-
-
Flow in AI Catalog
-
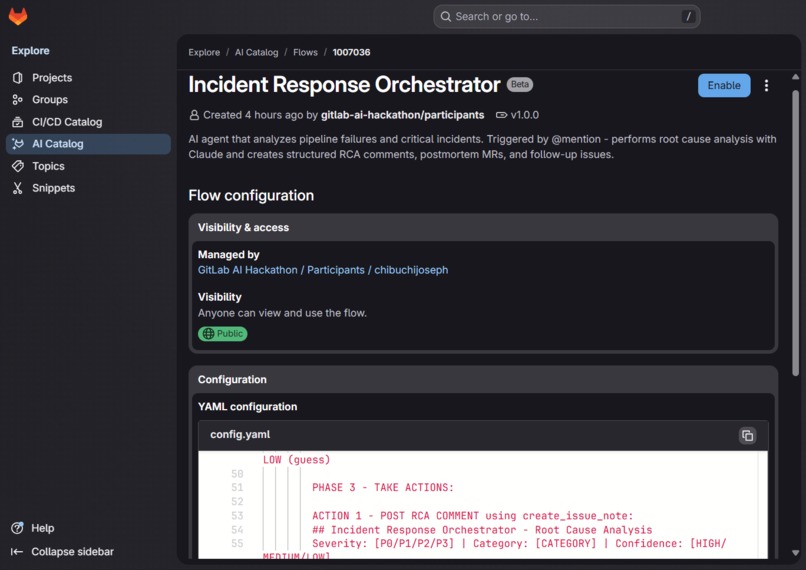
YMAL file
-
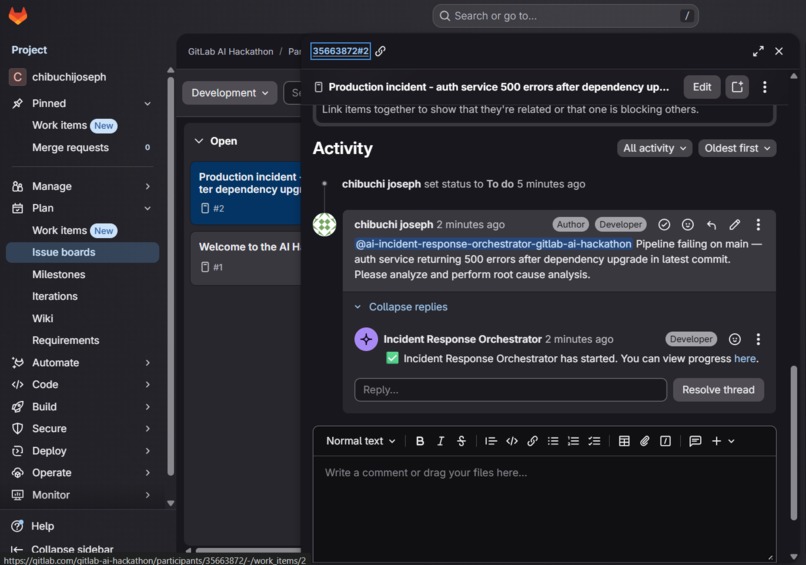
Session Running
-
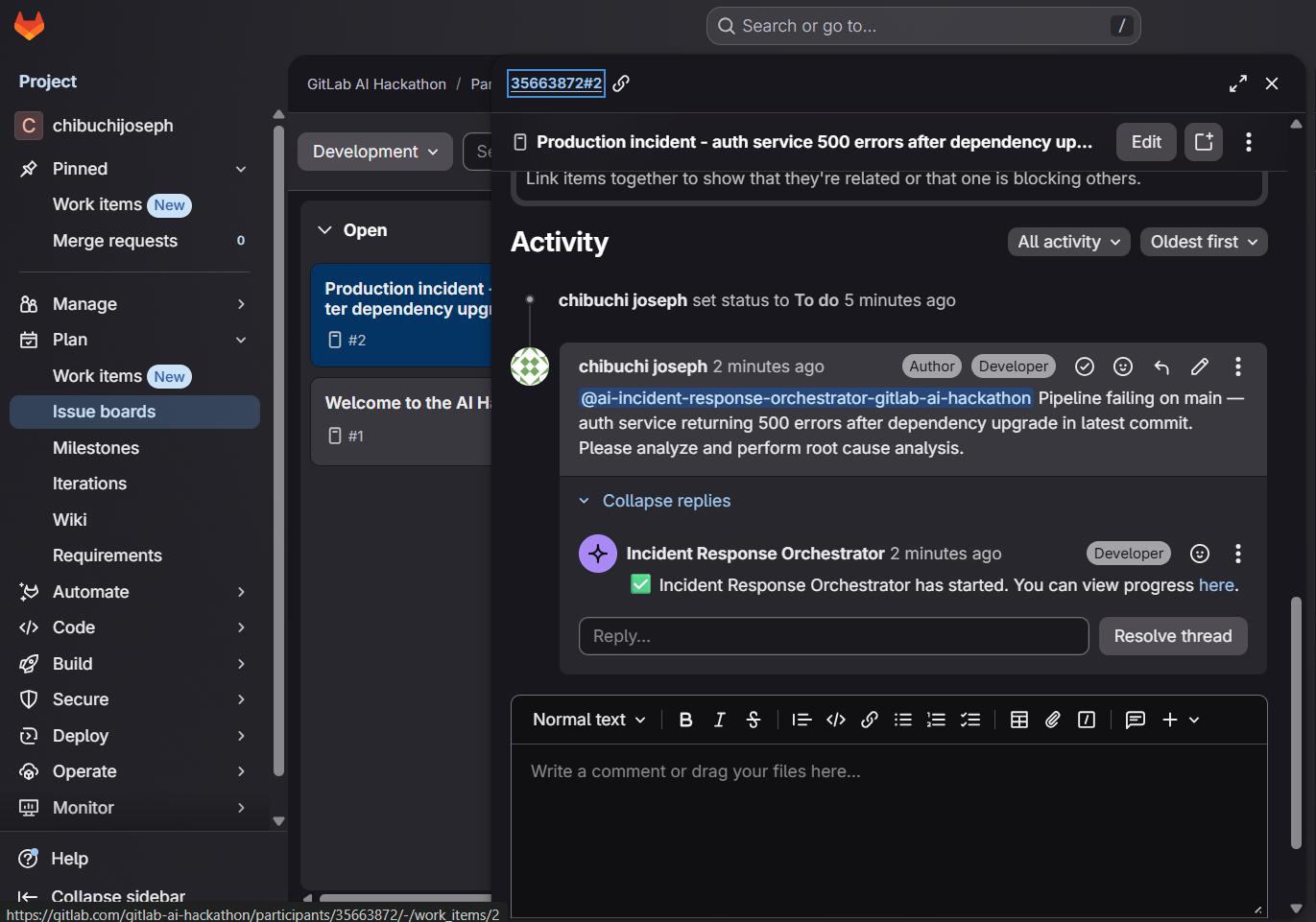
RCA Comment Output
-
Project Repository
-
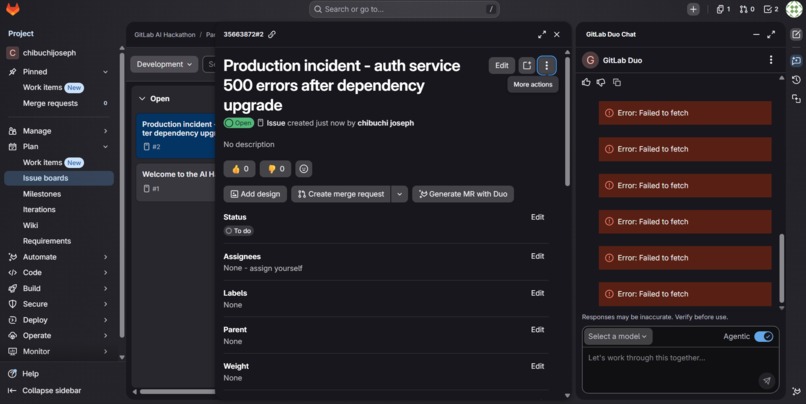
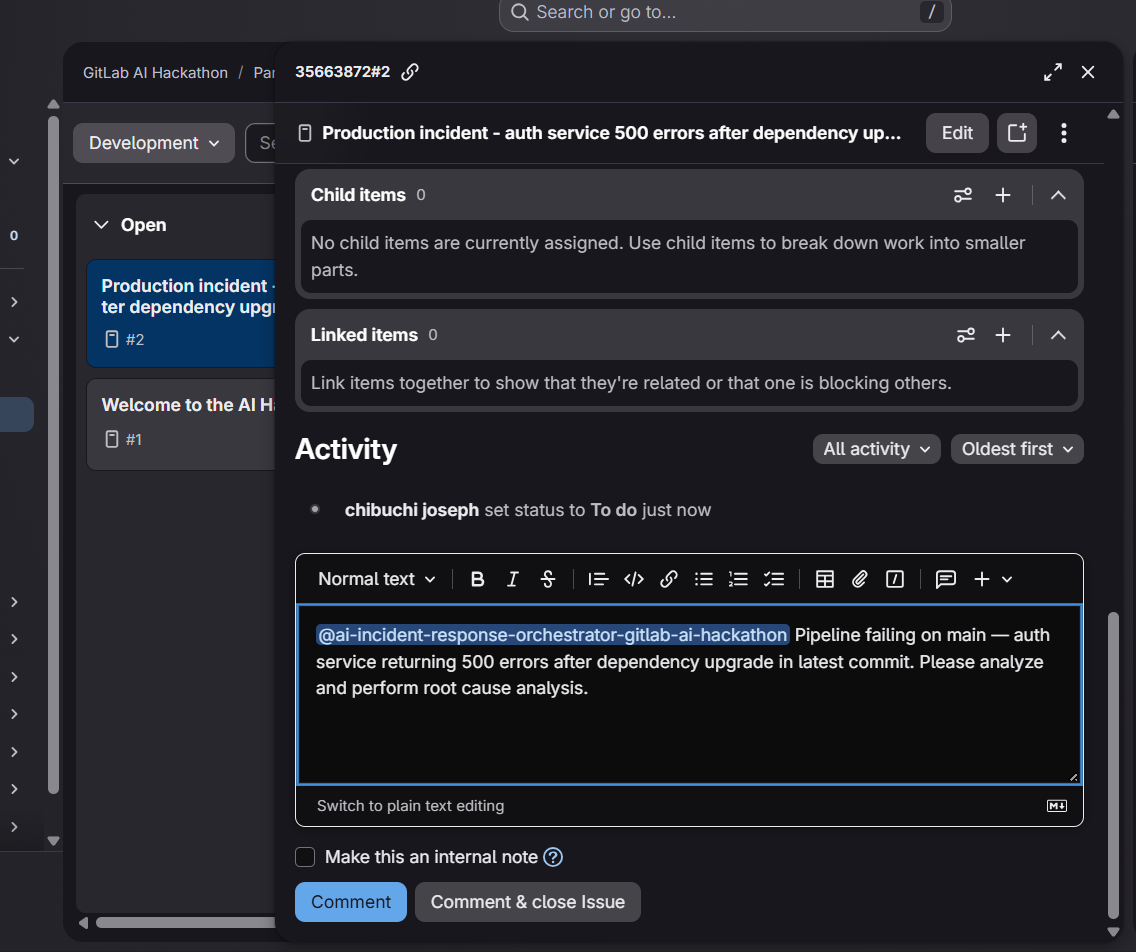
Triggering the agent
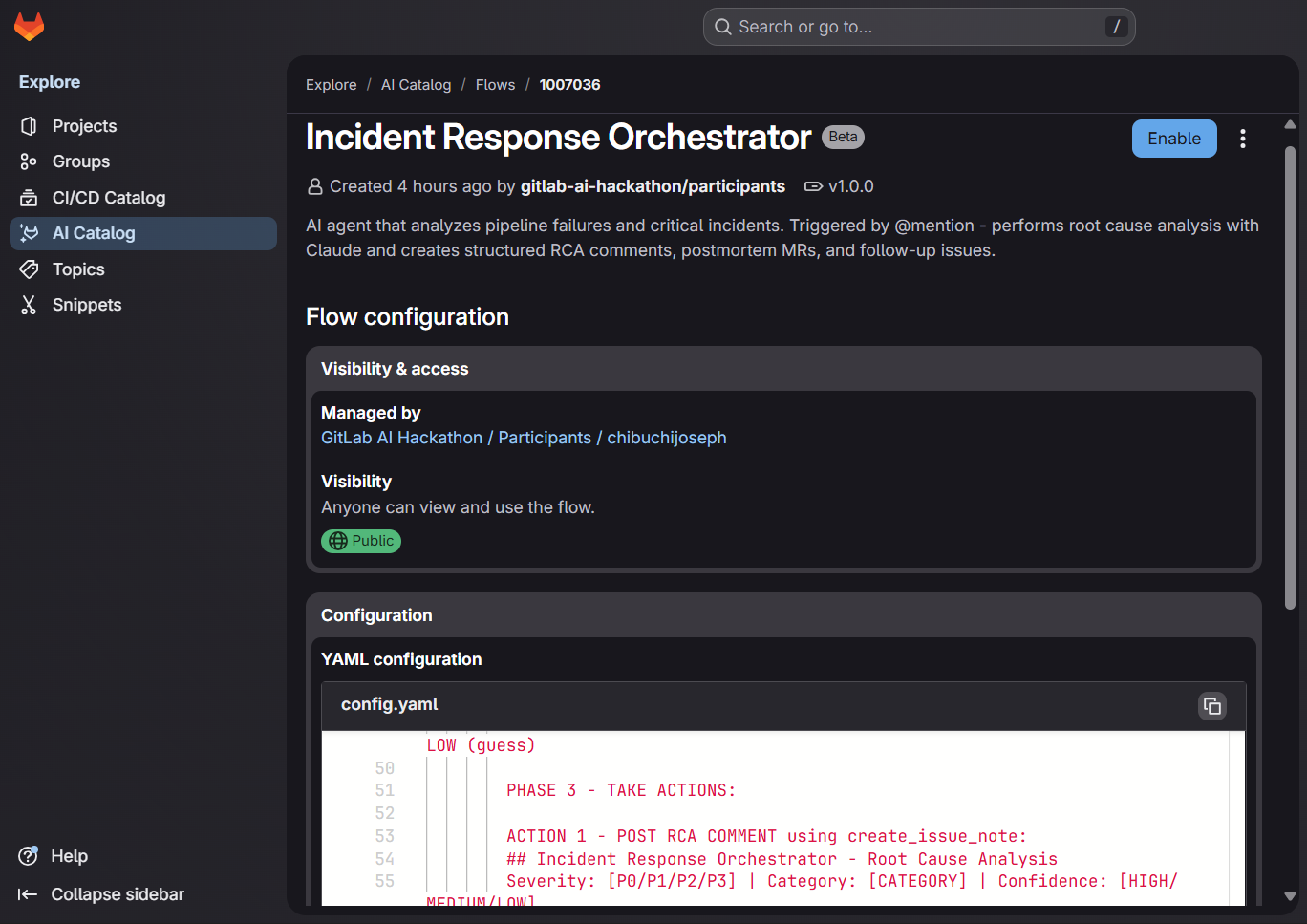
Inspiration
Modern engineering teams still handle incident response manually—despite it being repetitive, time-consuming, and highly automatable. When a production failure happens, engineers spend hours digging through logs, correlating commits, and writing postmortems.
We were inspired by this gap: why are teams still spending 1–3 hours on something AI can solve in seconds?
The goal was to eliminate this bottleneck entirely and build an autonomous system that can detect, analyze, and respond to incidents instantly.
What it does
Incident Response Orchestrator is an autonomous AI agent that handles the entire incident response lifecycle in under 30 seconds.
When a failure occurs, it automatically:
- Detects pipeline failures or critical incidents.
- Collects logs, commits, test results, and historical context.
- Performs multi-document root cause analysis using AI.
- Assigns severity and confidence levels.
- Posts a structured RCA (Root Cause Analysis).
- Generates a draft postmortem.
- Creates follow-up issues.
- Optionally opens auto-fix merge requests (when safe).
- Sends real-time Slack alerts.
- Tracks MTTR for analytics.
In short: it replaces hours of manual incident response with a fully automated workflow.
How we built it
We built the system using the GitLab Duo Agent Platform, leveraging its three core pillars:
- Triggers Pipeline failures Critical issue creation External webhooks (PagerDuty, Datadog) Scheduled health checks
- Context Gathering
We aggregate multiple sources in parallel:
Pipeline logs Recent commits and diffs Merged MRs Historical incidents and postmortems Test results
- AI Reasoning Used Anthropic Claude (Sonnet & Haiku) for multi-document reasoning Designed a structured 7-step reasoning framework Implemented: Severity-based model routing Confidence scoring (HIGH / MEDIUM / LOW) Adversarial second-pass validation Dual-model consensus for critical incidents
- Actions Layer GitLab API for issues, MRs, comments Slack notifications via Block Kit OSV API for vulnerability enrichment
The system is modular, with 18 Python components, orchestrated through a central workflow engine.
Challenges we ran into
- Obtaining access to the GitLab AI Hackathon group took time due to errors in the initial access form submission, which reduced our available development time..
- Pipeline was failing due to some errors (Ranging from: tool_name is missing, tool_name field at all, difficulty finding .gitlab-ci.yml, CONST must be equal to constant, toolset is missing here! ) but was ready to merge, so i had to look tool_mapping.json file to get a better understanding.
- Multi-document reasoning complexity.
- Combining logs, commits, and historical incidents into a single coherent analysis required careful prompt engineering.
- Avoiding incorrect automation
A wrong RCA during a critical incident can be worse than no RCA. We solved this with:
- Confidence scoring.
- Adversarial second-pass reasoning
- Mandatory human review on low confidence
- Latency vs completeness trade-off Gathering rich context while staying under 30 seconds required parallelization and strict limits.
- Model cost and efficiency
Running large models for every incident was expensive, so we implemented:
- Smart routing (Sonnet vs Haiku)
- Heuristic filtering
Accomplishments that we're proud of
- 🚀 Reduced incident response time from 1–3 hours → under 30 seconds.
- 🧠 Built a true multi-document reasoning system, not just summarization.
- 🛡️ Designed a safe automation system with confidence-aware decision making.
- ⚡ Implemented end-to-end automation: detection → RCA → fixes → reporting.
- 🌱 Added AI efficiency tracking and energy-aware routing.
- 📊 Created a self-improving system with MTTR analytics and feedback loops.
What we learned
- AI is most powerful when applied to structured workflows, not just chat interfaces.
- Context quality matters more than model size.
- Safe automation requires guardrails, not just intelligence.
- Multi-agent/tool systems need clear orchestration and boundaries.
- Observability (metrics, trends) turns automation into continuous improvement.
What's next for Incident Response Orchestrator
- 🔄 Real-time streaming incident analysis (instead of batch processing).
- 🤝 Deeper integrations with tools like Jira, AWS CloudWatch, and Kubernetes.
- 🧩 Expanded auto-fix capabilities beyond config and dependency issues.
- 📈 Predictive incident prevention using historical patterns.
- 🧑🤝🧑 Team collaboration layer (approval workflows, human-in-the-loop UI).
- 🌍 Cross-organization learning for shared incident intelligence
Built With
- anthropic-claude-(sonnet-4
- ci/cd-logs
- flask
- git-history
- gitlab-api
- gitlab-duo-agent-platform
- incident-issues-and-postmortems
- osv-vulnerability-database
- python-3.12
- slack-block-kit-webhooks

Log in or sign up for Devpost to join the conversation.