-
-

Incident Cast
Inspiration
When an incident hits, dashboards tell you what is broken, but never how anyone figured it out. The valuable part is the reasoning: competing theories, false leads, and the moment someone realizes “this is not load, this is a permission failure.” That process usually disappears into chat threads and war rooms before the retro even begins. We wanted to turn operational reasoning itself into a first-class, evidence-backed artifact built on real Splunk data instead of static slides.
What it does
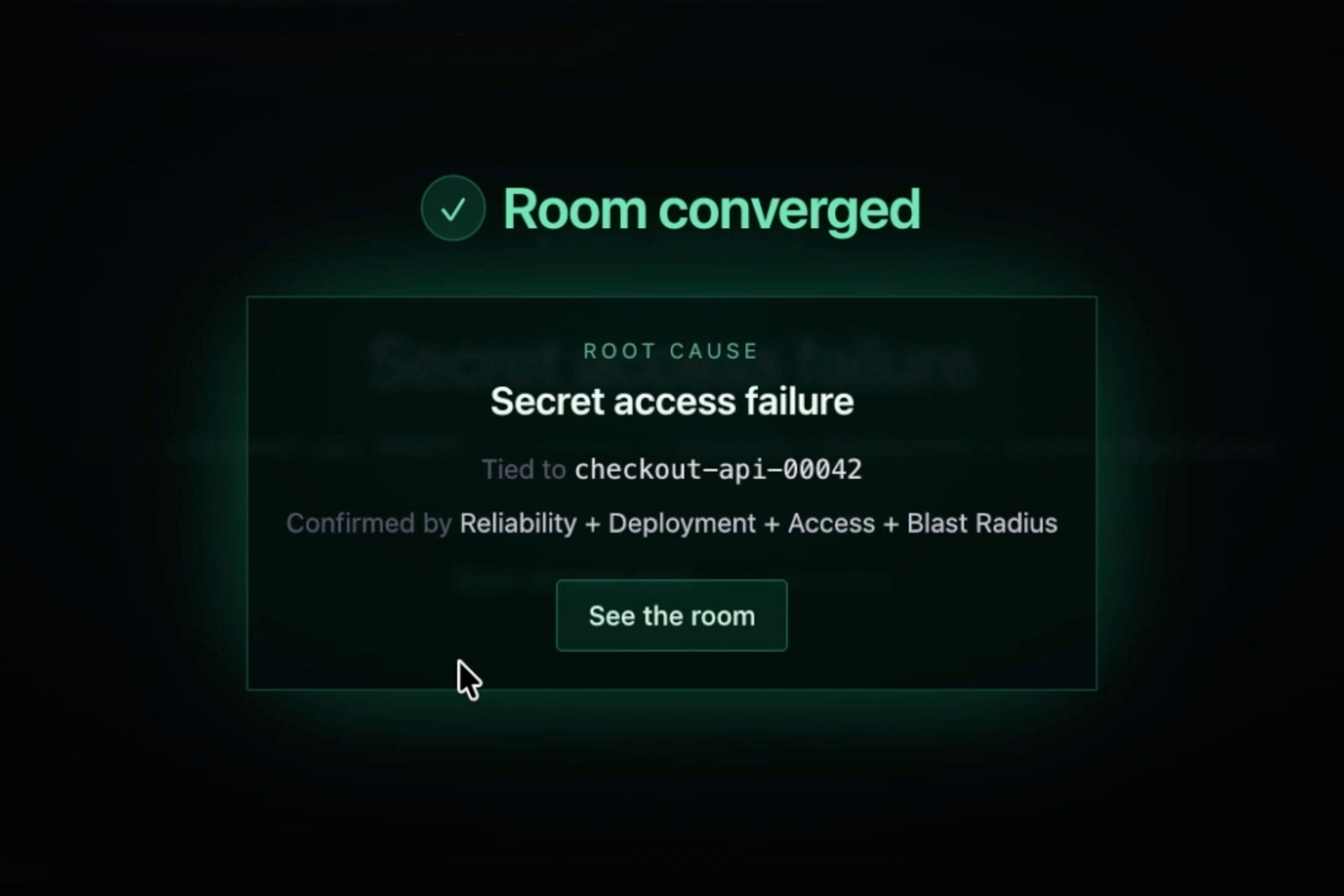
IncidentCast is a live incident reasoning room. When an incident triggers, four Splunk-powered specialists, Reliability, Deployment, Access, and Blast Radius, investigate the same incident from different angles. Theories rise and fall as evidence lands. Specialists disagree early, then gradually converge on one root cause only when the evidence supports it. Every claim is traceable to the exact SPL query and returned rows behind it, and any proof can be re-run live against Splunk through the Splunk MCP Server. The system ends with recommended next reviews, not automatic remediation, so humans stay in control.
For a deeper technical walkthrough of the investigation flow, Splunk MCP integration, and design decisions, read the full write-up here: https://medium.com/@michiyamamoto/incidentcast-watch-four-ai-specialists-argue-their-way-to-a-root-cause-and-prove-it-live-on-5393a3f96f57
How we built it
Operational scenarios are ingested into Splunk Enterprise through HEC across five indexes: app_logs, app_metrics, deploys, cloud_audit, and iam_changes. A shared QueryInterface protocol abstracts three interchangeable backends: Fixture, Splunk SDK, and Splunk MCP Server.
Two investigation paths sit on top of that interface. The cinematic replay path executes authored searches live and binds the returned rows, backend, and job_id directly into each finding. The autonomous-agent path runs four LLM specialists, each owning a non-overlapping SPL capability set. The specialists invoke the Splunk MCP Server’s splunk_run_query tool themselves and emit evidence-backed findings.
Convergence is determined by a rule-based aggregator rather than model confidence. Findings are clustered by shared entities, tags, and time windows until the room aligns on one explanation.
The frontend is built with Next.js 14, React, and TypeScript with zod-validated artifacts. The investigation room, evidence drawer, and Live Splunk Evidence modal expose the exact SPL, returned rows, backend source, and MCP execution details. The complete architecture diagram is included in the repository root.
Challenges we ran into
The hardest challenge was making the investigation feel genuinely live instead of like a pre-recorded report. Our first version revealed too much too early, which made convergence feel meaningless. We redesigned the entire experience around evidence progression: specialists begin with incomplete or incorrect theories, disagree visibly, and only converge once enough evidence accumulates.
Another challenge was maintaining a strict boundary between live Splunk execution and replayed evidence. The interface only displays the “live MCP executed” state when a real Splunk MCP call succeeds, while offline evidence is explicitly labeled as replayed data.
Keeping specialists independent was also difficult. We enforced “no overlapping query ownership” as a build-time validation instead of relying on prompt instructions alone.
Accomplishments that we're proud of
Splunk AI capabilities are used directly at runtime. The specialists invoke the official Splunk MCP Server’s splunk_run_query tool, and every investigation step can trigger a live, auditable MCP call from the UI.
Convergence is evidence-driven and deterministic rather than a model inventing confidence scores. Every claim is tied to a re-runnable SPL query and the exact rows Splunk returned.
At the same time, the system still works fully offline using committed investigation replays generated from those same searches, making the project easy to explore without infrastructure setup.
What we learned
We learned that convergence only feels meaningful when disagreement comes first. Operational reasoning has a real narrative structure: alert, divergence, evidence elimination, and convergence.
We also learned that AI systems become far more trustworthy when they are forced to expose their reasoning and evidence directly to humans instead of hiding behind summaries or confidence scores.
What's next for IncidentCast
We want to expand IncidentCast with additional incident archetypes such as noisy neighbors, certificate expiration, and dependency cascades. Future specialists will propose their own next searches dynamically instead of selecting from authored leads.
We are also exploring a shared hypothesis graph where candidate causes physically converge as evidence accumulates, along with collaborative replay modes designed for blameless retrospectives and operational training.
Built With
- hec
- json-rpc
- model-context-protocol
- next.js
- node.js
- pytest
- python
- react
- spl
- splunk-enterprise
- splunk-mcp-server
- splunk-sdk-for-python
- typescript
- yaml
- zod

Log in or sign up for Devpost to join the conversation.