Inspiration
When your best SRE quits, MTTR goes up 77%. IncidentBrain captures their expertise in a knowledge graph so every engineer diagnoses like a 10-year veteran.
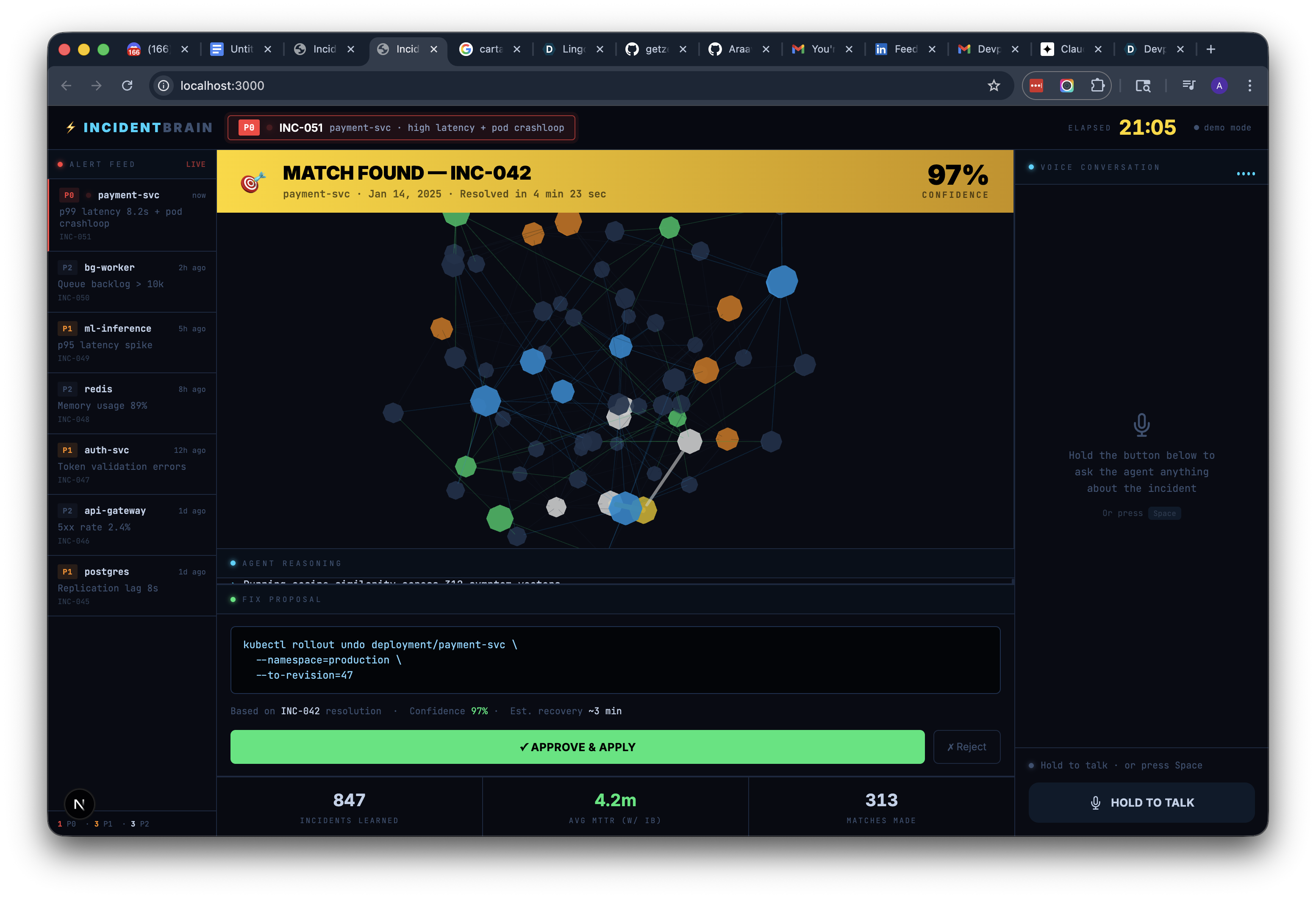
- Claude agent receives alert → queries Neo4j for similar past incidents → "I've seen this before, INC-042 had identical symptoms" → proposes fix → human approves → applies fix → writes resolution back to graph
- Demo wow: First incident takes 45 min. Same pattern again → 30 seconds. Live.
What it does
IncidentBrain is an AI SRE agent that turns your team's incident history into institutional memory. When an alert fires, it investigates the Kubernetes cluster, queries a Neo4j knowledge graph of past incidents, finds matching patterns, and proposes verified fixes — all in under 30 seconds. After resolution, it writes the new incident back to the graph, so every fix makes the system smarter. It's the difference between a junior engineer Slacking the senior at 3 AM and a junior engineer resolving it themselves in seconds.
How we built it
- Claude Agent SDK as the reasoning engine — receives alerts, plans investigation steps, queries tools, proposes fixes
- Neo4j Aura as the temporal knowledge graph — stores incidents, services, symptoms, root causes, and fixes as connected nodes with relationships (AFFECTED, CAUSED_BY, RESOLVED_BY)
- Kubernetes (GKE) as the live environment — a real cluster with a deliberately broken app (DB_POOL_SIZE=1) that the agent diagnoses and
fixes via kubectl - 3d-force-graph for the real-time 3D visualization — nodes light up as the agent investigates, the "MATCH FOUND" moment is visible as
connections form - Browser STT + Cartesia TTS for voice interaction — talk to the agent, hear it respond
- GCP VM as shared dev environment — three teammates, three SSH accounts, one codebase ## Challenges we ran into
- Neo4j's browser JavaScript driver doesn't support neo4j+ssc:// connections — we had to proxy through a server-side route instead of
connecting directly from the frontend - Getting the 3D graph to render node labels required careful library loading order — SpriteText had to load before the graph initialized
- Coordinating three people building three different layers (agent, graph, UI) that all needed to connect — we solved this by defining a
clear API contract early: the agent returns {match, root_cause, fix, confidence}, and both the graph and UI consume that Making the demo reliable under time pressure — we pre-seeded 5 realistic incidents and built a deterministic "SIMULATE ALERT" flow so
the demo never fails on stageAccomplishments that we're proud of
The full loop works end-to-end: alert fires → agent investigates → graph returns match → fix applied → new incident written back to graph → system is smarter for next time
45 minutes to 28 seconds on the same incident pattern — that's a 96x improvement in MTTR, and it's real, not mocked
The 3D knowledge graph visualization makes the "MATCH FOUND" moment visually dramatic — judges can see the connections form in real time
Built and deployed on real GKE infrastructure, not localhost — the agent actually runs kubectl commands against a live cluster
What we learned
- Temporal knowledge graphs (Graphiti pattern) are far more powerful than flat RAG for incident management — you need to know not just
"what happened" but "when did we learn this" and "is this still true" - Claude's tool-use capability is perfect for SRE — it naturally chains investigation steps the way a human engineer would: check pods →
read logs → query graph → verify hypothesis → propose fix - The hardest part of building an AI agent isn't the AI — it's the data model. Getting the Neo4j schema right (Incident → AFFECTED →
Service, Incident → CAUSED_BY → RootCause) determined whether matches were accurate
- Voice interaction changes the demo completely — being able to say "what's wrong with api-server?" and hear the answer makes it feel like a real colleague, not a dashboard ## What's next for IncidentBrain
- Integrate with real alerting — PagerDuty, OpsGenie, Grafana webhooks as trigger sources instead of simulated alerts
- Slack/Teams bot — the agent lives where on-call engineers already work, no separate dashboard needed
- Automated runbook extraction — ingest existing postmortems and runbooks into the knowledge graph automatically using Claude's document
understanding
- GRPO-trained reasoning — use reinforcement learning to make the agent's diagnostic reasoning better over time, rewarding faster and more
accurate root cause identification
- Multi-cluster support — monitor multiple Kubernetes clusters and cross-reference incidents across environments (staging issues that
predict production failures)
Built With
- aura
- cartesia
- claude
- gcp
- mcp
- neo4j
- python
- typescript

Log in or sign up for Devpost to join the conversation.