Improving Autonomous Cars — Counterfactual Driving, Trained by Human Feedback
What if the car had chosen differently?
Inspiration
You can't drive your way to safety. RAND showed self-driving cars would need hundreds of millions — sometimes hundreds of billions — of miles to statistically prove they're safe, because the moments that actually matter (a jaywalker, a near-miss, the half-second a kid steps off the curb) almost never happen per mile. No fleet can drive far enough to catch them all.
So the industry simulates instead. But the world models that do it live inside Waymo and Nvidia, behind proprietary fleets and TPU clusters. We wanted the version a small team can actually run and inspect: take one logged scene, branch it into the futures that didn't happen, and let a human teach the policy which future was better. RLHF for driving, not chatbots — the same GRPO that taught reasoning models to think, pointed at a steering wheel.
What it does
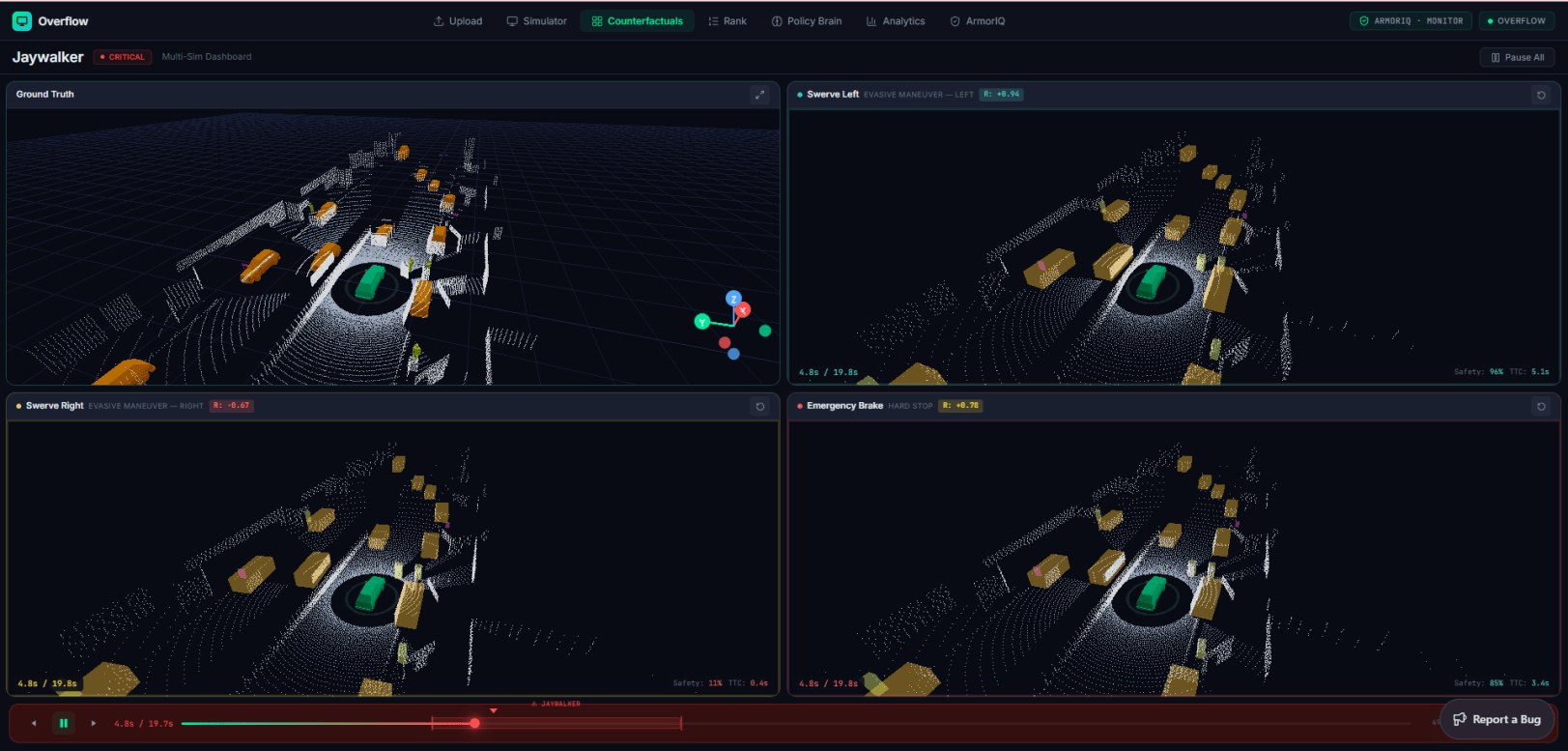
Improving Autonomous Cars turns a single driving log into a training signal.
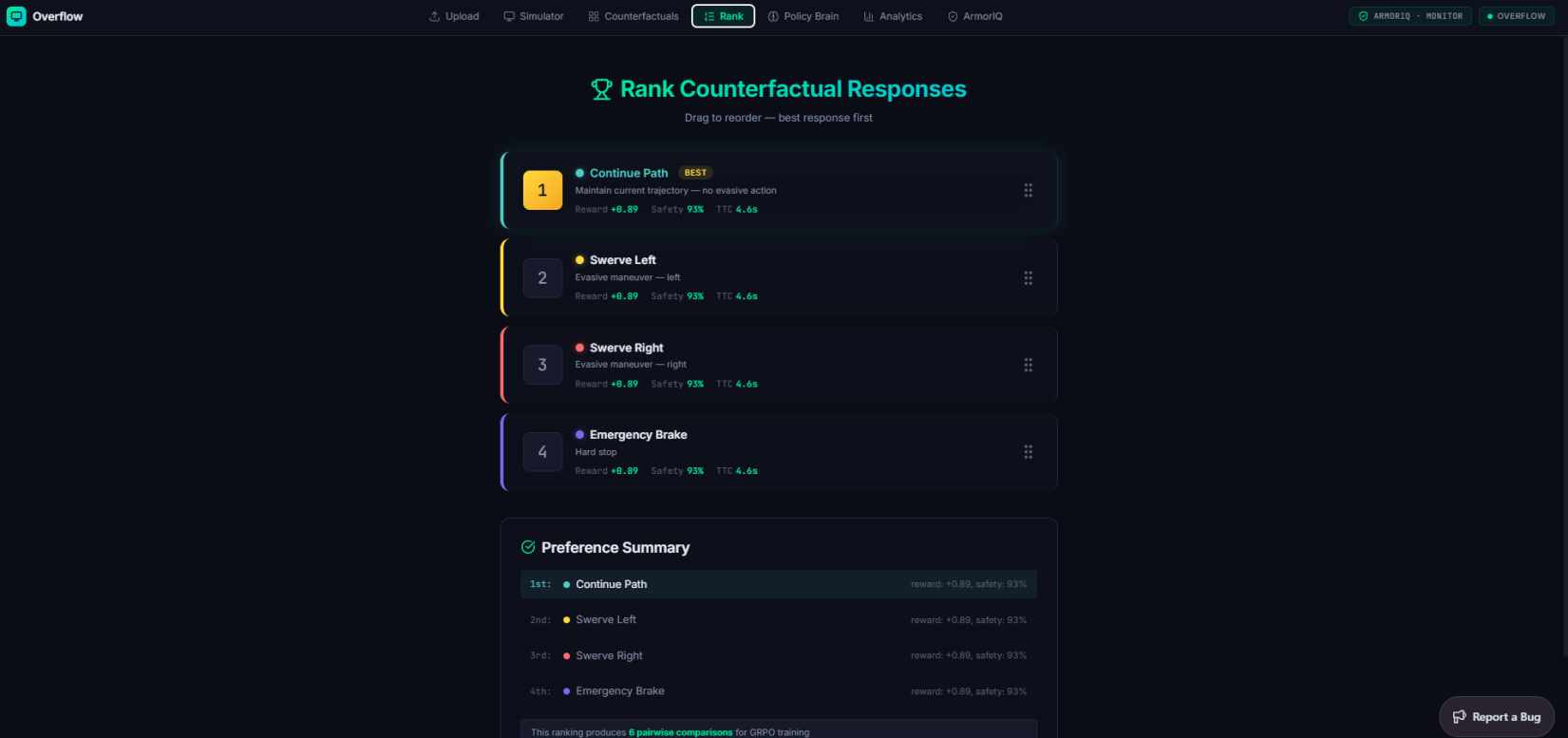
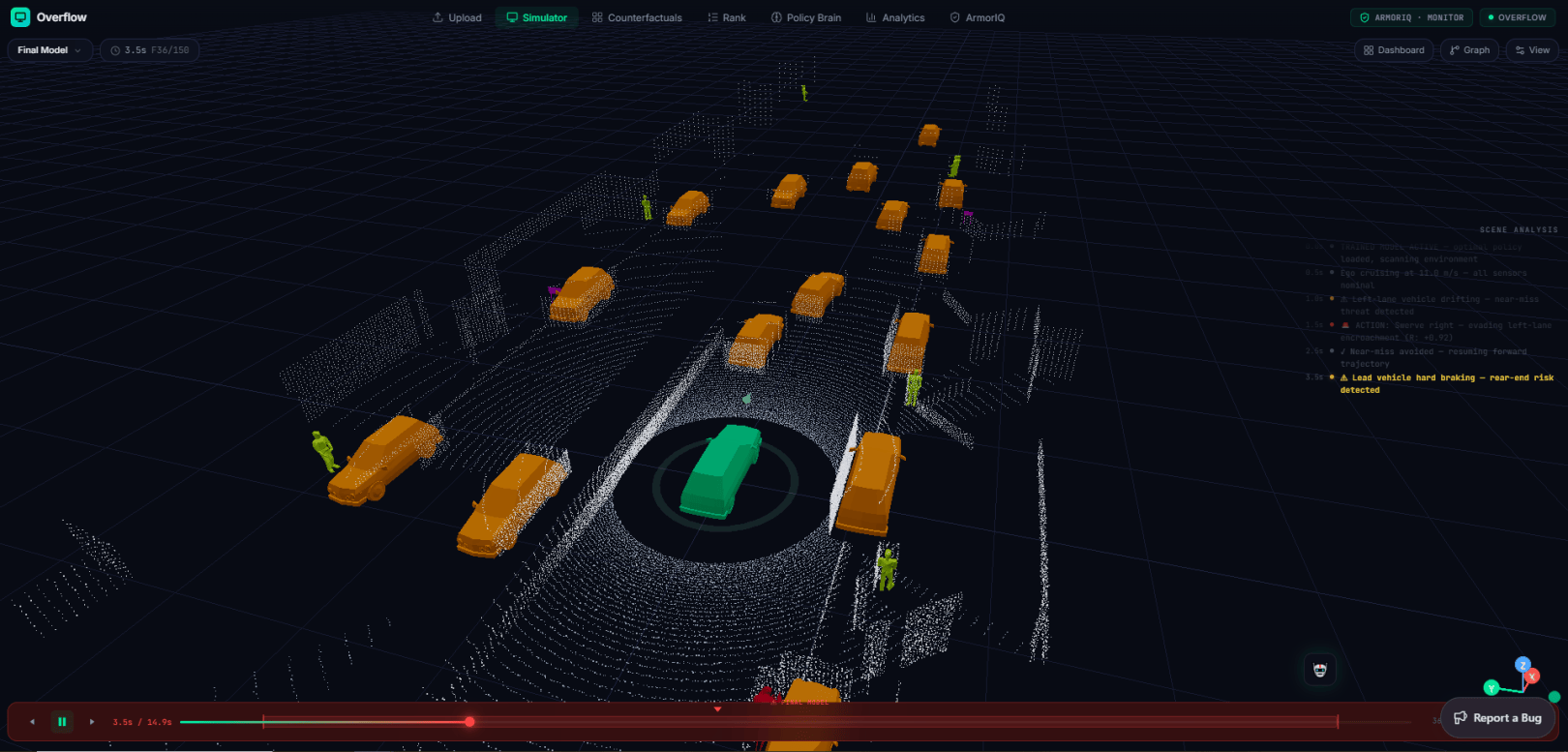
Pick a scenario — "Near Miss," "Jaywalker" — and watch the ego car drive it in 3D: live LiDAR, bounding boxes, and an Autonomy Stack panel streaming the model's actions and rewards, with an "Explain last decision" button for the reasoning behind each move. Then the counterfactuals kick in — every 10 seconds the dashboard spawns three new sims where the ego chose differently, each drawn as a top-down map of where that decision led.
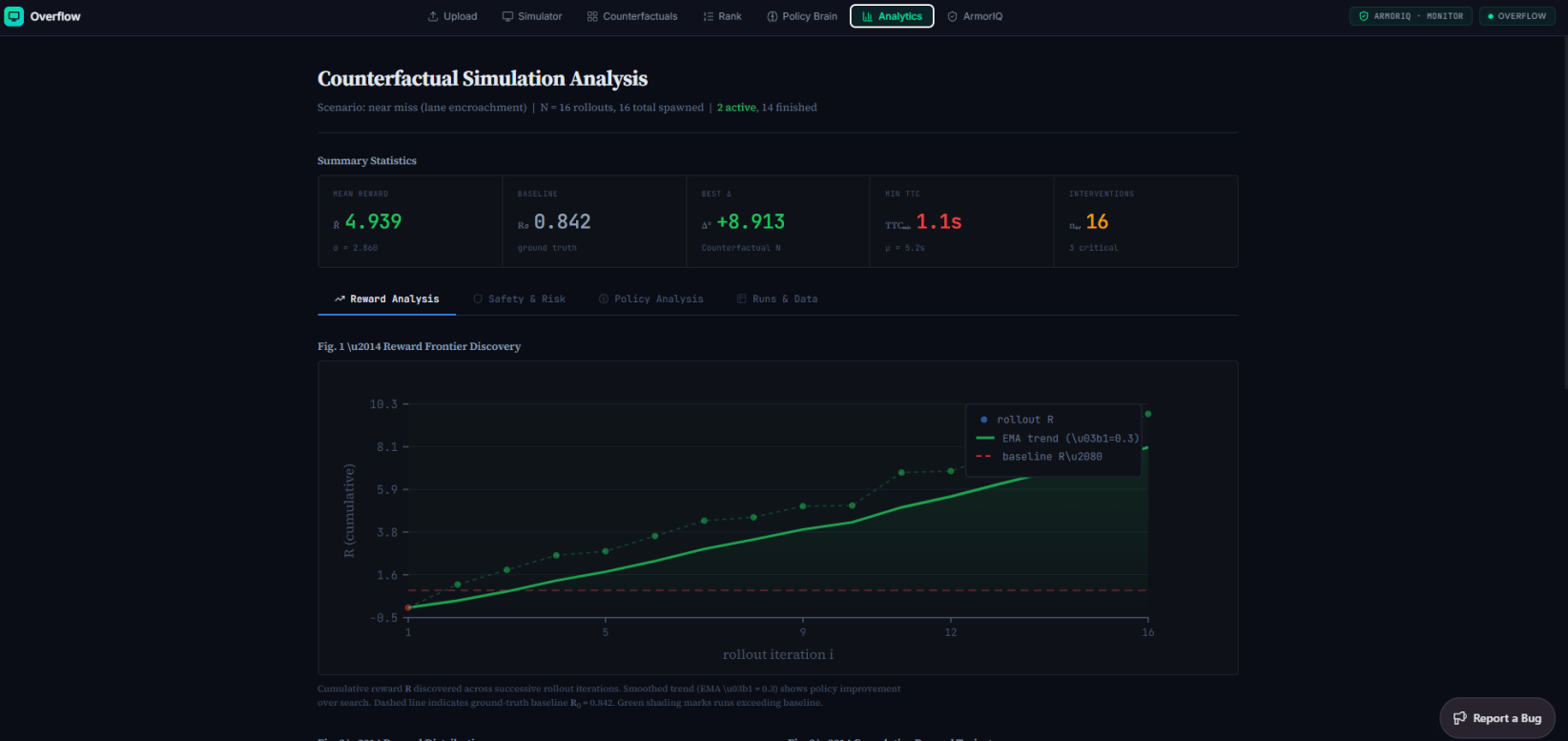
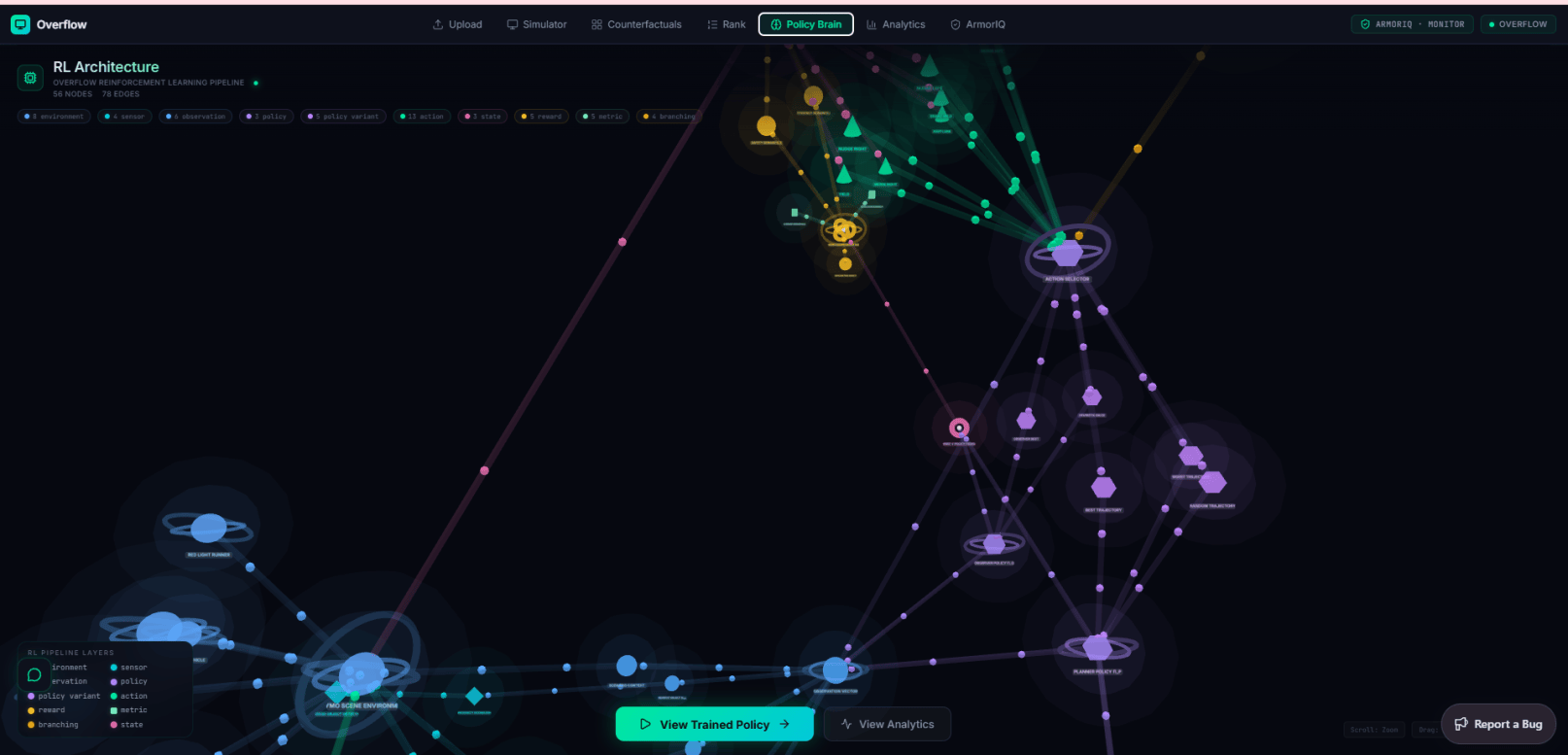
A human ranks those rollouts. A reward model learns the ranking. GRPO trains the policy against it — and the trick is that each scenario's counterfactual set is exactly the "group" GRPO needs for its baseline. A 3D knowledge graph wires every scenario, run, action, and reward together so you can trace why a decision happened, and an analytics page tracks rewards, runs, and incidents over time.
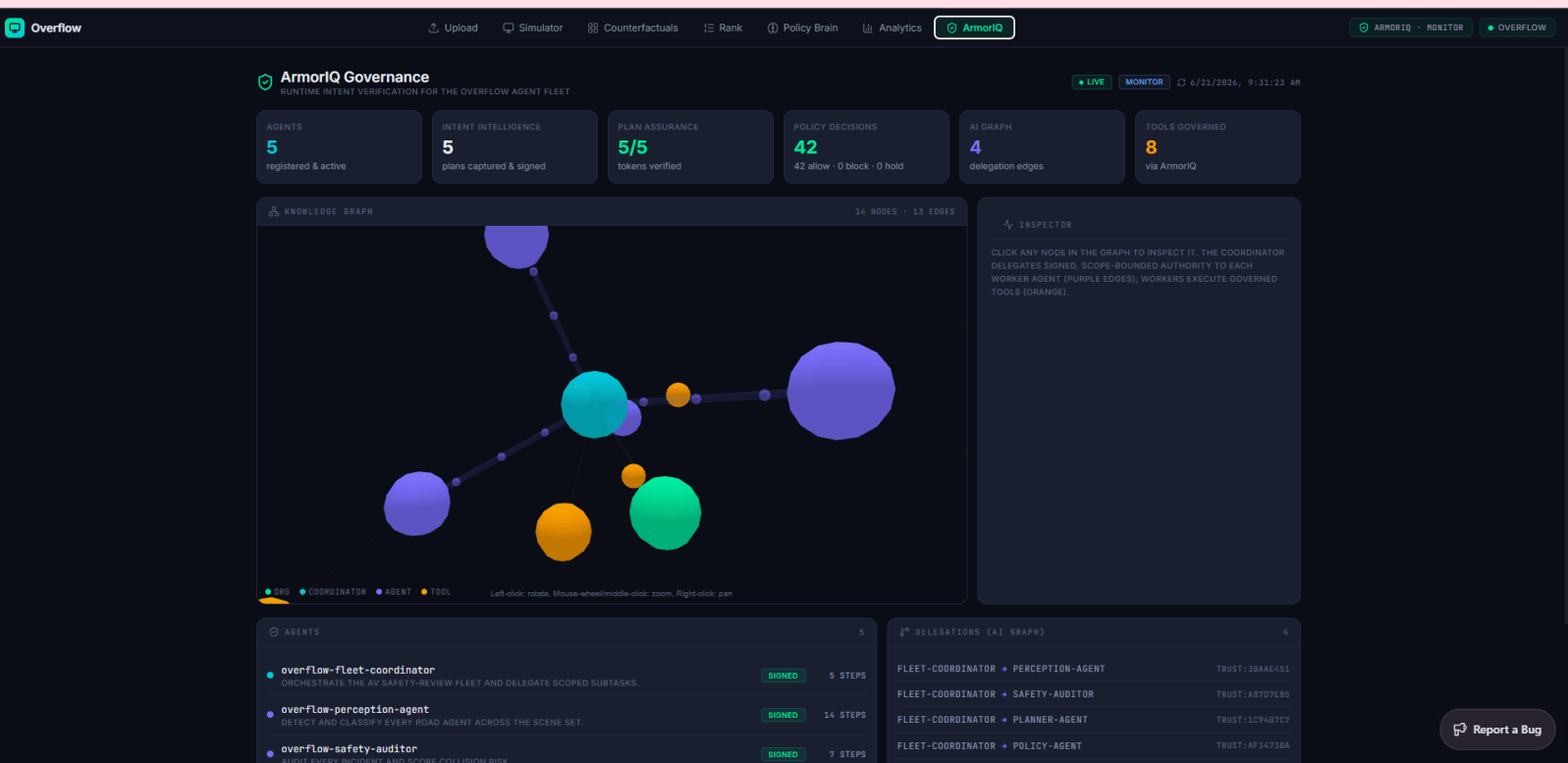
Above all of it runs a governed multi-agent safety system: perception, planner, and safety-auditor agents that coordinate in a shared room, run on a durable runtime, and operate under cryptographic intent enforcement — so the agents auditing a driving decision can't go rogue while doing it.
How we built it
Frontend. React 19, TypeScript, Vite. Three.js + React Three Fiber for the 3D sim and LiDAR, Zustand for state, react-force-graph-3d for the knowledge graph, and Hyparquet to read Waymo parquet files straight in the browser.
Backend. An Express server that proxies the OpenAI reasoning calls server-side, fully traced.
Training. A Python pipeline: a Bradley-Terry reward model over human-ranked rollouts, a GRPO trainer that uses each scene's counterfactual set as its group, and an orchestrator tying them together.
Durable agent runtime — Orkes AgentSpan. The long-running work — the counterfactual rollout fleet and the GRPO/reward-model training jobs — runs as durable workflows on AgentSpan. Execution state lives on the server, tool calls retry on failure, and if a process dies the run resumes from the exact step instead of restarting. Crucially, the human reranker is an AgentSpan human-in-the-loop approval gate: the workflow pauses with no timeout, holds state on the server, and waits for a human to rank the rollouts before training continues — exactly the primitive AgentSpan is built for.
Agent collaboration — Band. The perception, planner, and safety-auditor agents don't call each other directly. They live in a shared Band room and coordinate by @mention with deterministic (non-LLM) routing, so context stays synchronized and every exchange lands in one audit trail. If one agent misinforms another, Band's control plane catches the cascade instead of letting a bad safety verdict propagate.
Intent governance — ArmorIQ. Before the autonomous safety agent acts, ArmorIQ captures its plan, compiles it into a signed Canonical Structured Reasoning Graph, and issues a short-lived intent token with per-step cryptographic proofs. Every action is checked against that signed plan; anything that drifts outside it is blocked at the gate, fail-closed. It governs the agent by intent, not just credentials — which is what you want before an autonomous agent gets anywhere near a driving policy.
Observability — Sentry. Full-stack distributed tracing front to back, error boundaries, and performance profiling, with the backend doubling as the Sentry tunnel — so the whole system is traceable instead of a black box.
Challenges we ran into
Counterfactual realism. The instant the ego leaves the logged path, you have no ground-truth sensor data for where it went — the hardest unsolved problem in the field. We used synthetic generation to keep divergent rollouts coherent, and learned firsthand why the frontier pours money into generative world models here.
Learning the reward instead of writing it. "Good driving" is too fuzzy to hand-code without going brittle, so the whole point became learning it from human preference — building the ranking → reward-model → GRPO chain end to end and getting the signal to actually move the policy.
An intent-governance SDK that fought back. Integrating ArmorIQ surfaced real bugs in its intent-verification layer — a verifyToken() that returned true even when the signed planHash had been tampered with (an integrity hole in the exact thing the SDK exists to protect), and a delegate() that was dead against the live backend. We shipped workarounds and wrote up all eight findings with root-cause traces.
Backend from scratch, mid-hackathon. The app started frontend-only; the LLM proxy and the Sentry tunnel meant standing up a server tier under the clock.
Accomplishments that we're proud of
- The loop actually closes: log → counterfactual → human rank → GRPO → knowledge graph. Not a diagram of it — a running version.
- Four sponsor integrations that each own a real subsystem, not logos bolted on: AgentSpan runs the durable pipeline and holds the human-rank approval gate, Band is the agents' shared room and audit trail, ArmorIQ is the cryptographic intent gate on the safety agent, and Sentry is full-stack tracing across the whole thing.
- We found and documented 8 real bugs (2 high-severity) in a production intent-assurance SDK while wiring it in — with honest triage separating the SDK's faults from our own pre-existing dependencies.
- We can say exactly where we sit next to Waymo, and built the honest, transparent version of a technique the frontier keeps locked up.
What we learned
- The RLHF/GRPO playbook ports cleanly from language to driving: a scene's counterfactual rollouts are the GRPO group, and a human ranking them is the preference signal.
- AV safety is a long-tail and reward-specification problem far more than an average-driving one — both squarely in human-feedback RL's wheelhouse.
- Counterfactual realism breaks the moment trajectories diverge; reconstructive methods can't follow, which is why generative world models are the real frontier.
- Multi-agent safety is three different problems — coordination (Band), durable execution with human checkpoints (AgentSpan), and intent enforcement (ArmorIQ) — and they don't collapse into one tool.
- Humility: Waymo's world model, the open-source Waymax simulator, and Wayve's GAIA-1 are years ahead. Our edge is transparency and access, not scale.
What's next for Improving Autonomous Cars
- Real closed-loop data — swap synthetic scenes for the Waymo Open Motion Dataset via Waymax, so the counterfactuals are grounded in real driving.
- A generative world model so divergent rollouts stay realistic once the ego leaves the logged path.
- Active preference collection — surface the most informative rollouts to rank, so every human label trains the reward model harder.
- A continuous flywheel — re-rank as the policy shifts so the reward model never goes stale.
- From advisory to audit-and-veto — combine ArmorIQ's fail-closed intent gate with AgentSpan's approval checkpoints so the safety system can actually override an unsafe policy, not just flag it.
Built With
- agentspan
- armoriq
- band.ai
- nextjs
- oarkes
- openenv
- pytorch
- sentry
- trl



Log in or sign up for Devpost to join the conversation.