-
-

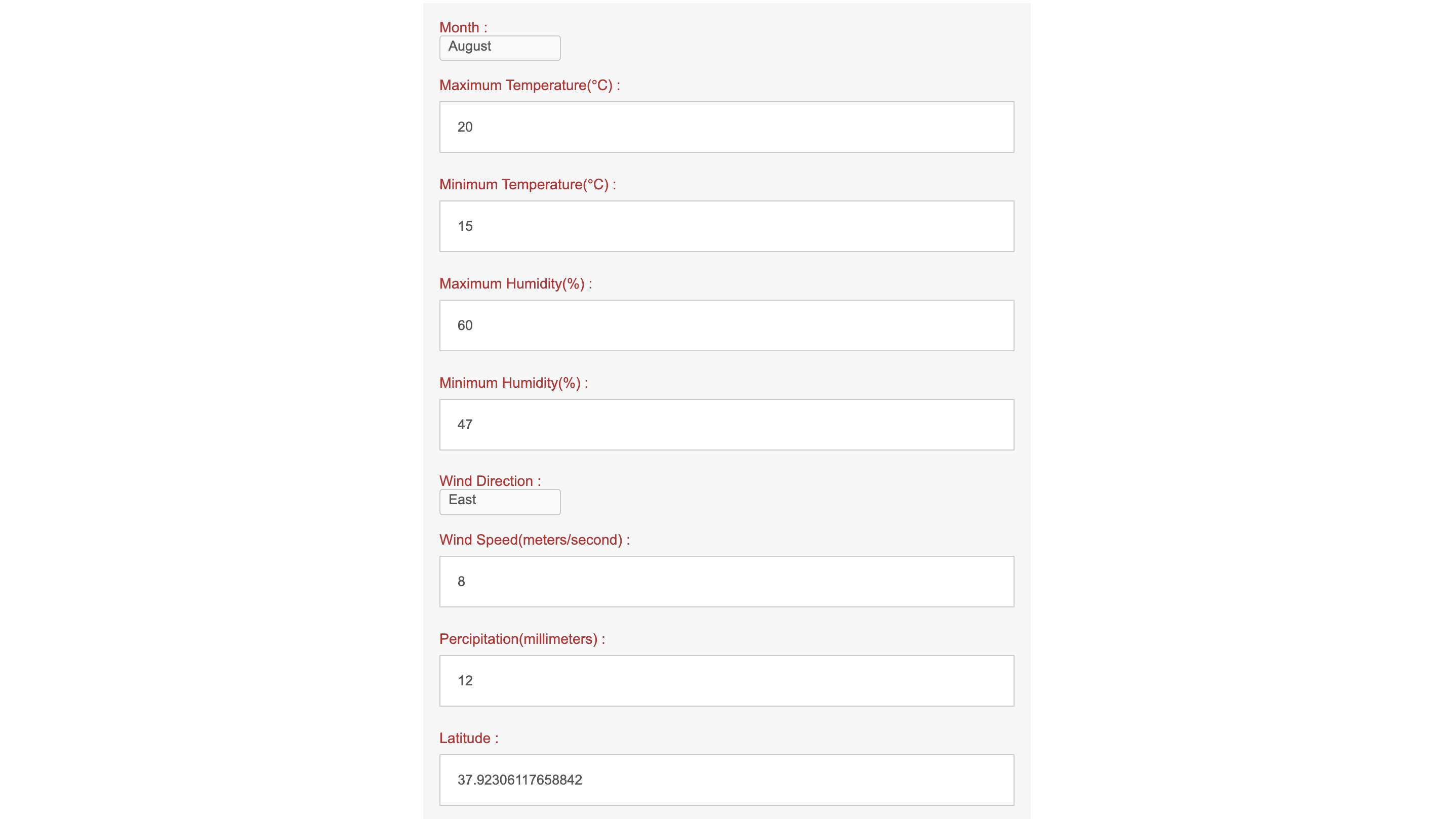
A prediction example
-

Fill in relevant factors.
-

Main page of the website
-

Graph of the loss against the number of iterations using neural network


Inspiration
According to a research done by National Research Council, an increase on average of temperature of 1 Celsius is expected to multiply the area burned in the West by several-fold. We need a way to better handle forest fires because 1) it itself is a huge source of carbon dioxide emissions, worsening global warming 2) It poses threats to wildlife and people’s properties. Better prediction on the severity of fires beforehand would allow better allocation of resources such as coordination of help between firefighting forces across different counties. Hence, we are inspired to construct this website.
What it does
Anthropocene is a website that helps predict the severity of forest fires in California as you key in various factors associated with fire spreading such as humidity, temperature. Once a forest fire is spotted, Anthropocene can be used to provide insights into how large the incident area may be, and individuals and authorities can hence take action. It is powered by a Machine Learning model that we construct based on all the past forest fires data in California since 2013. With this platform, firefighting forces can better anticipate the severity of a forest fire and thus better manage available resources to combat fires.
How I built it
We first scraped data of California wildfire from different reliable websites including University of California Integrated Pest Management Program and California Department of Forestry and Fire Protection, which are presented in different forms. We then concatenate all data obtained and created a data set with forest fire incidents in California over the past six years using Python. After wrangling the data, we applied principal component analysis (PCA) and built several models predicting the severity of a forest fire, including random forest, polynomial regression, and neural networks. Using log cosh loss function, the neural network was chosen as it has the best overall performance on the test set. We then built the website referencing to the model to visualize our results.
Challenges I ran into
Data scraping and data wrangling are particularly challenging for us. There is data in different formats available on different websites. We gathered all the data sets and compile them into a format-aligned set encompassing all reliable past year data we can find. We also need to build models with a limited amount of data, which leads to a possible outcome of overfitting. We had to implement various machine learning techniques carefully, and choose among different models.
Accomplishments that I'm proud of
All four of us have never been in any hackathon before. We are so proud to see what we are able to accomplish in 36 hours--collection of data, data cleaning, the construction of models and the construction of an interactive website. This project is challenging but innovative, as there is currently no wildfire predictor available online. Though due to limited data available, this model may not be very accurate, it does mostly behave as our assumptions. In addition, we are able to provide the programming community with a novel and complete wildfire dataset, so that people can spend less time on data wrangling, but instead focus on developing strategies to forecast possible occurrences of wildfire and predict the severity. This project can also be a framework for large-scale projects we may develop in the future. After further improvement, our website can be a functioning forecaster that can help the government and individuals to reduce the harm of wildfire more efficiently, and possibly reducing greenhouse gas emission to the atmosphere and slow down climate change.
What I learned
We learned that there are vast amounts of libraries out there roughly trying to do the same thing (such as rendering music), but some are definitely much easier and well-documented than others. Choosing your tools carefully is key. In addition, we were able to practice our data preprocessing and web development skills, which helps us to get familiar with a broad spectrum of APIs and libraries.
What's next for InAnthropocene
For now, we are unable to find any data on topography and canopy density. If we could obtain the data in the future, they could be included in our ML model to better improve the accuracy of our model. We are also considering using satellite images and applying a convolutional neural network to extract information on where the fire is located. We can also add a wildfire forecasting function to our website, which can be realized by getting more data and utilizing a time series model. Besides, we would also want to extend the scope to include all U.S. territories or even other continents if we are able to obtain enough data so as to help firefighting forces better cope with forest fires. For instance, we could monitor the wildfire in Australia and provide advice related to resource allocation.
FOR YOU TO TRY OUT, please download the website.zip file and open the HTML link inside as we did not purchase web-hosting services.
Built With
- css3
- google-cloud
- gooogle-map
- html5
- javascript
- python




Log in or sign up for Devpost to join the conversation.