
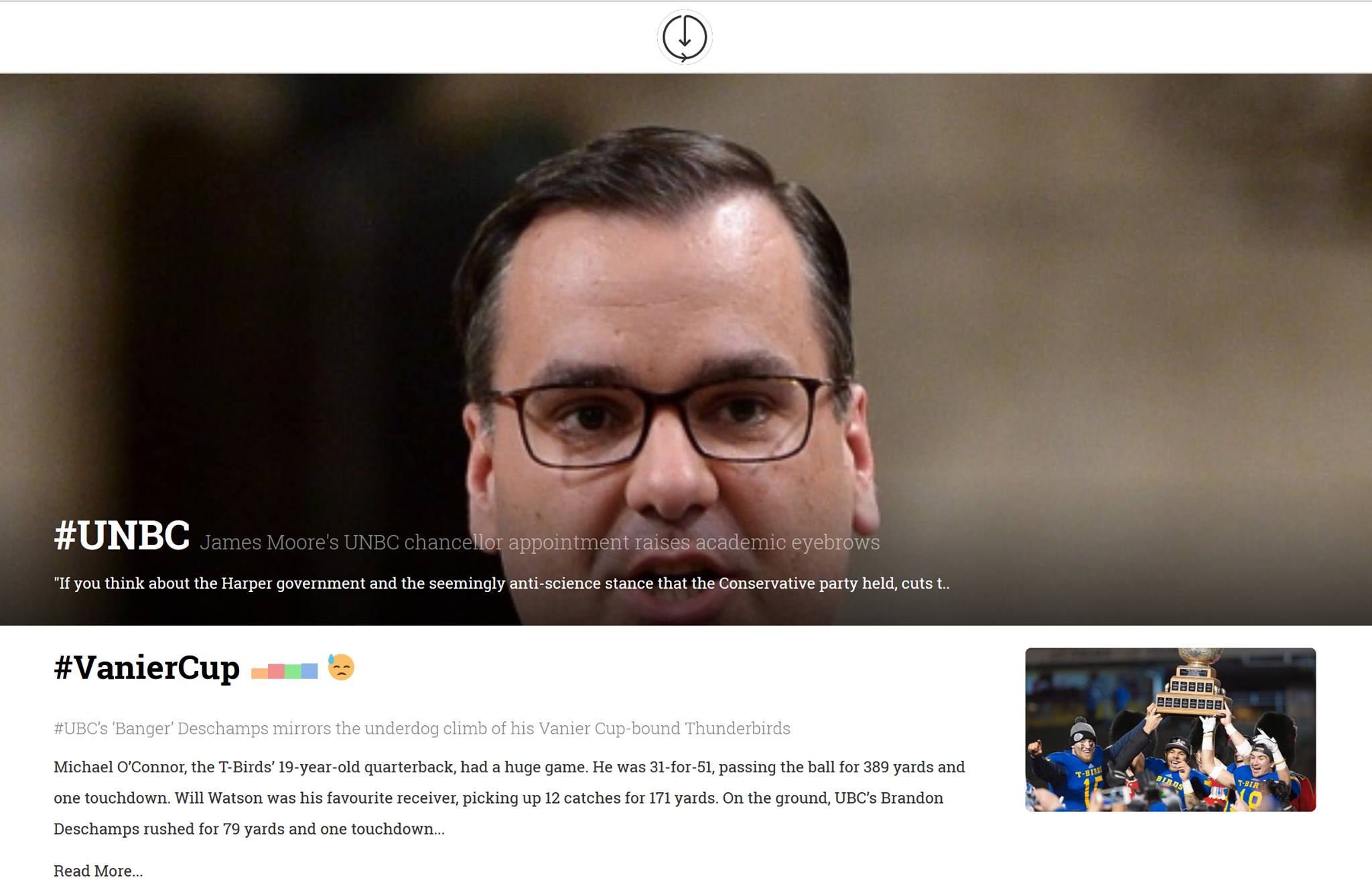

Inspiration
Following the recent tragic attacks in Paris, Beirut, and other places, the world has seen the chaos that followed during and after the events. We saw how difficult it was for people to find everything they wanted to know as they searched through dozens of articles and sites to get a full perspective on these trending topics. We wanted to make learning everything there is to know about trending topics effortless.
What it does
Our app provides varied information on trending topics aggregated from multiple news sources. Each article is automatically generated and is an aggregation of excerpts from many sources in such a way that there is as much unique information as possible. Each article also includes insights on the attitude of the writer and the political leaning of the excerpts and overall article.
Procedure
- Trending topics are found on twitter (in accordance to pre-chosen location settings).
- Find top 30 hits in each topic's Bing results.
- Parse each article to find important name entities, keywords, etc. to be included in the article.
- Use machine learning and our scripts to select unique excerpts and images from all articles to create a final briefing of each topic.
- Use machine learning to collect data on political sentiment and positivity.
All of this is displayed in a user-friendly web app which features the articles on trending topics and associated data visualizations.
How we built it
We began with the idea of aggregating news together in order to create nice-looking efficient briefings, but we quickly became aware of the additional benefits that could be included into our project.
Notably, data visualization became a core focus of ours when we realized that the Indico API was able to provide statistics on emotion and political stance. Using Charts.JS and EmojiOne, we created emoticons to indicate the general attitude towards a topic and displayed the political scattermap of each and every topic. These allow us to make very interesting finds, such as the observation that Sports articles tend to be more positive than breaking news. Indico was also able to provide us with mentioned locations, and these was subsequently plugged into the Google Places API to be verified and ultimately sent to the Wolfram API for additional insight.
A recurring object of difficulty within our project was ranking, where we had to figure out what was "better" and what was not. Ultimately, we came to the conclusion that keywords and points were scatted across all paragraphs within a news story. A challenge in itself, a solution came to our minds. If we matched each and every paragraph to each and every keyword, a graph was formed and all we needed was maximal matching! Google gods were consulted, programming rituals were done, and we finally implemented Kuhn's Max Matching algorithm to provide a concise and optimized matching of paragraphs to key points.
This recurring difficulty presented itself once again in terms of image matching, where we initially had large pools (up to 50%) of our images being logos, advertisements, and general unpleasantness. While a filtering of specific key words and image sizes eliminated the bulk of our issues, the final solution came from an important observation made by one of our team members: Unrelated images generally have either empty of poorly constructed alt tags. With this in mind, we simply sorted our images and the sky cleared up for another day.
The list of technicalities:
- Implemented Kuhn's Max Matching
- Used Python Lambda expressions for quick and easy sorting
- Advanced angular techniques and security filters were used to provide optimal experiences
- Extensive use of CSS3 transforms allowed for faster and smoother animations (CSS Transforms and notably 3D transforms 1. utilize the GPU and 2. do not cause page content rerendering)
- Responsive design with Bootstrap made our lives easier
- Ionic Framework was used to quickly and easily build our mobile applications
- Our Python backend script had 17 imports. Seven-teen
- Used BeautifulSoup to parse images within articles, and newspaper to scrape pages
Challenges we ran into
- Not running out of API keys
- Getting our script to run at a speed faster than O(N!!) time
- Smoothly incorporating so many APIs
- Figuring out how to prioritize "better" content
Accomplishments that we're proud of
- Finishing our project 50% ahead of schedule
- Using over 7 APIs with a script that would send 2K+ API requests per 5 minutes
- Having Mac and PC users work harmoniously in Github
- Successful implementation of Kuhn's Max Matching algorithm
What's next for In The Loop
- Supporting all languages










Log in or sign up for Devpost to join the conversation.