building a diff fetcher that pulls the real unified diff from the GitHub API and gives it to Nova directly. Once Nova sees the actual changed lines, the output changes completely — from vague summaries to "Line 66: TAX_RATE_MULTIPLIER set to 0, causing zero-tax orders and potential regulatory violations."
The push filter had a false positive problem. Early versions fired on revert commits, which meant the fix itself was creating new incidents. I built a restorative commit detector that checks message patterns and validates against the diff to confirm values are being restored rather than broken further.
Getting Bedrock Knowledge Base to use repo-specific runbooks took some debugging. The KB sync wasn't firing after S3 uploads, so the runbook agent kept returning generic fallbacks. The fix was calling start_ingestion_job() after every upload and storing the data source ID as an environment variable. Once that was wired up, the runbook agent started returning the actual procedures written for that specific system.
HTTPS on the frontend was also an issue. Vercel serves over HTTPS but the backend ALB is HTTP and browsers block mixed content. The solution was a Vercel reverse proxy where vercel.json rewrites all API calls through Vercel's servers to the backend, so the frontend only ever talks to an HTTPS endpoint.
What I Learned
The biggest lesson was how much context matters for LLM-based agents. The same Nova model gives dramatically different outputs depending on whether you give it filenames or actual diffs. Real data — real service graphs, real user counts from READMEs, real runbooks from the codebase — makes the difference between a system that produces plausible-sounding outputs and one that produces genuinely actionable intelligence.
I also learned that agentic systems need explicit failure modes. Every agent has a fallback. The push filter fails safe — if Nova errors, it runs the pipeline anyway. The DAU estimator has a heuristic fallback. The fix commit detector requires 75% confidence before marking anything as verified. Building these guardrails is what makes the system actually trustworthy.
Nova Usage
| Model | Role |
|---|---|
| Nova Lite | Push filter risk assessment, triage severity classification, fix commit verification |
| Nova Pro | Deep investigation — reading unified diffs, identifying specific broken lines, root cause analysis |
| Nova Multimodal Embeddings | Bedrock Knowledge Base for semantic runbook search across repo-specific docs |
Nova Lite handles the high-frequency, low-cost decisions. Nova Pro handles the deep analysis where accuracy matters most. The split keeps costs at pennies per incident while maintaining quality where it counts.
What's Next
IncidentIQ works today for any GitHub repo. The natural next steps are multi-tenancy with per-org Knowledge Base namespaces, real DAU from CloudWatch instead of estimated, PagerDuty integration for automated escalation, and mobile push notifications for war room alerts.
The deeper vision is a system that gets smarter over time — learning from postmortems to improve blast radius prediction, recognizing patterns across incidents, and eventually suggesting preventive fixes before things break.
Built With
- amazon-bedrock
- amazon-bedrock-knowledge-bases
- amazon-nova-(lite
- amazon-web-services
- aws-dynamodb
- aws-ecs-fargate
- fastapi
- github-api
- multimodal-embeddings)
- pro
- react
- slack
- vercel

Log in or sign up for Devpost to join the conversation.