-
-
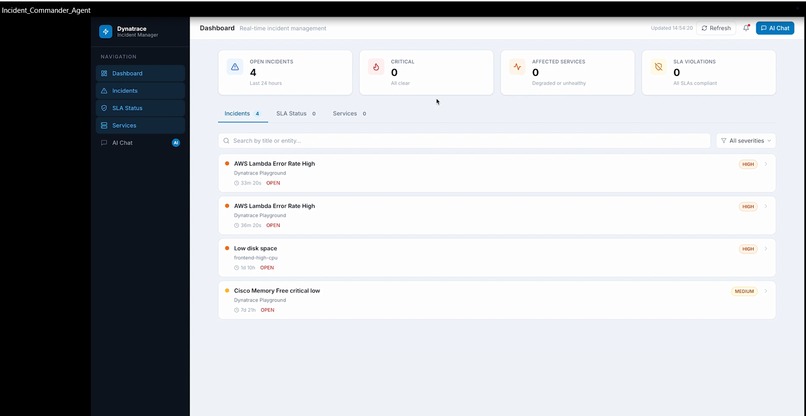
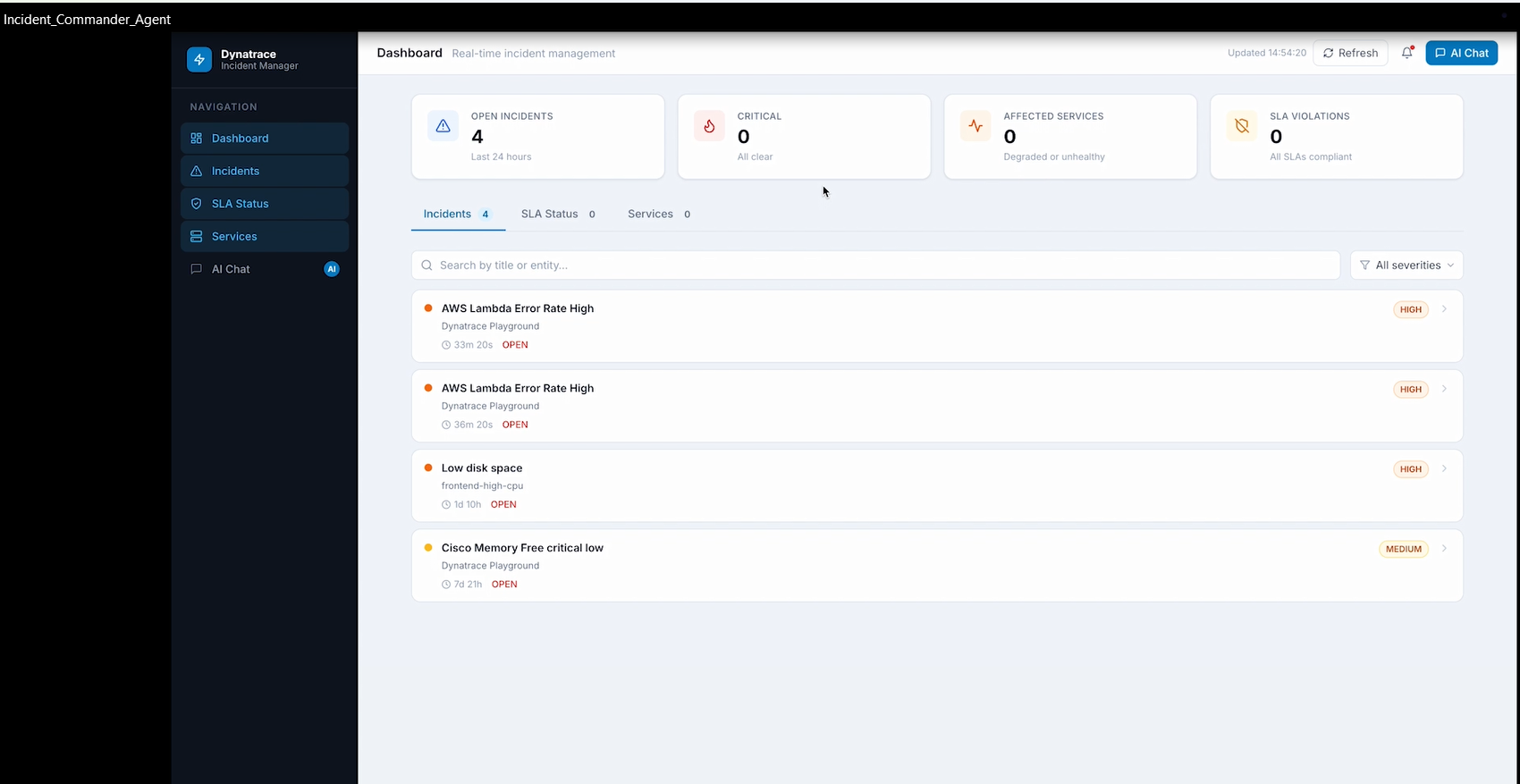
Dashboard screen
-
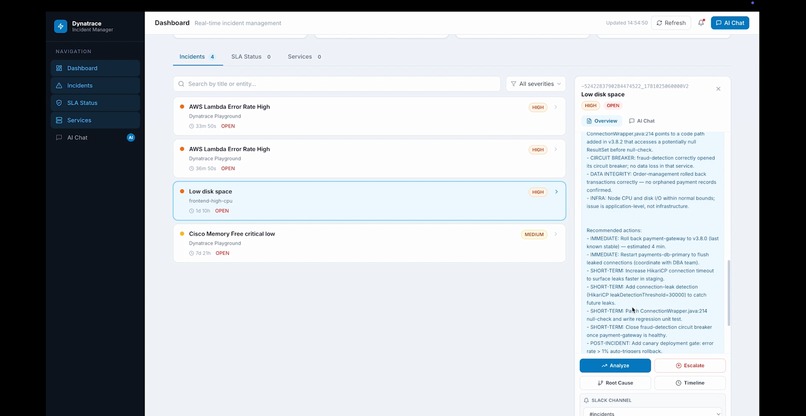
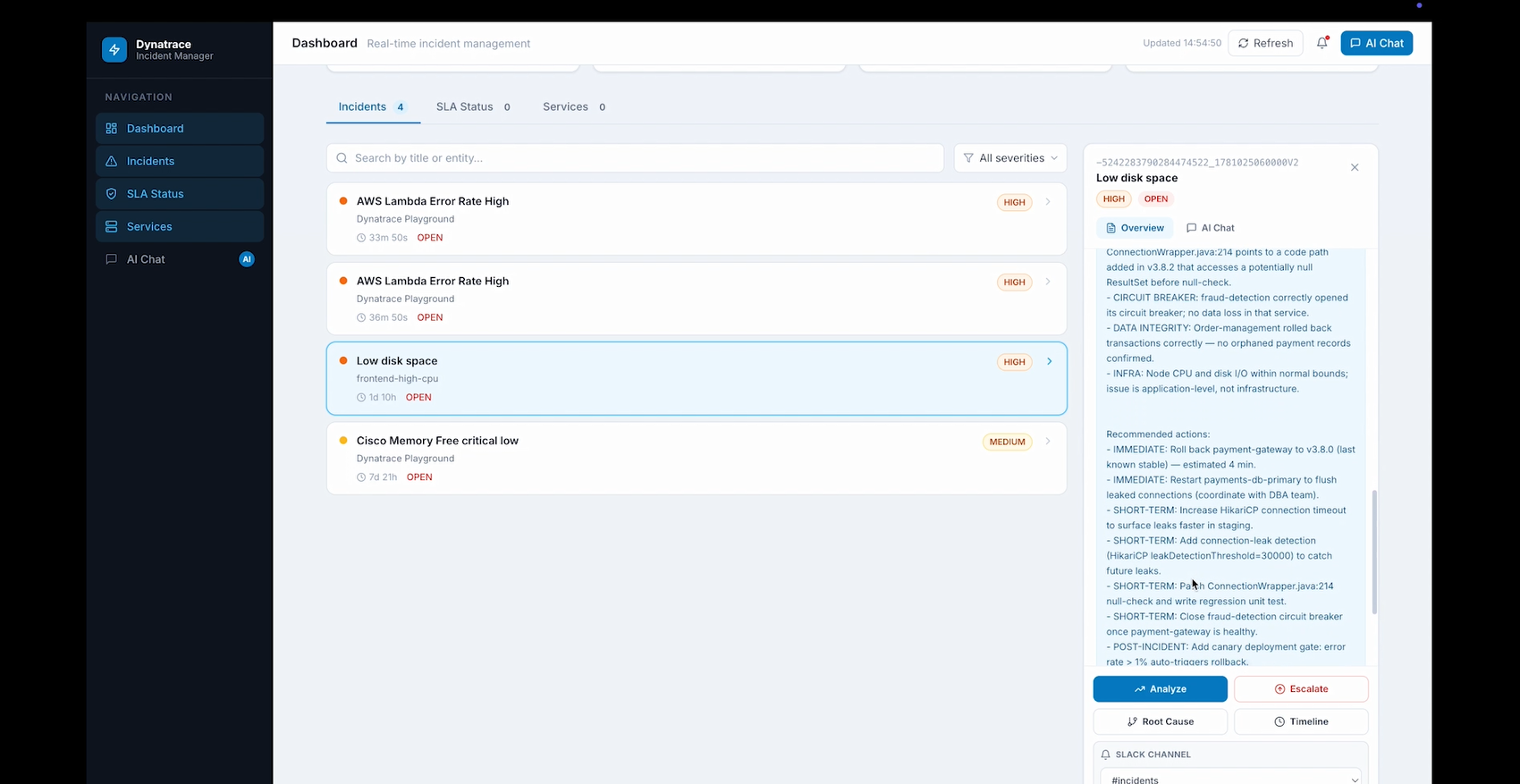
Analysis by Gemini
-
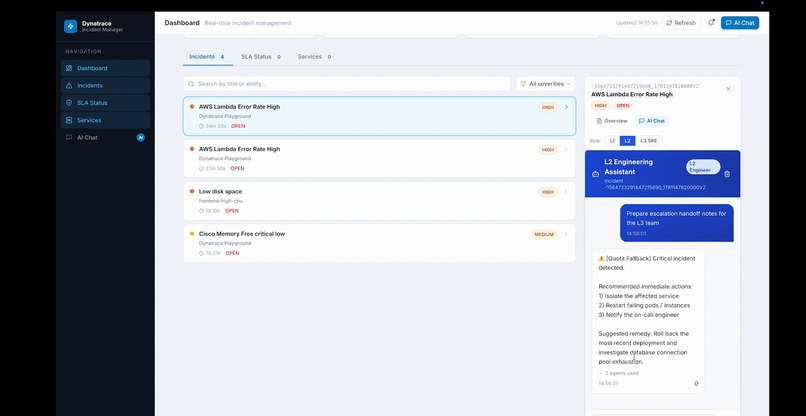
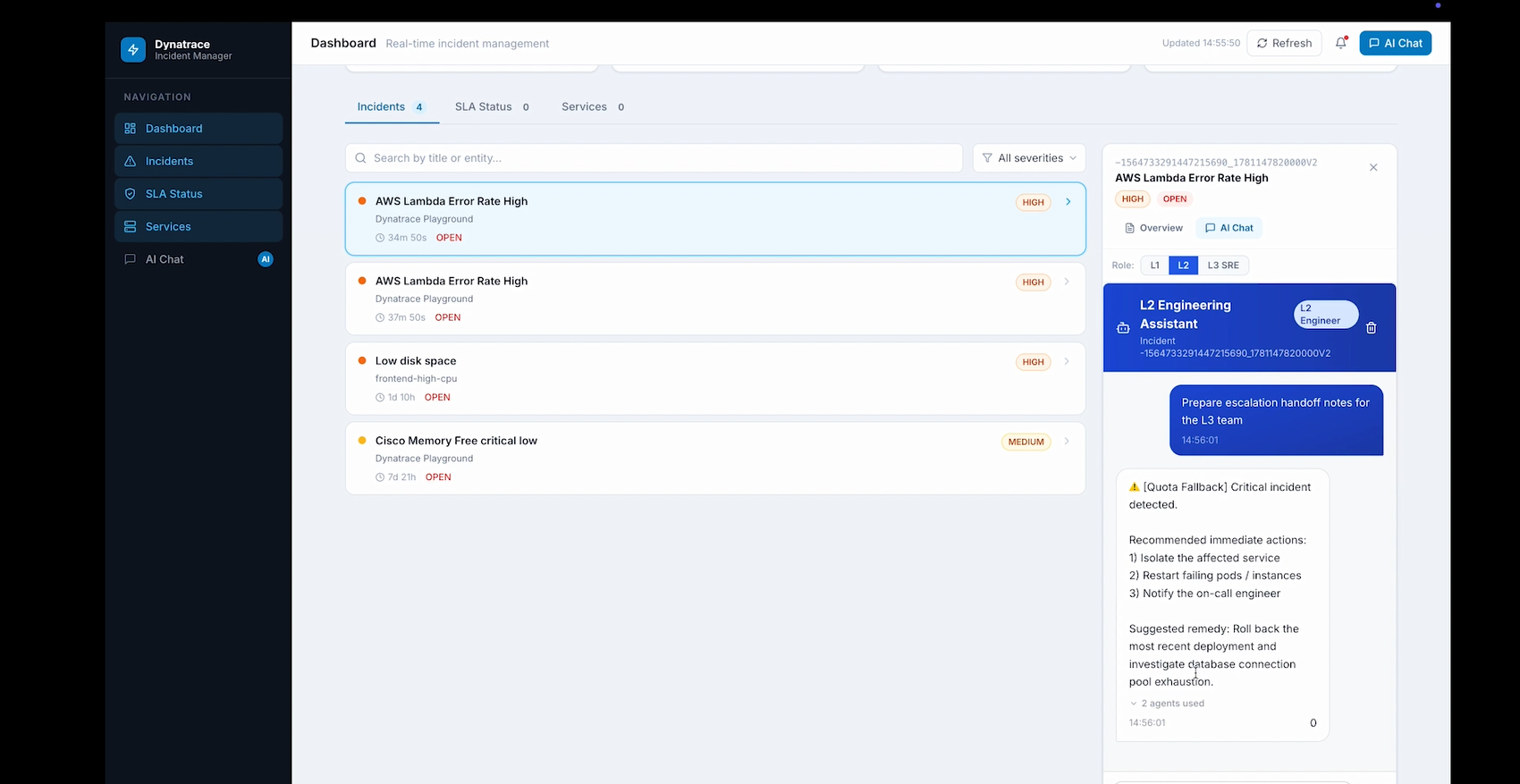
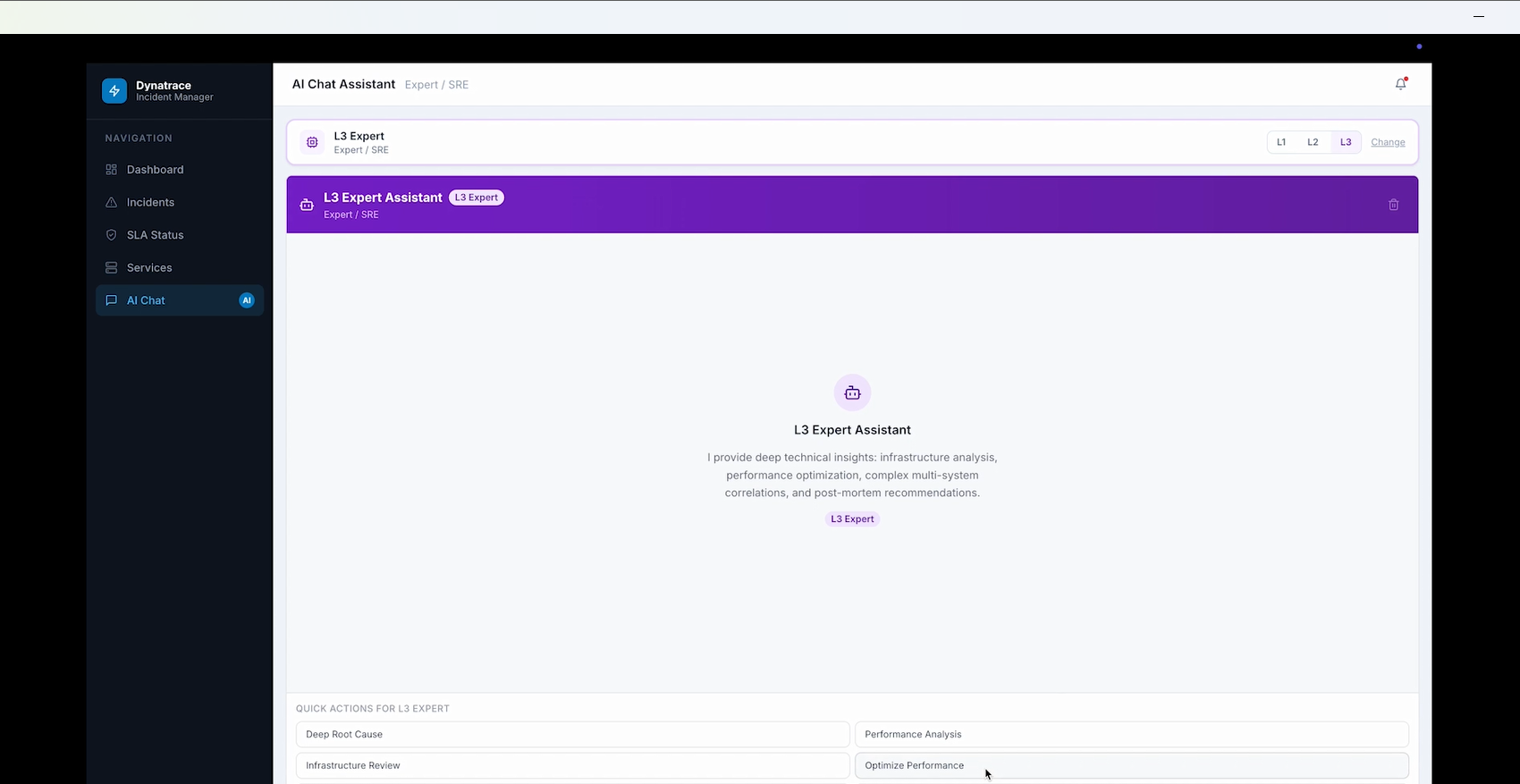
Hand off to L2/L3
-
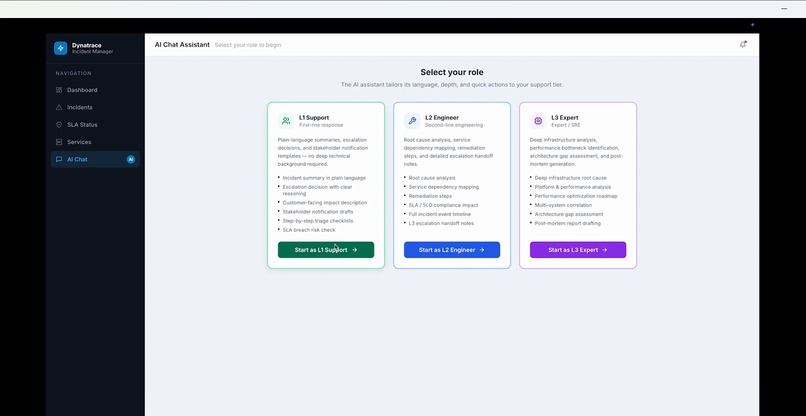
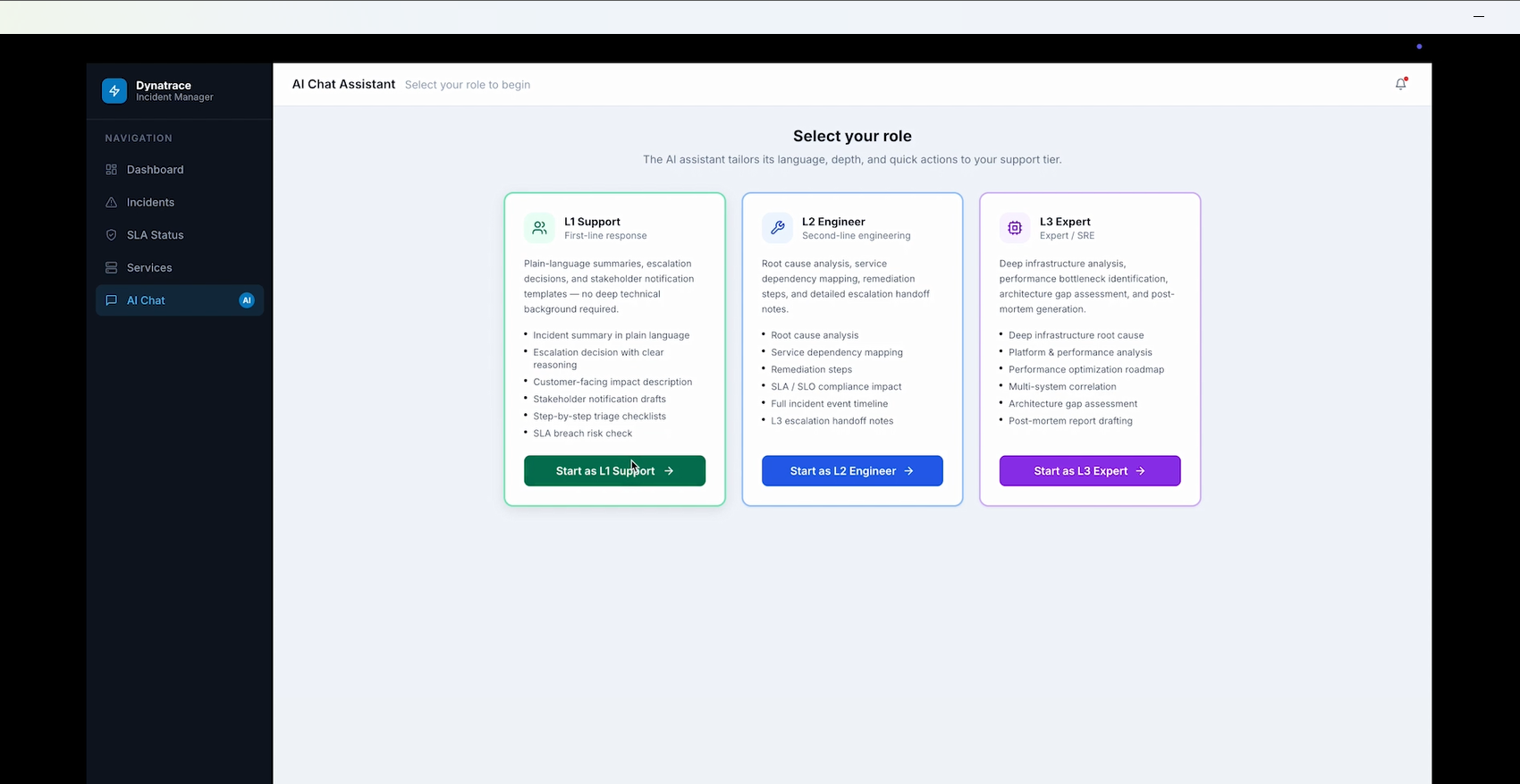
Support roles
-
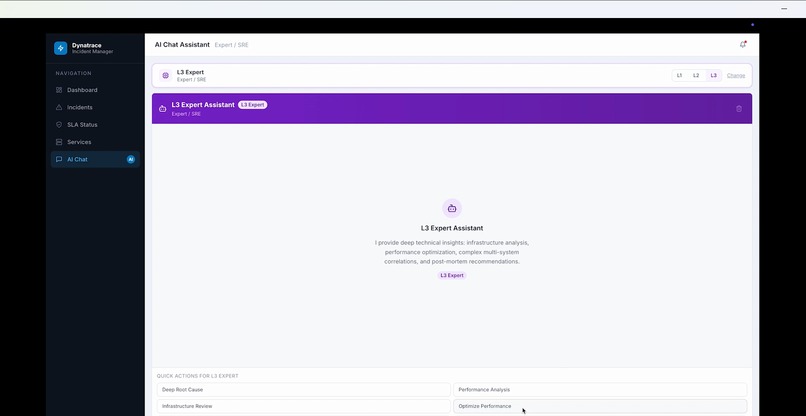
Interaction with AI chat
Inspiration
Every engineer on our team has lived the 2 AM nightmare — phone buzzing, adrenaline spiking, and the next hour vanishing into a blur of Dynatrace tabs, Slack pings, and frantic deployment log digs. The pain isn't the incident itself. It's the 60 minutes of manual detective work before you even know what's broken. We built IncidentCommanderAgent to eliminate that tax entirely.
What it does
IncidentCommanderAgent is an autonomous agent that compresses a full incident response cycle into 5 minutes: Detects open problems via Dynatrace MCP Analyzes root cause and ranks likely culprits by correlating deployment history within a ±2 hour window Drafts Slack war-room messages, email comms, and status page updates Generates a step-by-step on-call runbook and blameless post-mortem Posts the full AI analysis back into the Dynatrace problem card
How we built it
The stack is a multi-step agentic loop powered by three core layers: Alert ingestion .- Dynatrace MCP API (/problems, /entities) Intelligence - Google Gemini 1.5 Pro Output delivery - Slack API, Email, Dynatrace comment post-back
Gemini receives a grounded context object — real entity names pulled from the Dynatrace topology graph, deployment events, and RCA metadata — ensuring every analysis references services that actually exist, not hallucinated ones.
Challenges we ran into
Alert storm deduplication — Dynatrace can fire dozens of correlated problems in a cascade. We solved this by grouping alerts by rootCauseEntity and impactLevel before passing context to Gemini, collapsing noise into a single coherent incident.
Grounding Gemini in real topology — Early builds hallucinated plausible-sounding service names. We fixed this by injecting the live entity list from the Dynatrace topology API into every prompt, constraining the model to only reference services it was explicitly given.
Accomplishments that we're proud of
End-to-end agentic loop in a single workflow — We built a fully autonomous detect → analyze → communicate → document → post-back chain that requires zero human intervention from alert fire to post-mortem draft. Grounded AI analysis — By anchoring every Gemini call to live Dynatrace topology data, we eliminated hallucinations entirely. The agent only reasons about services and entities that actually exist in your environment.
What we learned
Building a truly agentic system means designing for failure at every step — a missed MCP call, a malformed Gemini response, or a race condition in the alert poller can silently break the whole chain. Robust context threading and structured JSON outputs (schema-enforced) were the difference between a demo that works once and one that works reliably under pressure.
What's next for IncidentCommanderAgent
PagerDuty and OpsGenie integration for alert routing Auto-remediation triggers for known failure patterns Trend analysis across post-mortems to surface recurring root causes before they become incidents

Log in or sign up for Devpost to join the conversation.