-
-
Architecture Diagram
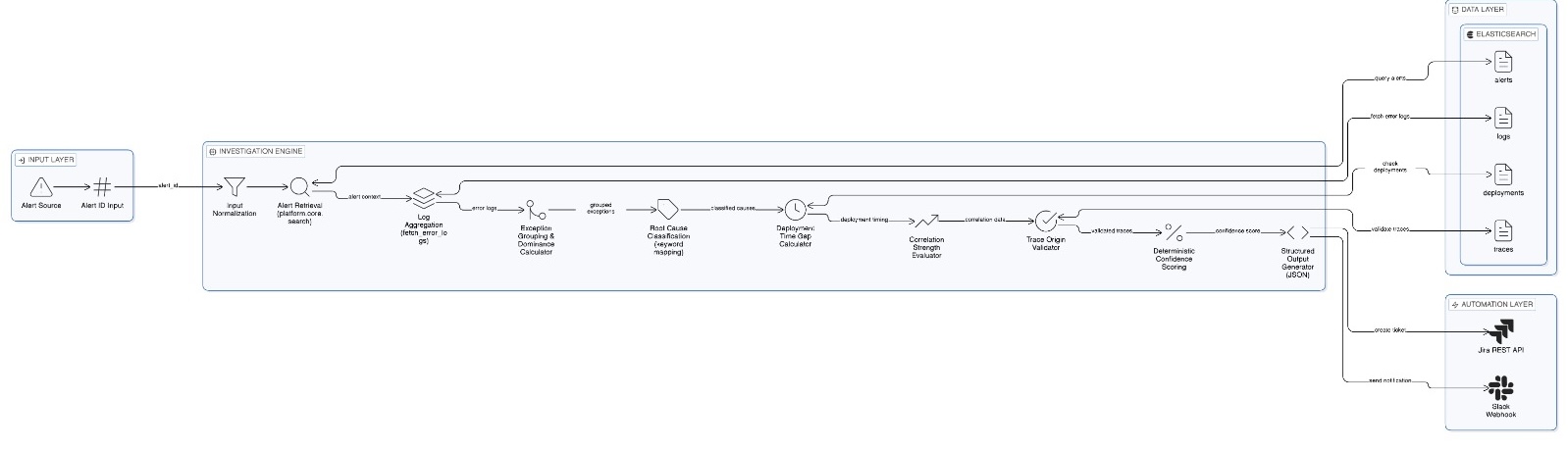
IncidentCop AI
Inspiration
In real production environments, incident investigation is manual and repetitive. When an alert fires, engineers search logs in Elasticsearch, group exceptions, inspect traces, check deployments, and decide whether to escalate. This process can take 30–60 minutes.
We wanted to reduce that time to under 2 minutes using a deterministic, rule-based system that transforms raw telemetry into structured diagnosis — without speculation or semantic reasoning.
What it does
IncidentCop AI automatically investigates production alerts using Elasticsearch data.
Given an alert_id, it:
- Retrieves alert details from the
alertsindex - Fetches error logs within the alert time window
- Counts total errors
- Identifies the dominant exception
- Calculates dominance percentage
- Classifies root cause using strict keyword rules
- Checks recent deployments
- Computes time gap in minutes
- Determines correlation strength
- Validates failure origin using distributed traces
- Calculates deterministic confidence
- Triggers Jira and Slack automation if severity is HIGH or CRITICAL
Dominance percentage is calculated as:
$$ \text{dominance_percentage} = \frac{\text{dominant_count}}{\text{total_errors}} \times 100 $$
Confidence scoring model:
- +2 if dominance ≥ 60%
- +1 if dominance between 40–59%
- +2 if trace confirms origin
- +1 if no secondary pattern exceeds 30%
- +1 if correlation strength is STRONG
Final confidence:
- ≥ 5 → HIGH
- 3–4 → MEDIUM
- < 3 → LOW
All conclusions are numeric and rule-based.
How we built it
IncidentCop AI is a deterministic investigation pipeline built over Elasticsearch production data.
Core Data Sources
alertsindexlogsindexdeploymentsindextracesindex
Investigation Workflow
Alert → Logs → Deployment → Traces → Confidence → Automation
Deployment correlation is calculated using:
$$ \text{time_gap_minutes} = \text{alert_start} - \text{deployment_timestamp} $$
Correlation strength thresholds:
- ≤ 30 → STRONG
- 31–120 → MODERATE
- > 120 → WEAK
Root cause classification is strictly keyword-based:
- Timeout / ConnectionRefused / ServiceUnavailable → DOWNSTREAM_DEPENDENCY_FAILURE
- NullPointer / IllegalState / IndexOutOfBounds → INTERNAL_APPLICATION_ERROR
- Config-related errors → CONFIGURATION_ISSUE
No semantic reasoning layer is used.
Challenges we ran into
- Designing strict deterministic rules without interpretation
- Handling mixed error distributions
- Preventing overconfidence in classification
- Keeping deployment correlation purely numeric
- Ensuring reproducible outputs
Accomplishments that we're proud of
- Reduced manual triage time from 30–60 minutes to under 2 minutes
- Built a fully deterministic root cause classification engine
- Designed a transparent numeric confidence scoring model
- Integrated automatic Jira ticket creation and Slack notification
- Produced structured JSON output for integration into other systems
What we learned
- Deterministic systems improve production reliability
- Numeric thresholds increase auditability
- Log aggregation is critical for fast diagnosis
- Deployment timing must be measured objectively
- Trace validation strengthens confidence
We learned how to combine logs, deployments, and traces into a structured, rule-driven investigation engine.
What's next for IncidentCop AI
- Add historical incident comparison
- Expand root cause categories
- Introduce anomaly detection
- Build a visual investigation dashboard
- Add multi-service dependency mapping
Our long-term goal is to evolve IncidentCop AI into a full autonomous SRE assistant while maintaining deterministic reliability.



Log in or sign up for Devpost to join the conversation.