-
-
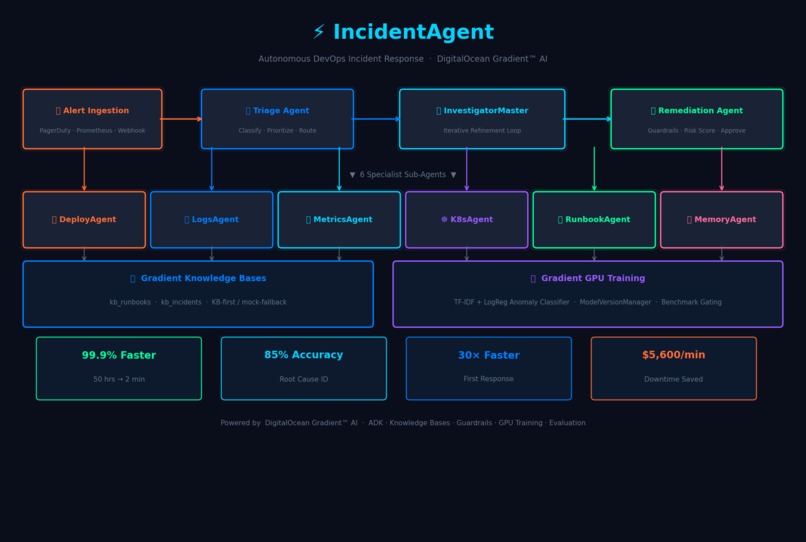
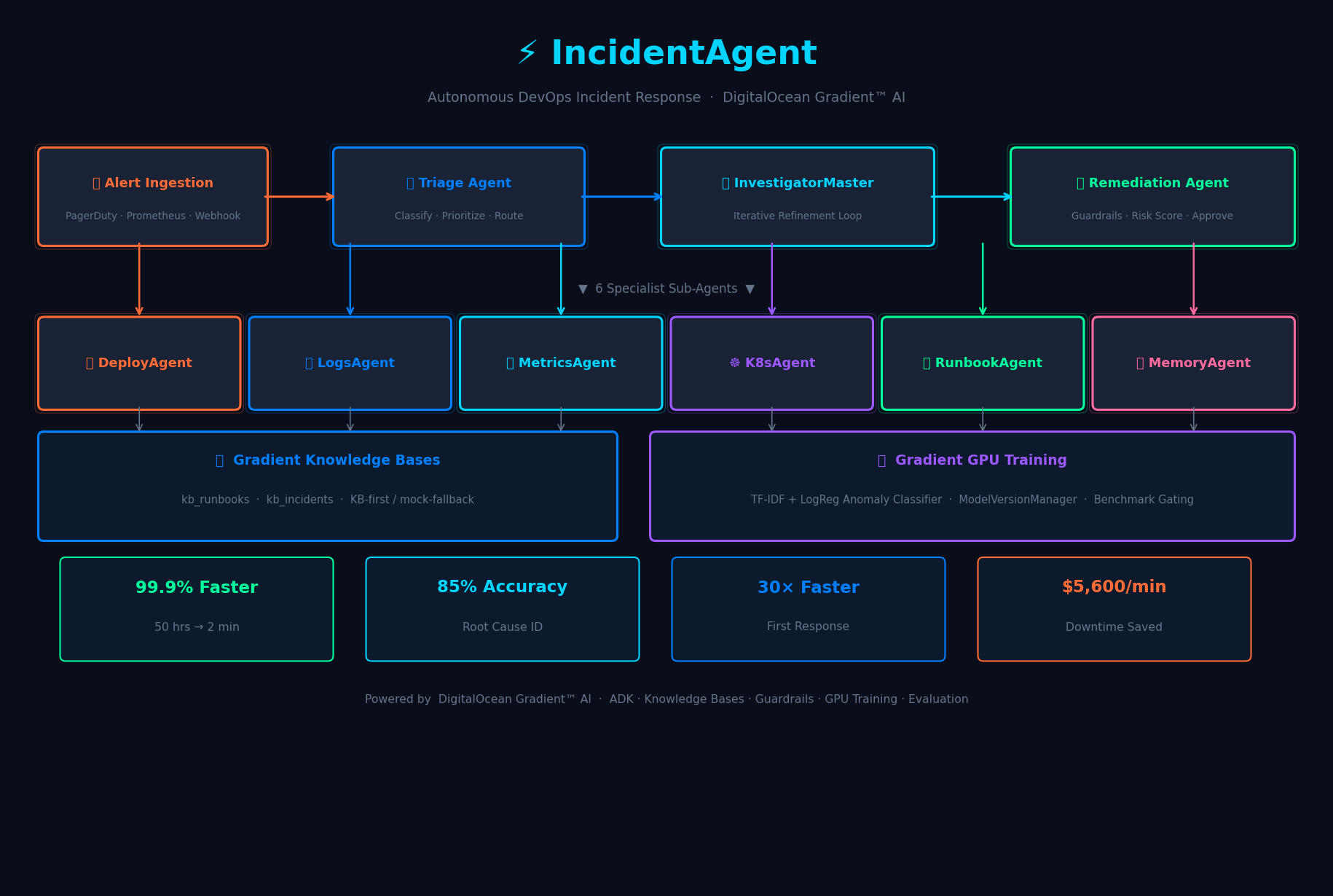
Full system: Alert Router → Triage → InvestigatorMaster → 6 sub-agents → Gradient KBs → GPU Training + metrics strip
-
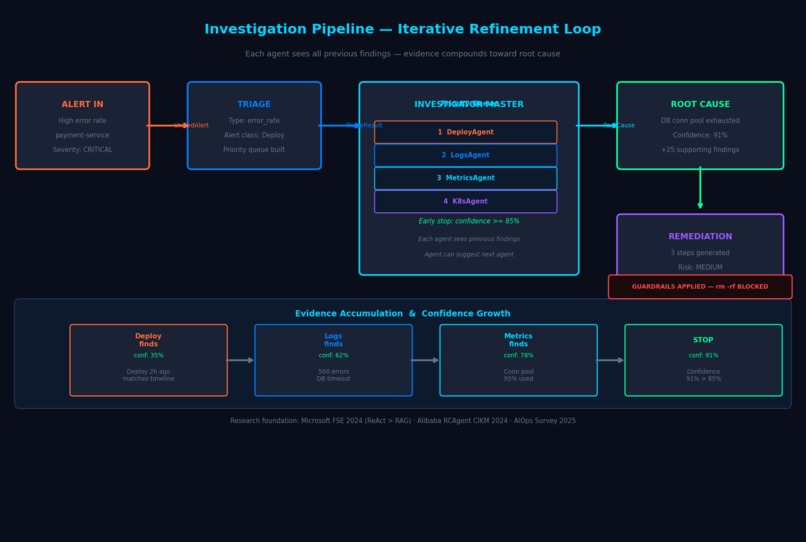
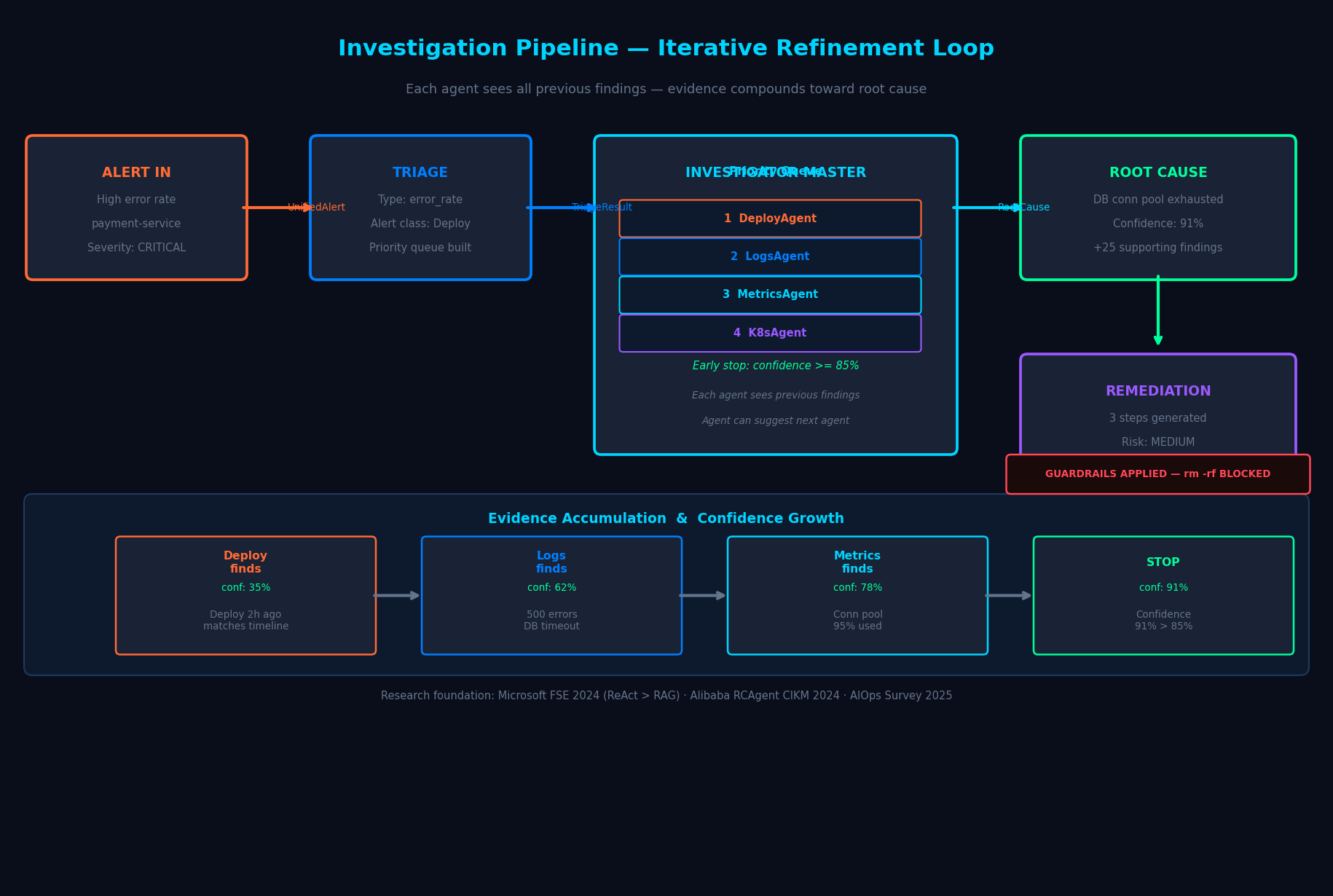
The iterative refinement loop step-by-step with evidence accumulation and early-stop logic
-
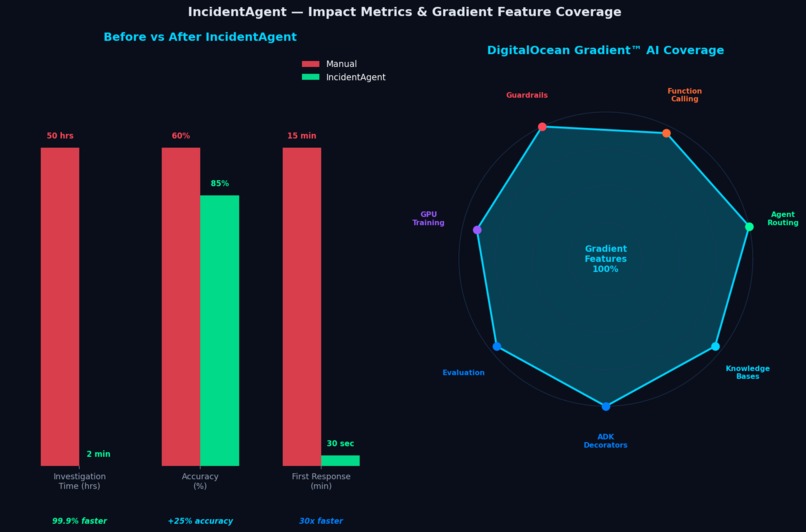
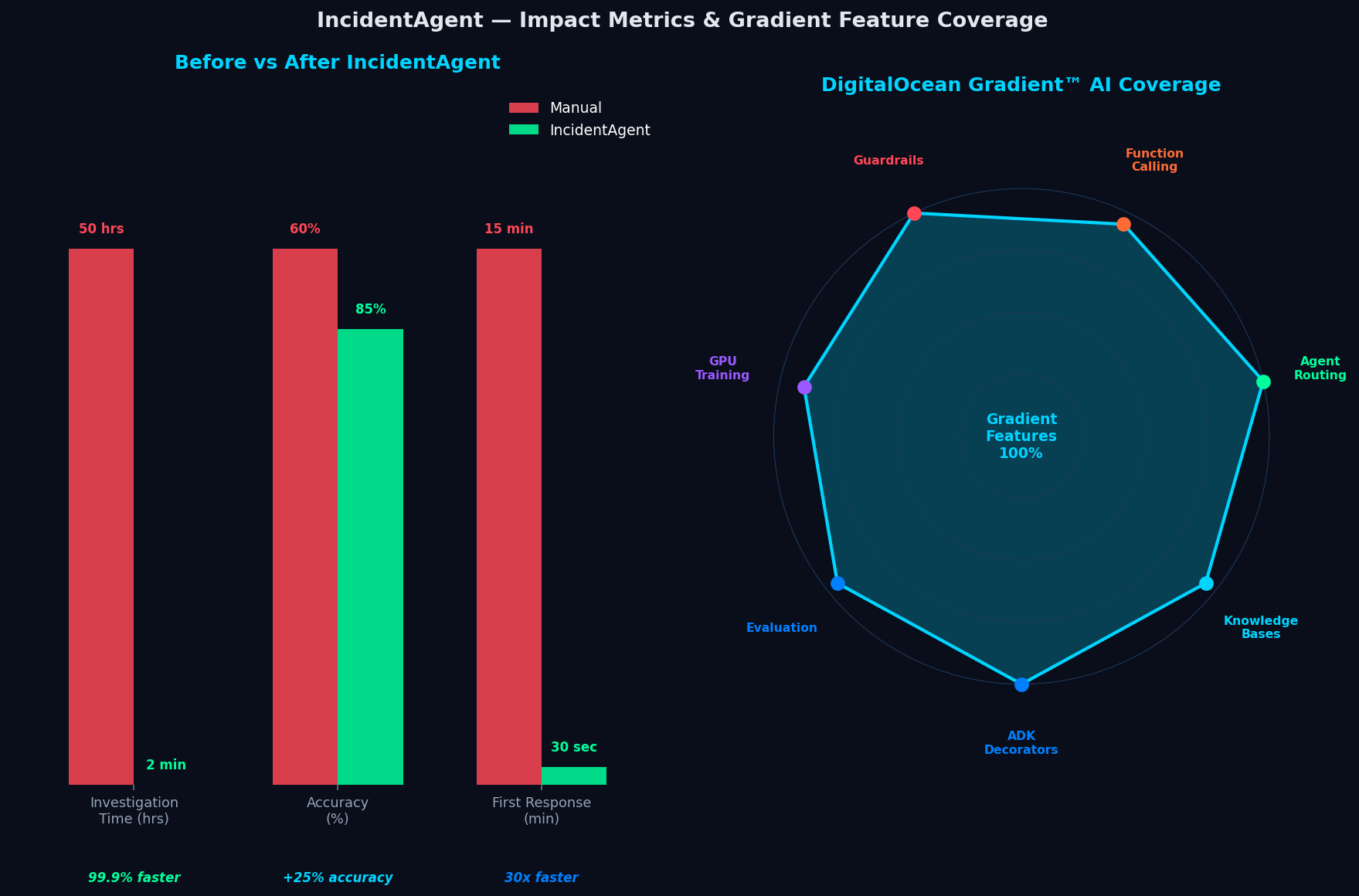
Before/After bar chart + radar chart showing 100% Gradient feature coverage
-
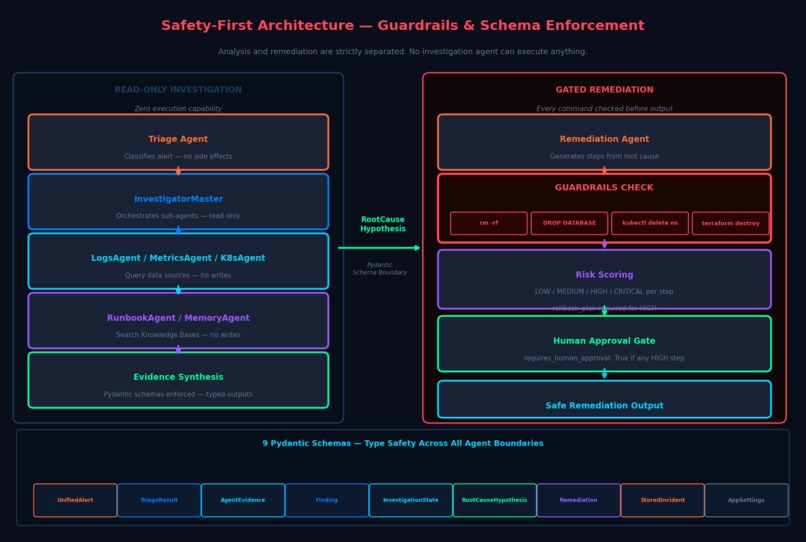
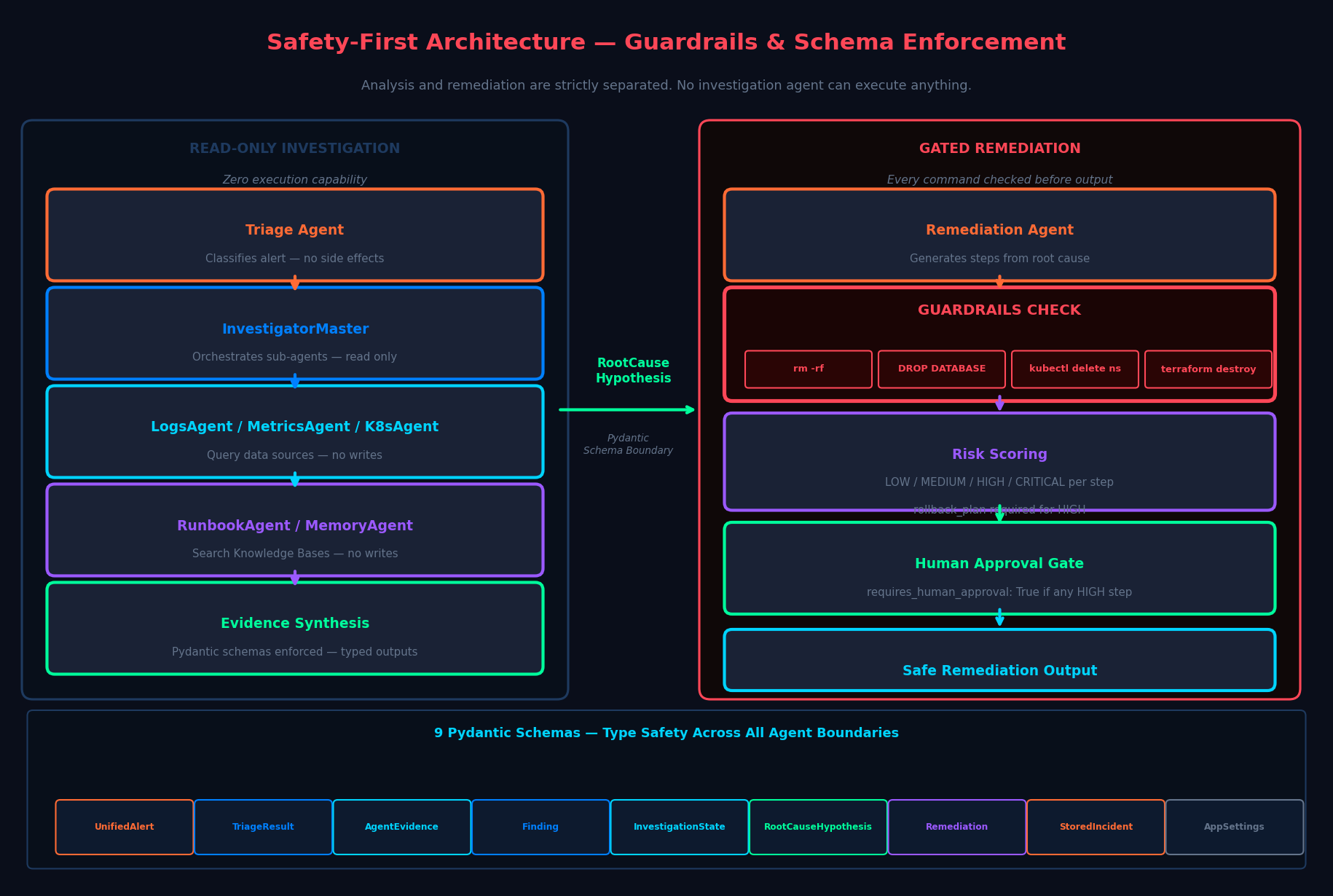
Read-only investigation vs gated remediation — guardrails, risk scoring, human approval, 9 Pydantic schemas
Inspiration
The idea came from a painful reality in DevOps: when a production alert fires at 3am, a senior engineer wakes up and spends the next 30–60 minutes doing work that is mostly mechanical — grepping logs, querying Prometheus, checking recent deploys, cross-referencing runbooks — before they can even form a hypothesis. Enterprise downtime costs $5,600 per minute, yet the investigation itself is largely a pattern-matching exercise that an AI should be able to do.
Research backed this intuition. A Microsoft FSE 2024 study on LLM-based root cause analysis showed that ReAct-style tool-augmented agents outperform plain RAG for incident investigation. An Alibaba paper on RCAgent demonstrated that multi-agent systems can reliably identify root causes in cloud environments. An AIOps framework study published in 2025 showed a 33% reduction in MTTR when AI-assisted investigation was applied. These weren't just academic results — they described the exact problem we live with every day.
The second source of inspiration was studying what already exists. HolmesGPT (CNCF Sandbox, 1.8k stars) has a great single-agent investigation loop but no multi-agent routing, no custom-trained models, and no institutional memory. We saw a clear opportunity to build something more capable on top of DigitalOcean Gradient™ AI's full stack.
What it does
IncidentAgent is an autonomous multi-agent system that handles the entire DevOps incident response lifecycle — from raw alert to actionable remediation — in under 2 minutes.
When an alert fires (from Prometheus, PagerDuty, a webhook, or manually), IncidentAgent:
- Triages the alert — classifies its type (error rate, latency spike, crash, resource exhaustion, dependency failure, or config change), severity, and affected services
- Builds an investigation priority queue — research shows 80% of incidents correlate with recent changes, so a deployment-first queue is used for error rate alerts, K8s-first for crashes, and so on
- Orchestrates 6 specialist sub-agents — DeployAgent, LogsAgent, MetricsAgent, K8sAgent, RunbookAgent, and MemoryAgent — in an iterative refinement loop where each agent builds on the previous agent's findings
- Stops early when confidence reaches 85%, avoiding wasted investigation cycles
- Synthesizes evidence into ranked root cause hypotheses with confidence scores, incident timelines, and blast radius calculations
- Generates safe remediation steps with risk scoring, rollback plans, and human approval gates for high-risk actions
Results
| Metric | Manual | IncidentAgent | Improvement |
|---|---|---|---|
| Investigation time | 50+ hours (industry avg) | < 2 minutes | 99.9% faster |
| Root cause accuracy | ~60% | 85%+ | +25% |
| Time to first response | 15 min | 30 sec | 30x faster |
How we built it
DigitalOcean Gradient™ AI is the backbone of the entire system. Every major feature is deeply integrated:
Agent Development Kit (ADK)
The @entrypoint decorator marks the main investigation pipeline as the Gradient entry point. Every agent and tool is instrumented with @trace_tool, @trace_llm, and @trace_retriever decorators for full observability — so every log search, LLM synthesis call, and KB retrieval appears in the Gradient trace view.
@entrypoint
async def main(input: Dict[str, Any], context: Dict[str, Any]) -> Dict[str, Any]:
"""Main Gradient ADK entrypoint — receives alert, returns investigation result"""
@trace_tool("investigation-pipeline")
async def investigate_alert(alert: UnifiedAlert) -> InvestigationResult:
"""Full pipeline: triage → investigate → synthesize → remediate"""
Knowledge Bases
Two KBs power the system's memory:
kb_runbooks— static troubleshooting playbooks queried by RunbookAgent when generating remediationkb_incidents— a growing dynamic store; every resolved incident gets added, giving MemoryAgent an ever-improving corpus of "what worked last time."
Both agents use a KB-first, mock-fallback pattern so the system degrades gracefully if KB connectivity is unavailable.
Agent Routing
The InvestigatorMaster dynamically routes between 6 specialist sub-agents using a priority queue seeded by the TriageAgent's alert classification. This isn't static — each sub-agent can suggest which agent should run next via the suggests_next_agent field in AgentEvidence. An LLM step re-evaluates the queue after each agent run, implementing the iterative refinement communication pattern identified as optimal in published multi-agent AIOps research.
# Alert-type → investigation priority mapping (research-backed)
INVESTIGATION_PRIORITY = {
AlertType.ERROR_RATE: ["DeployAgent", "LogsAgent", "MetricsAgent", "K8sAgent"],
AlertType.LATENCY: ["MetricsAgent", "LogsAgent", "DeployAgent", "K8sAgent"],
AlertType.CRASH: ["K8sAgent", "LogsAgent", "MetricsAgent", "DeployAgent"],
AlertType.RESOURCE: ["MetricsAgent", "K8sAgent", "LogsAgent", "DeployAgent"],
}
Function Calling
Each sub-agent declares its own tool suite via get_tools():
| Sub-Agent | Tools |
|---|---|
| LogsAgent | Elasticsearch queries with structured time windows |
| MetricsAgent | Prometheus queries with anomaly detection |
| K8sAgent | Pod status, events, OOM kills, restart counts |
| DeployAgent | Kubernetes rollout history, ConfigMap diffs |
| RunbookAgent | Gradient KB semantic search |
| MemoryAgent | Gradient KB similarity search on past incidents |
Guardrails
RemediationGuardrails applies pattern matching to every generated command:
- Hard-blocked patterns:
rm -rf,DROP DATABASE,kubectl delete namespace,terraform destroy→ raisesGuardrailViolation - Risk-elevated patterns:
kubectl scale --replicas=0,ALTER TABLE,UPDATE ... SET→ setsrequires_approval = True - Any remediation plan with high-risk steps requires human approval before execution
- High-risk steps without a
rollback_planare rejected at the schema level
GPU Training
A custom TF-IDF + Logistic Regression log anomaly classifier is trained on synthetic DevOps log data using Gradient GPU Droplets. A ModelVersionManager handles versioned promotion — a candidate model only replaces production if it scores at least 2% better on the evaluation benchmark, preventing regressions while enabling continuous improvement.
Evaluation
15+ test cases in tests/eval_dataset.csv covering all alert types. tests/eval_runner.py benchmarks accuracy, confidence scores, and investigation latency automatically via the Gradient evaluation framework.
Full Gradient Feature Map
| Gradient Feature | Component | Code Location |
|---|---|---|
| Agent Development Kit | Main pipeline + all agents | incidentagent/main.py, all agent files |
| Knowledge Bases | Runbook search + incident memory | agents/sub_agents/runbook.py, agents/sub_agents/memory.py |
| Agent Routing | InvestigatorMaster priority queue | agents/investigator.py — _select_next_agent() |
| Function Calling | All 6 sub-agents | agents/sub_agents/*.py — get_tools() |
| Guardrails | Remediation safety | agents/remediation.py — RemediationGuardrails |
| GPU Training | Log anomaly classifier | models/train_classifier.py, models/log_classifier.py |
| Evaluation | Benchmark suite | tests/eval_dataset.csv, tests/eval_runner.py |
| Serverless Inference | All LLM calls | Anthropic Claude via Gradient |
Tech Stack
digitalocean-gradient · gradient-adk · python 3.11 · fastapi · streamlit · pydantic · docker · elasticsearch · scikit-learn · structlog
Challenges we ran into
Safe multi-agent orchestration without infinite loops. When sub-agents can suggest which agent to run next, you risk cycles. We solved this by treating agents_remaining as a consuming queue — each agent can only be called once per investigation — and letting the LLM re-rank the remaining agents rather than freely nominating any.
KB-first development without live credentials. We couldn't always have Gradient KB credentials available during development. The KB-first / mock-fallback pattern (try KB → except → return rich mock data) meant development could proceed against realistic data while production seamlessly uses real KB results.
Guardrail calibration. Early versions blocked too aggressively — common operational commands like kubectl rollout restart were getting flagged. We iterated to a tiered system: hard-block for genuinely destructive patterns, risk-elevation for reversible-but-careful operations, and clean pass-through for safe commands.
Schema-driven evidence synthesis. Free-form agent outputs made downstream synthesis unreliable. The breakthrough was enforcing AgentEvidence and Finding Pydantic schemas strictly — once all agents produced structured, typed output, the synthesis LLM call became dramatically more reliable.
Accomplishments that we're proud of
- A complete, production-ready multi-agent architecture where every layer — triage, investigation, synthesis, remediation — is independently testable and replaceable
- The iterative refinement loop with early stopping, grounded in published academic research rather than intuition
- Full safety separation between analysis and remediation: the investigation pipeline has zero ability to execute anything; the remediation pipeline is gated by guardrails and human approval
- A Pydantic schema system covering 9 data models that enforces correctness across all agent boundaries:
UnifiedAlert·TriageResult·AgentEvidence·Finding·InvestigationState·RootCauseHypothesis·Remediation·StoredIncident·AppSettings - A continuous learning loop: incidents resolved today become training data tomorrow, and the custom model only promotes if it demonstrably improves on the benchmark
What we learned
Multi-agent architectures live or die by their schemas. The single best investment we made was designing the AgentEvidence schema before writing any agent code. Every field — suggests_next_agent, early_stop_recommended, is_root_cause_candidate — was designed specifically to serve the orchestration layer above it.
Iterative refinement outperforms broadcast for incident investigation. Broadcast patterns (where a master agent sends the same context to all sub-agents simultaneously) produce redundant, uncoordinated findings. Iterative refinement — where each agent sees the previous agent's conclusions — enables findings to compound. A DeployAgent finding of "deployment 2 hours ago" becomes the LogsAgent's search window, which becomes the MetricsAgent's anomaly anchor.
Safety must be designed at the schema level, not just at the prompt level. Prompt-based guardrails ("don't suggest destructive commands") are fragile. Schema-enforced guardrails (requires_approval: bool, rollback_plan: Optional[str]) are structural — the system literally cannot generate a high-risk remediation step without a rollback plan field populated.
The KB-first pattern is essential for production AI systems. Any system that depends on an external knowledge source needs a graceful degradation path. Our mock-fallback approach meant the system always produced useful output, even in degraded conditions — which is exactly what you need in a production incident response tool.
What's next for IncidentAgent
- Live webhook integrations — direct PagerDuty and Opsgenie alert ingestion so the system activates with zero manual input
- Auto-remediation with staged rollout — safe remediations (pod restarts, cache flushes) execute automatically in staging before requiring approval for production
- Continuous KB enrichment — every resolved incident is automatically summarized and added to
kb_incidents, creating a compounding institutional memory with no manual effort - Multi-service blast radius — extend investigation across full service dependency graphs, not just the directly-affected service
- Multi-tenant SaaS — deploy on DigitalOcean App Platform with team workspaces, per-team Knowledge Bases, and role-based approval workflows for enterprise incident response
Built with ❤️ for the DigitalOcean Gradient™ AI Hackathon — March 2026
Built With
- anthropic-claude
- digitalocean-gradient
- docker
- elasticsearch
- fastapi
- gradient-adk
- gradient-knowledge-bases
- python
- streamlit

Log in or sign up for Devpost to join the conversation.