-

Emiliano training our EEG model
-

brainstorming
-

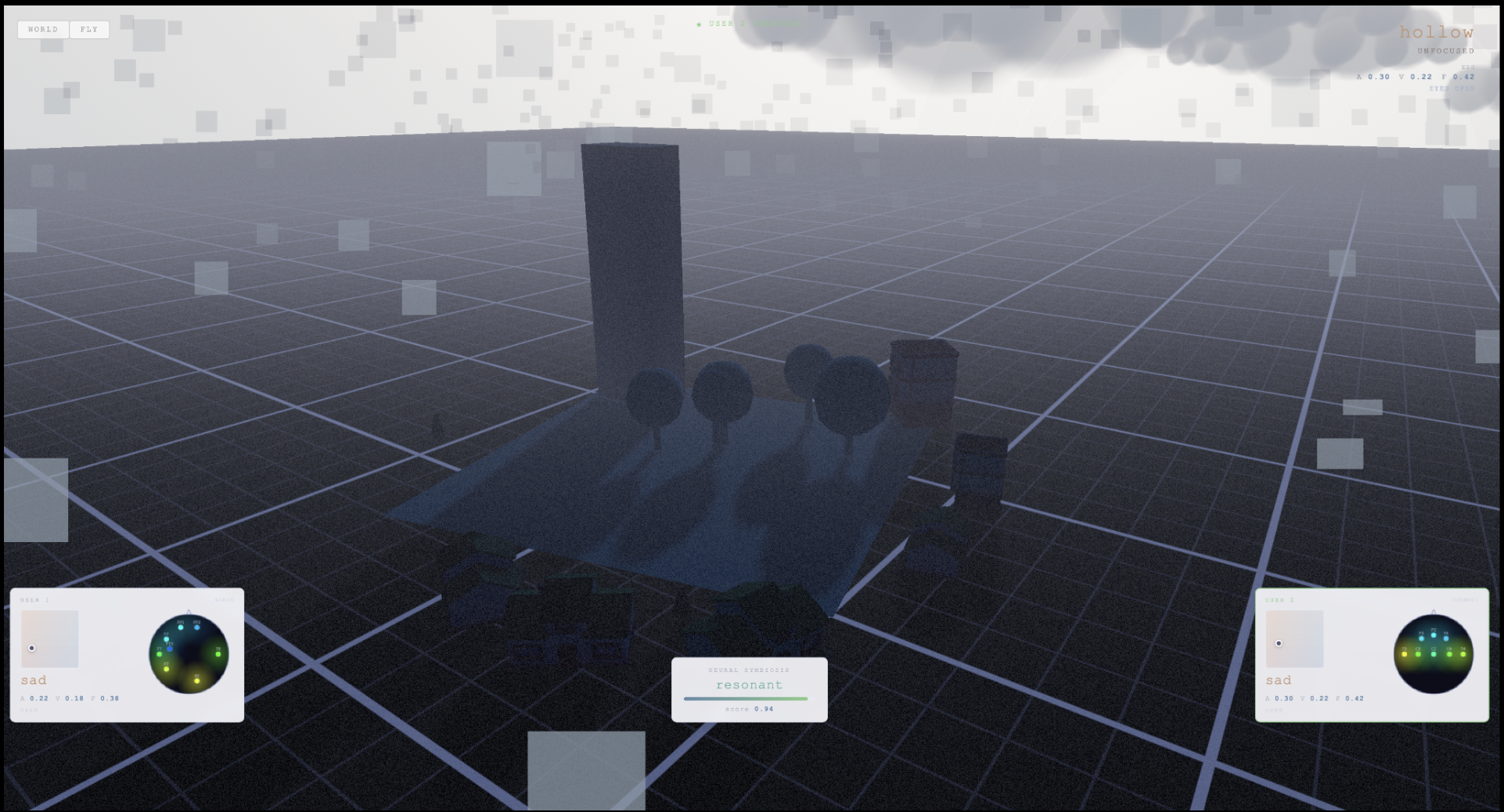
Rainy and stormy weather when both users are sad
-

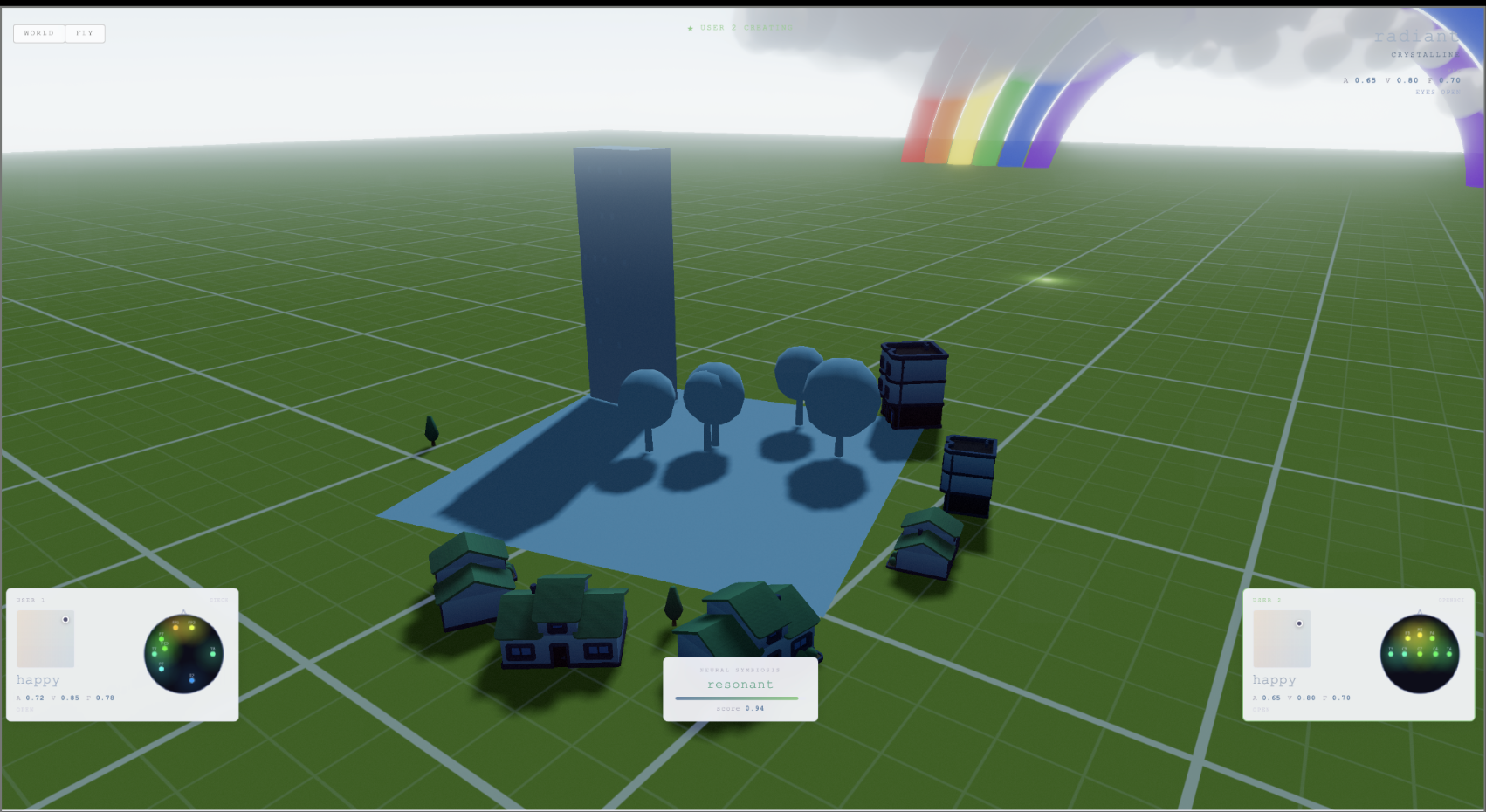
Sunshine and rainbows when both users are happy
-

Live EEG heat map for activations



Inspiration
BCI research has spent decades optimizing for cursors, spellers, and robotic arms - single-degree-of-freedom outputs. But the brain doesn't think in cursors. Engineers, architects, and designers represent rich 3D spatial environments natively. The real unsolved problem in neurotech is: can we build a brain-to-3D pipeline that matches the dimensionality of human spatial thought?
This matters most for motor-impaired individuals. Today's assistive BCIs try to recreate mouse control through neural signals - but that's still forcing 3D thinkers through a 2D interface, just with a worse input device. Most motor-impaired people will never receive a neural implant, so they're locked out entirely. We believe the answer isn't to decode motor commands more precisely - it's to rethink the interface. If the system is intelligent enough to work from higher-level neural signals - what a user is feeling, what objects they're envisioning - then precise cursor control becomes unnecessary. The brain provides the intent, and generative AI can help handle the assembly.
And if brain-native design works for someone who can't use a mouse, it works for everyone. Every engineer using SolidWorks is still compressing 3D spatial cognition through 2D menus. Inception is our proof of concept that this paradigm can change.
What it does
Inception is a multi-brain collaborative 3D design system. Multiple participants wear EEG headsets simultaneously, and their combined neural signals drive a shared 3D environment that assembles itself in real time from the group's collective brain state.
The system is multimodal - it uses two complementary neural channels to shape the world:
Ambience via EEG emotion classification: We classify each participant's emotional state (happy, neutral, sad) from EEG band power features using a deep learning model. A consensus algorithm merges multiple participants' emotional states in real time, weighted by neural engagement. The collective emotion drives the environment's atmosphere - rain and darkness when the group is sad, sunshine and rainbows when they're happy.
Object generation via simulated hemodynamic decoding: We don't have access to fMRI hardware, so we simulate what hemodynamic brain signals would look like for a person thinking about a specific object. We use Meta FAIR's TRIBE v2 - a trimodal brain encoder trained on 500+ hours of fMRI data from 700+ participants watching naturalistic video - to generate synthetic fMRI activation patterns from AI-generated imagery. We then trained a decoding model to identify objects from these fMRI inputs, and the decoded objects are placed into the shared 3D world.
Together, EEG sets the mood of the world and hemodynamic decoding populates it with objects - two neural modalities, one unified environment.
How we built it
EEG emotion classification: An OpenBCI 16-channel electrode cap with Cyton board streams raw signals via BrainFlow. A gTec BCI Core headset streams via gPype. At each time step, we compute delta, theta, and alpha band powers from the incoming EEG signal and feed those features into a classifier. We iterated across three model architectures - an adapted EEGNet, a simple MLP, and a custom CNN - using L2 regularization, weight decay, dropout, and batch normalization to reduce overfitting, evaluating with F1 scoring. We manually collected our own labeled training data and built a custom training pipeline from scratch. The live system maintains a continuously updating ring buffer of EEG data that gets grabbed, decomposed into frequency-band features, and sent to the decoding model for real-time emotion classification.
Neural consensus layer: Multiple emotion vectors are merged in real time using a weighted consensus algorithm. Participants with stronger neural engagement have more influence over the current environment state.
Hemodynamic simulation and object decoding: We don't have access to high-quality neuroimaging equipment for direct object classification from brain activity, so we built a simulation proxy. Participants describe a scene out loud, their voice is transcribed to text, an image is generated via Black Forest Labs, and that image is animated into a short video. TRIBE v2 takes the video as input and predicts the fMRI brain activation a human would show when perceiving that scene - this is our stand-in for a human simply visualizing an object and having an imaging system record the neural data directly. TRIBE outputs a 20,000-dimensional vector representing spatial brain activations. We apply PCA for dimensionality reduction before feeding it into our classification model. To reduce overfitting we again use L2 regularization, weight decay, and normalization techniques. We curated our own dataset and trained this decoding model from scratch.
3D environment: A real-time 3D engine renders the assembled world, with weather and lighting driven by the emotional consensus and objects placed by the hemodynamic decoding pipeline. Participants can fly through the environment to see what the group collectively built.
Challenges we ran into
Synchronizing multiple EEG streams from different hardware (OpenBCI and gTec) with different clock drift and sample rates in a live, noisy environment. Defining what "consensus" means when every brain is saying something slightly different - the signal processing was the easier problem, the semantics of merging neural states was harder.
Developing a robust emotion classifier from EEG was its own challenge. We spent an entire night manually collecting labeled data across multiple sessions, and found that simply removing and re-placing the headset caused significant signal drift that broke models trained on a single session. Getting something that generalized across sessions required serious iteration on both the data pipeline and regularization strategy.
Accomplishments that we're proud of
Getting two heterogeneous EEG systems synchronized and producing a stable consensus signal in a live demo environment. Building a complete voice-to-image-to-video-to-TRIBE-to-decoded-object pipeline that simulates hemodynamic decoding without access to fMRI hardware. Training both the emotion classifier and the fMRI object decoder from scratch on our own curated datasets. Watching a 3D world assemble itself from the merged brain states of multiple people, with both emotional ambience and object content driven by neural signals.
What we learned
Different brain measurement modalities - electrical (EEG) and hemodynamic (fMRI) - don't just differ technically. They capture fundamentally different aspects of neural processing. EEG gives us fast temporal dynamics like emotional state. Hemodynamic signals give us rich spatial and object-level information. Connecting them meaningfully in a single system is an open research problem we only scratched the surface of. We also learned that the hardest part of multi-brain systems is not signal processing - it's defining what agreement looks like when every brain encodes the world differently.
What's next for Inception
Right now we use EEG for emotion and simulated fMRI for object decoding. But nothing about our pipeline is locked to those two signals. Portable functional ultrasound headsets are getting close to fMRI-quality hemodynamic imaging without a scanner - when that hardware is ready, our simulated fMRI path becomes a real one. Motor cortex decoding could let users directly scale, rotate, and move objects by thinking about the movement. The multi-brain sync, consensus merging, and generative assembly layers we built don't care what decoder is feeding them - they just need a signal.
And this goes way beyond engineering. Game designers, urban planners, architects, filmmakers - they all think in 3D and build through 2D tools. We started by building for the people who need this most. But the vision is for everyone.
Built With
- black-forest-labs-(flux)
- brainflow
- elevenlabs
- fastapi
- gpt-4o
- javascript
- meta-tribe-v2
- openbci
- python
- react
- three.js
- webgl

Log in or sign up for Devpost to join the conversation.