-
-
01-state-normal.png
-
discord_stats.png
-
02-state-chaos-cache.png
-
03-state-chaos-graceful.png
-
github_repo.png
## 💡 Inspiration
What if the AI agent itself becomes the incident?
Most "AI for DevOps" demos assume the LLM is always available. But the TrueFoundry Resilient Agents Challenge asked the opposite question: what happens to the user when the AI infrastructure goes down?
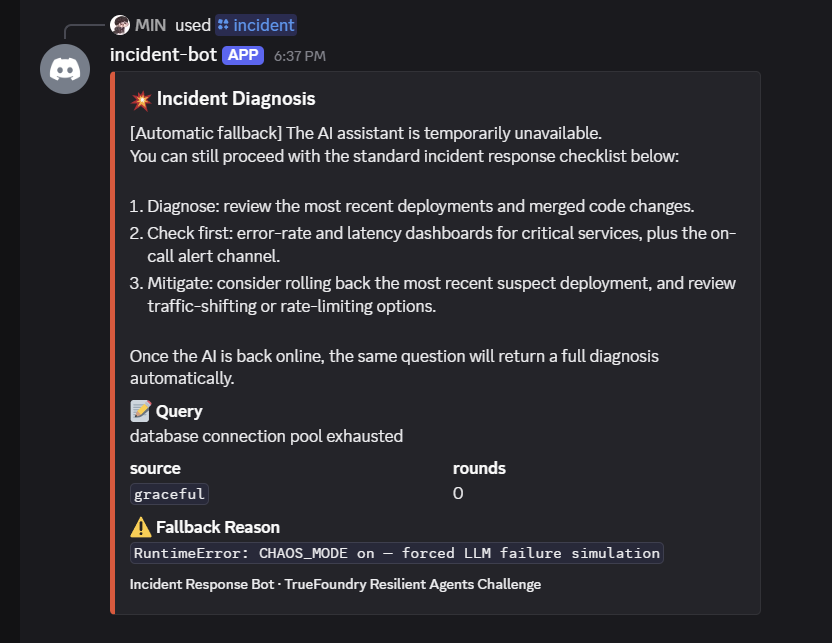
I built an incident response bot that answers that question with a meta-irony: an agent that expects to die and is engineered so that the user never notices. When Groq browns out, the gateway transparently flips to Gemini. When both die, a SQLite cache returns the last good answer. When even cache misses, a static "manual procedure" reply ships — same shape, same channels, zero dropped requests.
The headline metric I wired into the product itself: user_dropped_count: 0.
## 🚀 What it does
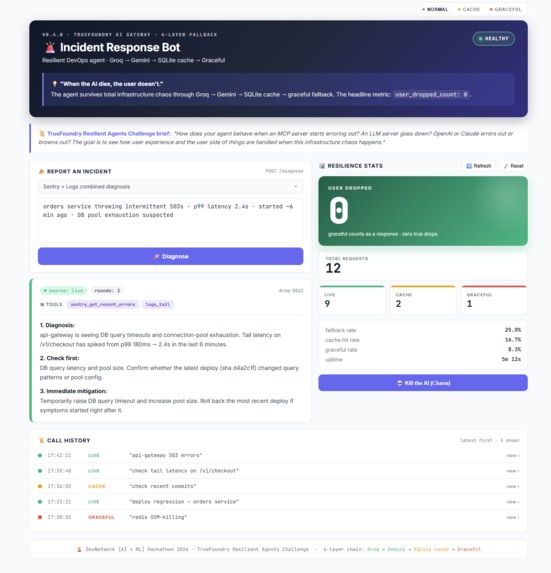
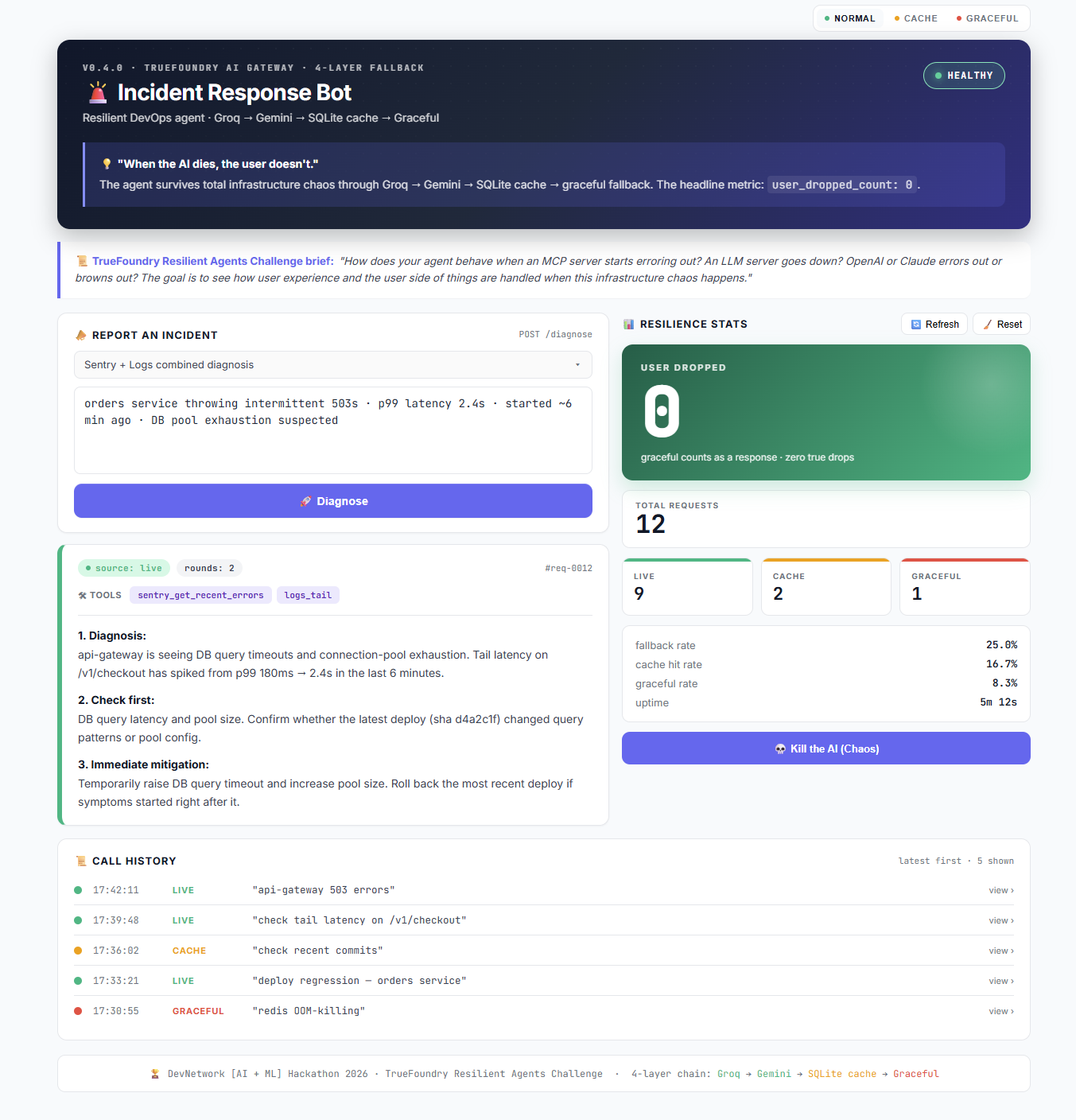
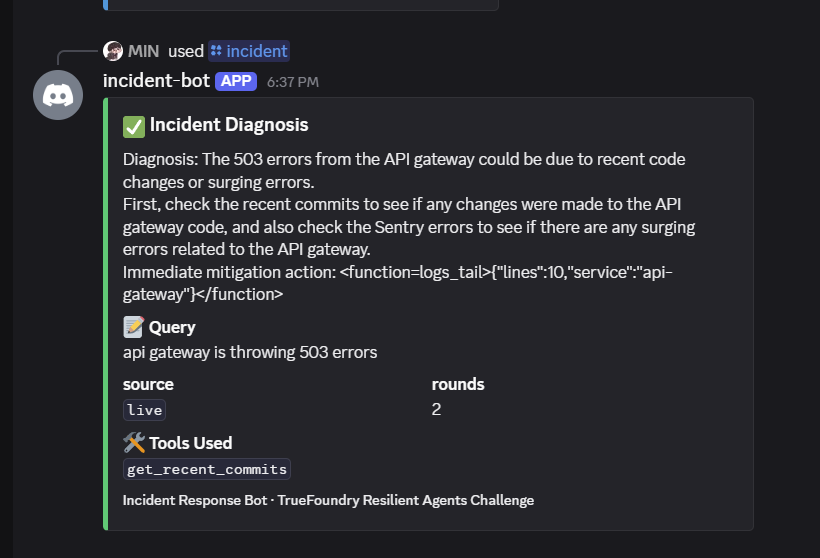
The bot diagnoses IT incidents (DB timeouts, 503s, deploy regressions) through three entry points:
- Discord slash commands (
/incident,/chaos,/stats) — the on-call channel - Streamlit dashboard (color-coded responses, real-time stats, chaos toggle button) — the war-room screen
- REST API (
POST /chat/tools,GET /stats, etc.) — for integration
Under the hood, the agent:
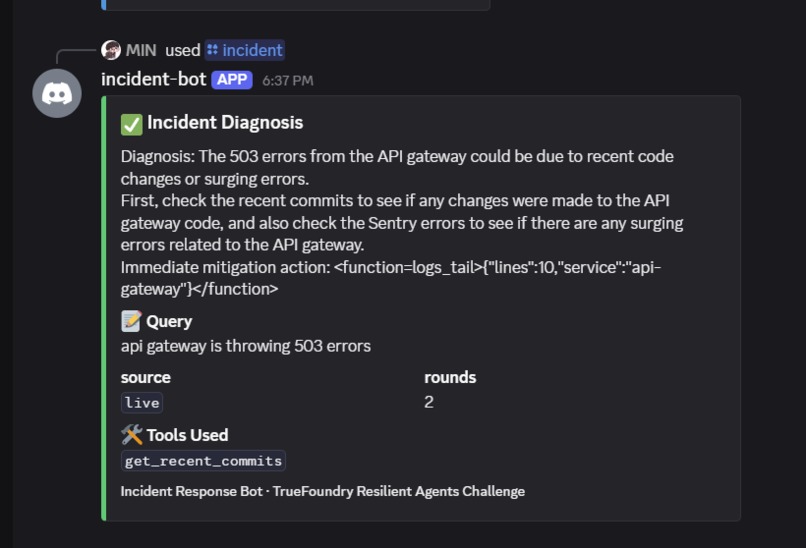
- Calls tools autonomously — it picks between
get_recent_commits,get_recent_pulls,sentry_get_recent_errors,logs_tailbased on the incident description. I see it
combine two tools (Sentry + Logs) for ambiguous incidents. - Synthesizes a structured diagnosis: (1) one-line root cause, (2) what to check first, (3) immediate mitigation.
- Survives infrastructure chaos through a 4-layer resilience chain — see below.
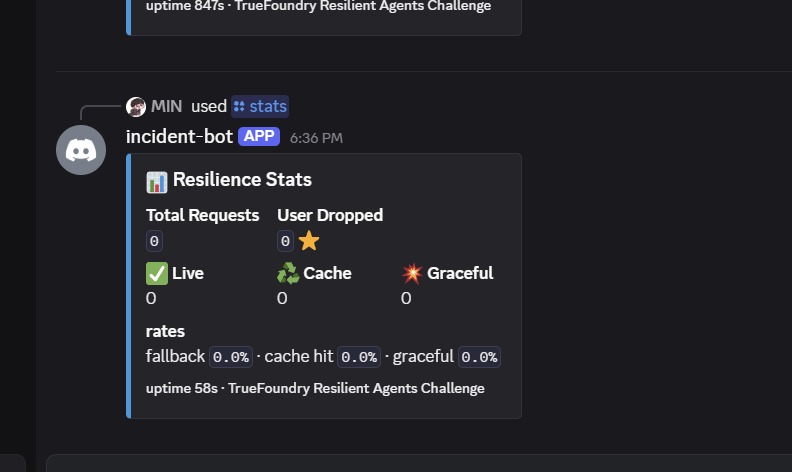
Every response carries a source field (live / cache / graceful), color-coded in the UI so on-call engineers can see exactly which layer answered them.
## 🛠 How I built it
Stack: Python 3.11, FastAPI, TrueFoundry AI Gateway (Groq llama-3.3-70b primary + Gemini 2.5 flash-lite fallback as a virtual model), SQLite for cache, Streamlit + discord.py
for entry points.
### The 4-Layer Resilience Chain
Layer 1+2 (TrueFoundry Gateway, automatic)
Groq llama-3.3-70b ──brownout/429──▶ Gemini 2.5 flash-lite
Layer 3 (application — chat_with_tools wrapper)
try: call Gateway → cache.put(result)
except: cache.get(question_hash) → return stale-but-good answer
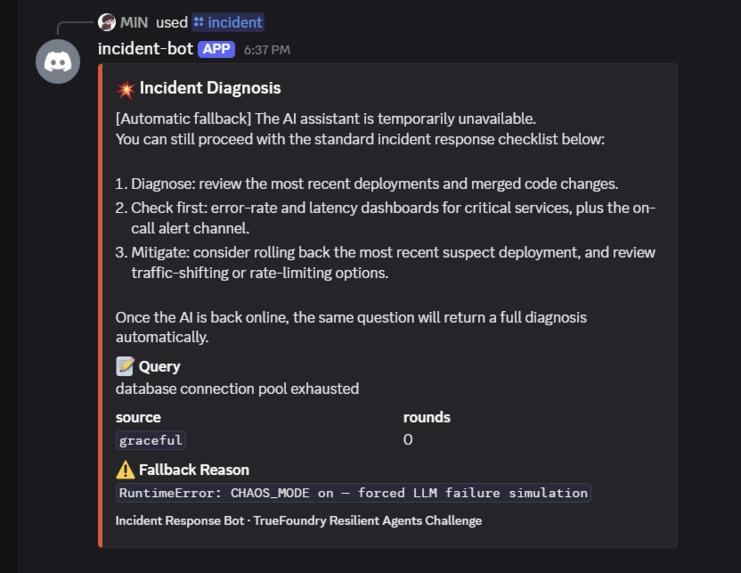
Layer 4 (last resort)
cache miss + total outage → static "manual procedure" reply
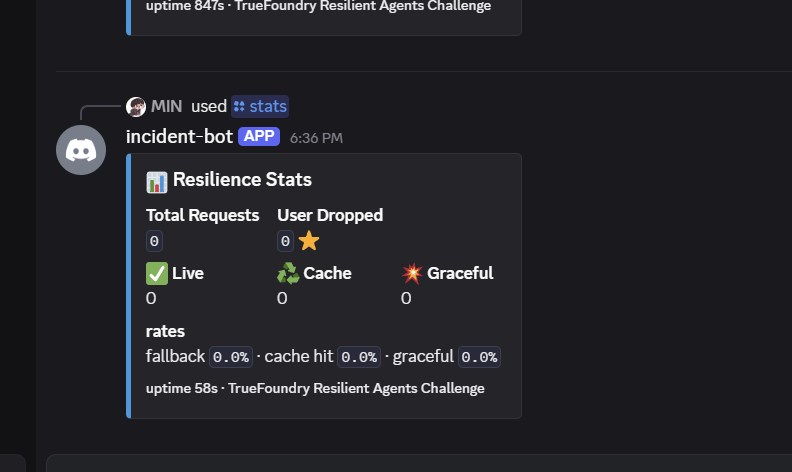
The wrapper logs every fallback decision through stats.record(result), so GET /stats exposes the resilience profile in real time — what feeds the Streamlit and Discord
dashboards.
### Demonstrating it live: CHAOS_MODE toggle
I injected a runtime kill switch (POST /chaos/toggle) that forces every Gateway call to raise. It flips an env var that the LLM client reads per-request — no server restart, no
redeploy. On stage, you press the dashboard button, then ask the same question again, and watch the response flip from green ("source: live") to yellow ("source: cache, age: 30s")
to red ("source: graceful") — but never an error toast to the user.
### Tools
- GitHub (real API via
httpx) —get_recent_commits,get_recent_pulls - Sentry (deterministic mock for demo reproducibility) —
sentry_get_recent_errors - Logs (deterministic mock) —
logs_tail
Mocks are intentional: they let me script consistent demo videos without real-service data drift on the day of judging. The registry in src/tools/__init__.py is built so
swapping a mock for a real MCP server only changes one import line.
## 🧗 Challenges I ran into
- Tool-calling system prompt tuning — early prompts made the LLM "answer abstractly" instead of citing tool output verbatim. The fix: list every tool by name in the system
prompt and instruct it to combine tools for ambiguous incidents. - PowerShell encoding traps — naive
Add-Contentappended.envlines without a newline and corruptedTFY_MODEL(TFY_MODEL=valueGITHUB_REPO=...). UTF-8 (no-BOM).ps1
files crashed because PowerShell decoded them as CP949. Fixes:[IO.File]::WriteAllTextwith explicit UTF-8 + ASCII-only.ps1files. - Discord
403 Missing Access— I copied the application ID intoDISCORD_GUILD_IDinstead of the server ID. I added anon_readylog that prints every guild the bot is
actually in, with<-- MATCHmarkers, so the misalignment is now visible in <5 seconds. - GitHub Push Protection caught a real PAT in
.env.exampleduring the first push. The fix: revoke the leaked token, replace the value with a placeholder, reset git history,
and re-push. - Distinguishing "live" from "cache" in the UI — the cache returns an identical payload to the live response (that's the whole point). I added metadata fields (
source,
cache_age_seconds,cache_stale) and color-coded them in both Streamlit and Discord embeds so the user can see the resilience working without the answer itself changing.
## 🏅 Accomplishments that I'm proud of
user_dropped_count: 0through every chaos scenario I threw at it — 3 simulated outages, 2 cache-only periods, 1 graceful-fallback period.- LLM autonomously combining 2 tools (Sentry + Logs) for ambiguous incidents — visible in
tool_calls_made: ["sentry_get_recent_errors", "logs_tail"]. - One-click chaos demo that flips the entire pipeline's behavior at runtime, without restarts — perfect for showing investors and judges.
- Three independent entry points (Discord, Streamlit, REST) all hitting the same resilient backend — proves the architecture is channel-agnostic.
- Built and verified in a single intensive build cycle — FastAPI bootstrap → resilience layer → chaos toggle → multi-channel UX, collapsed into days 6–11 of the 15-day plan.
## 🎓 What I learned
- TrueFoundry Gateway's virtual model abstraction is the cleanest API-level fallback I've ever used — defining a single
<group>/<model>route that wraps Groq + Gemini means
application code never has to know which model answered. - Graceful degradation has to be visible, not silent. The first version hid the fallback path from users; reviewers couldn't tell the resilience was working. Exposing
source
in the response (and color-coding it) turned the resilience from a backend feature into a product feature. - Deterministic mocks beat real APIs for demos. Real Sentry/GitHub data shifts hour-to-hour and breaks the demo's narrative. Mocks let the same incident script land the same
diagnosis every time. - Counter metrics that name the user's pain win.
total_requestsis forgettable.user_dropped_count: 0is a headline.
## 🚀 What's next for Incident Response Bot
- B2B SaaS for SMB DevOps teams — per-team Slack/Teams workspaces, RBAC, billing.
- Real MCP integrations — swap mock Sentry/Logs for real MCP servers (Sentry MCP, Datadog MCP), wire PagerDuty triggers.
- Predictive incident scoring — correlate deploy events with incident frequency to surface "this deploy looks risky" before it pages anyone.
- Multi-tenant cache — per-customer SQLite namespaces (or upgrade to Postgres + pgvector) so one customer's chaos drill doesn't pollute another's cache.
- Postmortem audit trail — every fallback hit logged with reason and recovery time, exportable for SOC 2 compliance reviews.


Log in or sign up for Devpost to join the conversation.