-
-
Incident Copilot API-Autonomous DevOps incident triage powered by Gemini + Elastic + GitLab
-
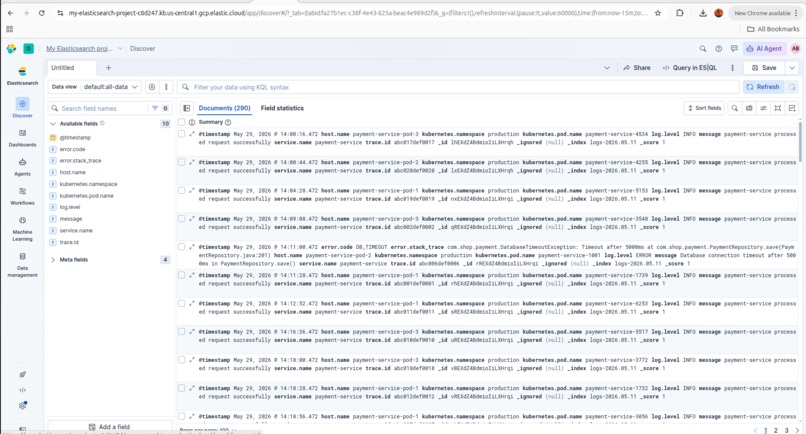
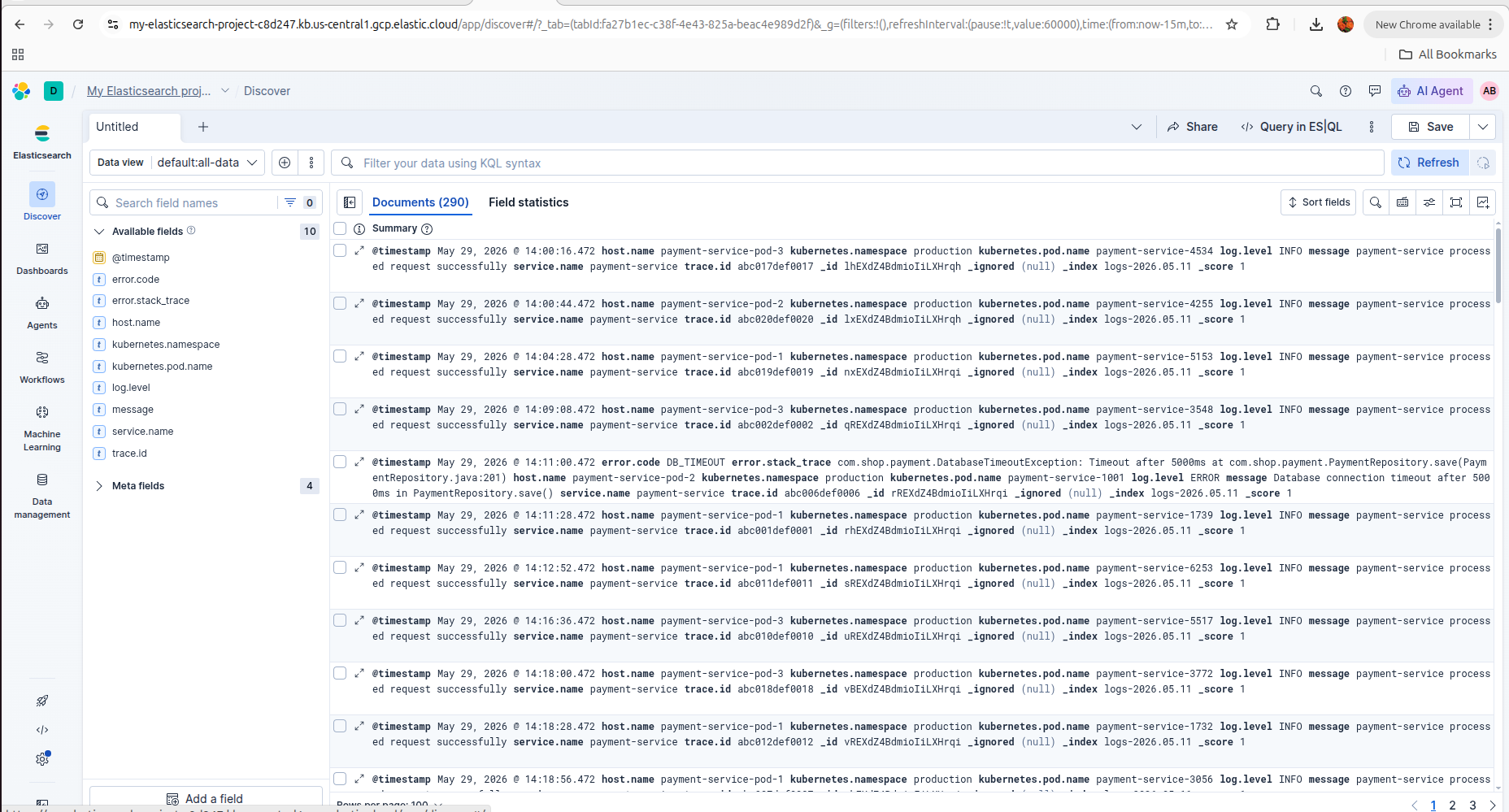
Elastic Search - 290 documents indexed in Elastic Cloud
-
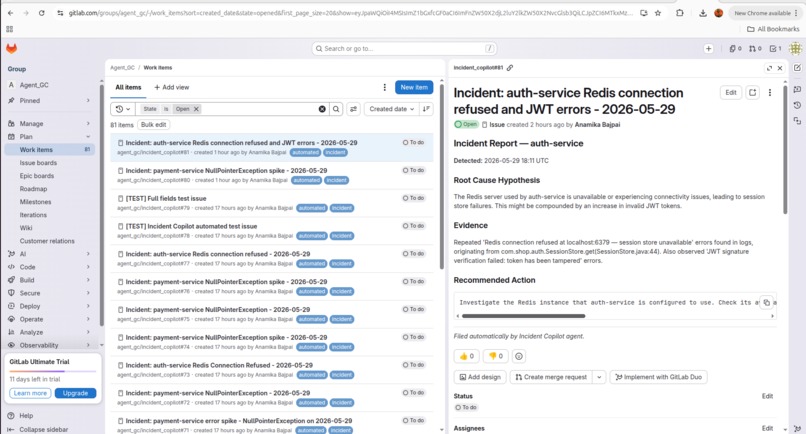
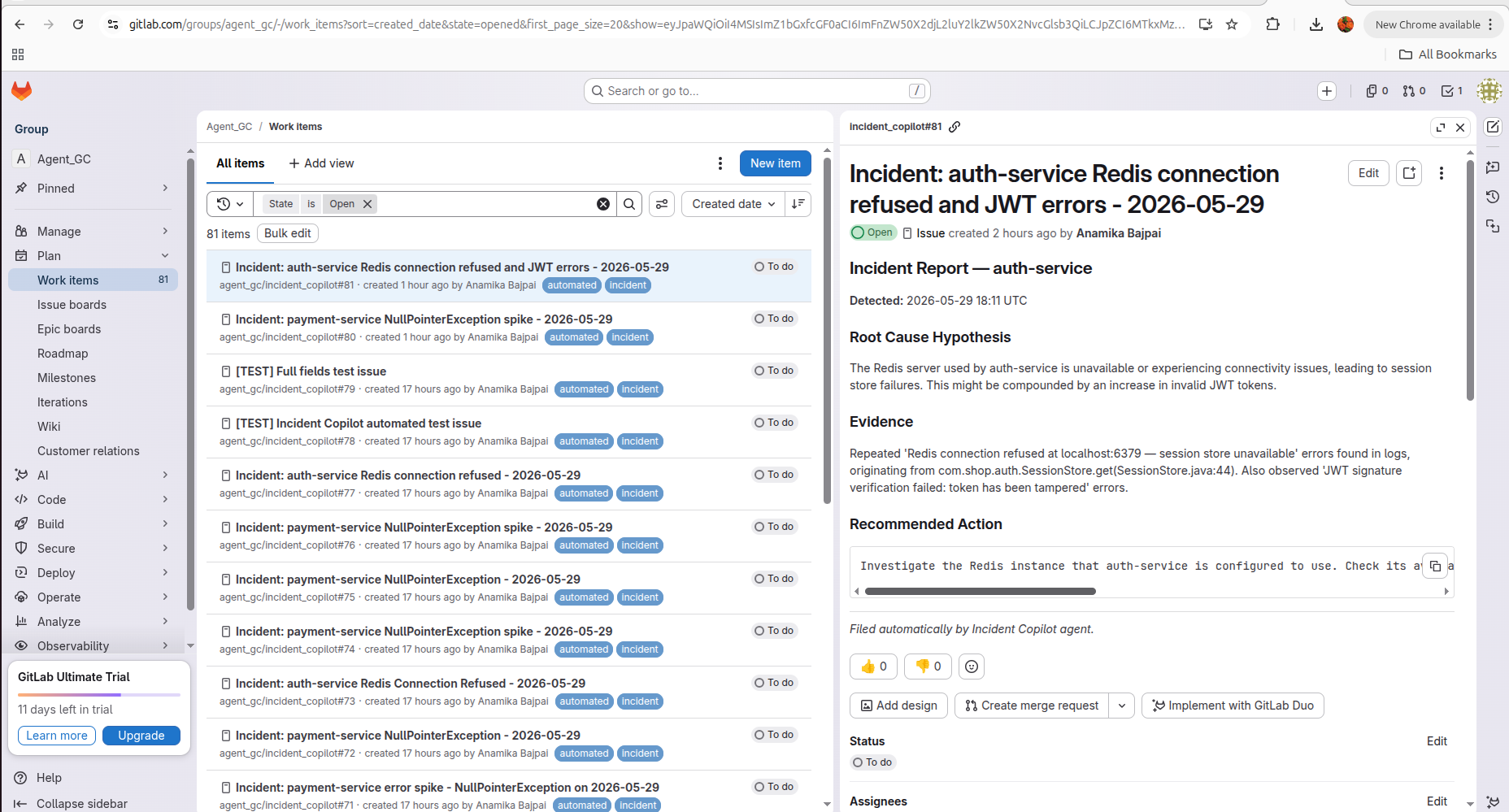
81 incident issues autofiled in GitLab each with root cause hypothesis, evidence from logs, and recommended action. Zero human intervention.
-
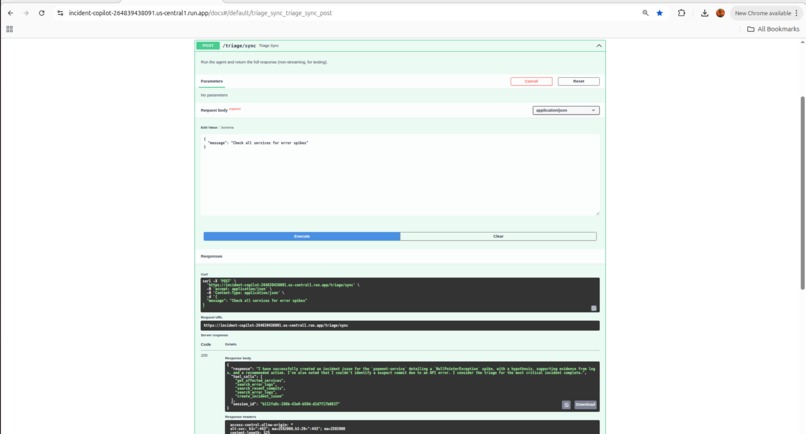
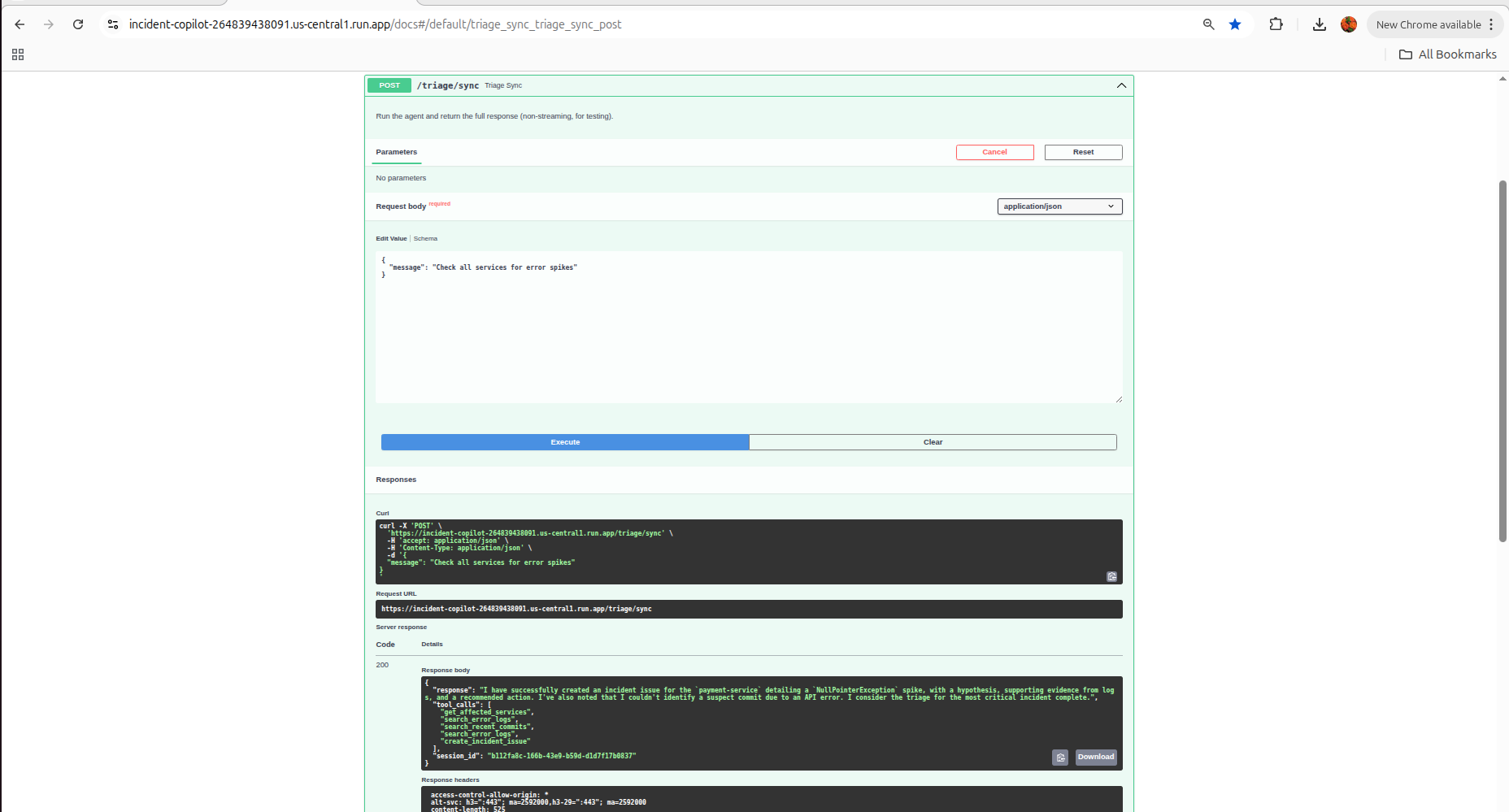
Agent autonomously calls 5 tools — detects payment-service spike, searches logs, traces commits,files GitLab issue.zero human intervention."
Inspiration- Every engineer has lived this: it's 2am, PagerDuty fires, and you spend the next
two hours manually grep-ing through logs, git-blaming commits, and trying to figure out which deploy broke production — while users are hitting errors in real time.
The problem isn't that engineers can't solve incidents. It's that the first 30–60 minutes are pure mechanical work: find the spike, search the logs, trace the commit, file the issue. An agent can do all of that. We wanted to prove it.
What it does: Incident Copilot is an autonomous DevOps agent that detects production anomalies in Elasticsearch, traces root causes to specific GitLab commits, and files structured incident issues — in under 30 seconds, with no human intervention.
How we built it: Built on Google ADK + Gemini 2.5 Flash (Vertex AI), integrating Elasticsearch for log intelligence, GitLab for commit tracing and issue management, and Arize Phoenix for full LLM observability of every agent decision. Demonstrated on 5 realistic incident scenarios: NPE spikes, Redis failures, DB timeouts, multi-service cascades, and full site outages.
Challenges we ran into:
Arize Phoenix authentication — the SDK expects a Bearer token via phoenix.otel.register(), not a plain api_key header. Took significant debugging to get traces flowing correctly to app.phoenix.arize.com.
GitLab issue creation 500 errors — GitLab returns 500 when labels referenced in the API call don't pre-exist on the project. Fixed with a silent fallback retry that creates the issue without labels, so triage never fails silently.
detect_error_rate_spike false positives — dividing recent errors by baseline when both are 0 produced infinity, flagging healthy services as spiking. Fixed with an explicit zero-count guard.
Gemini API rate limits — the free-tier Gemini API (5 RPM) is completely insufficient for a multi-step agent making 8–10 tool calls per triage. Switched to Vertex AI with $999 GenAI App Builder credits — no rate limits, full Gemini 2.5 Flash capability.
Seed data accumulation — running seed scripts multiple times inflated the 60-minute baseline, making spikes impossible to detect. Fixed by deleting and rebuilding the index on each seed run.
Accomplishments that we're proud of:
A fully autonomous 5-step triage pipeline: detect anomaly → search logs → trace commit → find merge request → file incident issue — with zero human input at any step.
35 tests all passing across config, Arize, Elasticsearch tools, GitLab tools, API, and full end-to-end agent scenarios.
5 realistic demo scenarios covering the full spectrum: single service NPE, Redis session failure, DB connection pool exhaustion, multi-service cascade, and full site outage — all triaged correctly by the agent.
Complete LLM observability via Arize Phoenix — every agent decision, tool call, and reasoning step is traced and visible, making the agent's behavior auditable and debuggable.
The agent handles multi-service failures without confusion — when payment, auth, and cart fail simultaneously, it correctly files three separate, distinct incident issues rather than collapsing them into one.
What we learned:
Google ADK is the right tool for this — not Vertex AI Agent Builder. ADK gives you full control over tool definitions, agent reasoning, and orchestration without locking you into a GUI-based flow.
Multi-step agents need real observability from day one. Without Arize Phoenix tracing, debugging why the agent made a wrong tool call would have been nearly impossible.
Prompt design matters more than model choice. The same Gemini 2.5 Flash model produced wildly different triage quality depending on how tool descriptions and system prompts were structured.
Self-healing error handling is essential for agentic systems. The GitLab label bug would have silently broken incident creation in production — building fallback retries into every tool made the agent robust against API quirks.
What's next for Incident Copilot -
Real-time streaming from Elasticsearch — shift from on-demand triage to continuous monitoring with automatic agent invocation when anomaly thresholds are crossed.
Rollback automation — once root cause is identified and the bad commit is traced, trigger a GitLab CI/CD pipeline revert automatically with one confirmation step.
Post-mortem generation — after incident resolution, automatically draft a structured post-mortem document from the triage timeline, root cause, and resolution steps.
Multi-repo support — today the agent searches one GitLab repo. Extending to multi-repo microservice architectures where the offending commit may live in a different service's repo.
Slack/PagerDuty integration — surface triage results directly into the incident channel where the on-call engineer is already working, rather than requiring them to open a separate UI.
--> All agent runs are traced via Arize Phoenix MCP server — query past incidents and trace spans directly from the agent using phoenix_* tools.
Built With
- adk
- ai
- arize
- elasticsearch
- fastapi
- gemini
- gitlab
- phoenix
- python
- streamlit
- vertex

Log in or sign up for Devpost to join the conversation.