-
-
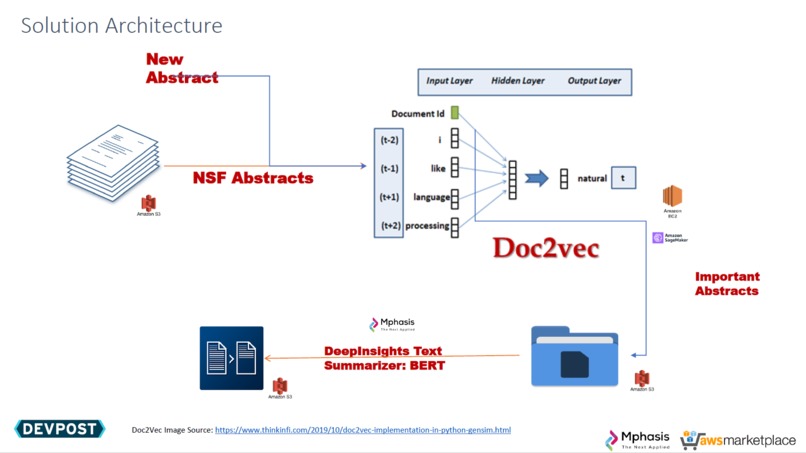
Solution Architecture
Inspiration
To understand the importance of this research better we must go back to 1950. In 1950, the National Science Foundation got created by congress. This meant to promote the progress of science and advance the nation’s health, prosperity, welfare and to improve national defence. NSF is vital because they support basic research and people to create knowledge that transforms the future of the nation.
NSF Fund advanced instrumentation and facilities including posts in Antarctica and other national research laboratories.
Besides, As researchers ourselves, we are familiar with the time, dedication, and hard work required to not just study a topic, but to also find relevant studies to build upon.
Which led us to investigate the National Science Foundation (NSF) data to find out how research gets funded.
What it does
Here, We set out to develop a method for grouping similar proposals together based on its context. That will help reviewers identify similar proposals to the ones they are reviewing based on textual context from the past 330,000 proposal abstracts.
Basically, It finds the most similar proposal abstracts for a new research proposal abstracts from the past 330000 funded proposals. then it transforms the most similar results found into short summaries making easier for a new researcher or a reviewer to understand.
How we built it
We used AWS SageMaker + EC2 Instance to train and build our Model. We used AWS S3 Bucket: For Storing Input and Output Files. We used Mphasis DeepInsights Text Summarizer (i.e. uses BERT) to summarize final most similar abstracts.
At first, all the abstracts are fed into the Doc2Vec Neural Network to extract document embeddings on SageMaker and data from S3 Bucket. then, This provides most similar of abstracts that have been grouped together based on textual context or cosine similarity on S3 bucket. which passed onto Mphasis text summarizer to get a Summarized outcome from the top similar most similar abstracts to S3 bucket. Finally, This embedding and clustering technique can be used with new funding proposals to identify similar proposals.
Challenges we ran into
Memory issues while using AWS Sagemaker Notebook which took our time to experiment with different ideas. Data had many columns and it took time to come up with Embedding and Summarizing technique. Our experiments on using BERT and GPT2 had a couple of hurdles and is in progress.
Accomplishments that we're proud of
We are happy that we came up with documents embedding and summarizing idea and solution which could help NSF Merit Review and Submission Process.
What we learned
A lot was learned over the course of this study. This study gave us an opportunity to explore natural language processing techniques in combination with building complete AWS end to end solution. This technique has many advantages. It is capable of learning textual context, It demonstrated the ability to achieved coherent clusters and is capable of processing new text. In addition, It gives summarized results. However, not all the cluster were coherent or even particularly useful. Unseen words could potentially decrease the quality of the contextual understanding of a new proposal. New discoveries and scientific progress are likely to produce words that have not been seen by the model.
It is also a challenge to determine the quality of a cluster as the coherence of a cluster is determined subjectively
What's next for Improving NSF Merit Review Process using NLP
The last few years saw great improvements in the field of Natural Language Processing. The very popular BERT and GPT2 models were developed and have a large amount of potential for computational language understanding. Despite, the large strides made in the field over this last few years, there is still a lot of work to be done. Some additional work that could be done regarding the NSF funding proposal embedding and clustering study performed here would be to try and include the rest of the proposal data along with the document vectors to improve clustering. Some work is also required to help determine the quality of a cluster. As of now, we manually inspected clusters for coherence. However, a less subject method would help in determining if changes to the model were improvements. BERT and GPT2 could also be used to better contextual understanding of the abstracts potentially providing better clusters. Some time-series analysis could also be applied to this dataset and doc2vec method for predicting funding ranges for new proposals.








Log in or sign up for Devpost to join the conversation.